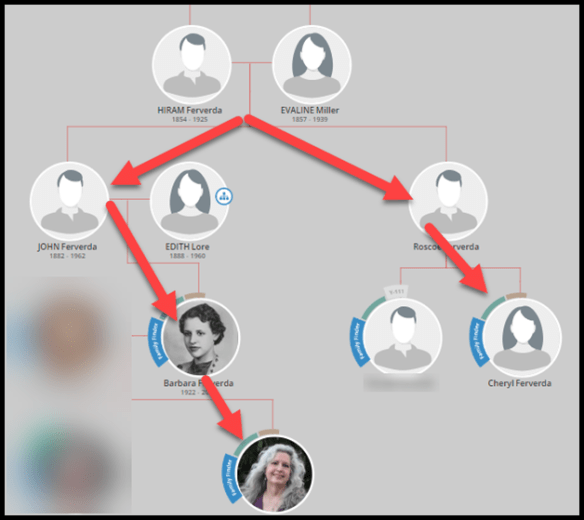
This is the third in our series of articles about searching for unknown close family members, specifically; parents, grandparents, or siblings. However, these same techniques can be applied to ancestors further back in time too.
- I introduced the series in the article, DNA: In Search of…New Series Launches.
- In the second article, DNA: In Search of…What Do You Mean I’m Not Related to My Family? – and What Comes Next?, we discussed the discovery that something was amiss, then how to make sure a vial or upload mix-up didn’t happen. That was followed by the basics of the four kinds of DNA tests you’ll be able to use to solve your mystery.
In this article, we are going to discuss your goals and why testing or uploading to multiple vendors is advantageous – even if you could potentially solve the initial mystery at one vendor. Of course, the vendor you test with first might not be the vendor where the mystery will be solved, and data from multiple vendors might just be the combination you need.
Testing Strategy – You Might Get Lucky
I recommended in the first article that you go ahead and test at the different vendors.
Some people asked why, and specifically, why you wouldn’t just test at one vendor with the largest database first, then proceed to the others if you needed to.
That’s a great question, and I want to discuss the pros and cons in this article more specifically.
Clearly, that is one strategy, but the approach you select might differ based on a variety of considerations:
- You may only be interested in obtaining the name of the person you are seeking – or – you may be interested in finding out as much as possible.
- You may find that your best match at one company is decidedly unhelpful, and may even block you or your efforts, while someone elsewhere may be exactly the opposite.
- Solving your mystery may be difficult and painful at one vendor, but the answer may be infinitely easier at a different vendor where the answer may literally be waiting.
- There may not be enough, or the right information, or matches, at any one vendor, but the puzzle may be solvable by combining information from multiple vendors and tests. Every little bit helps.
- You may have a sense of urgency, especially if you hope to meet the person and you’re searching for parents, siblings or grandparents who may be aging.
- You may be cost-sensitive and cannot afford more than one test at a time. Fortunately, our upload strategy helps with that too. Also, watch for vendor sales or bundles.
From the time you order your DNA test, it will be about 6-8 weeks, give or take a week or two in either direction, before you receive results.
When those results arrive, you might get lucky, and the answer you seek is immediately evident with no additional work and just waiting for you at the first testing company.
If that’s the case, you got lucky and hit the jackpot. If you’re searching for both parents, that means you still have one parent to go.
Unidentified grandparents can be a little more difficult, because there are four of them to sort between.
If you discover a sibling or half-sibling, you still need to figure out who your common parent is. Sometimes X, Y, and mitochondrial DNA provides an immediate answer and is invaluable in these situations.
It’s more likely that you’ll find a group of somewhat more distant relatives. You may be able to figure out who your common grandparents or great-grandparents are, but not your parent(s) initially. Often, the closer generation or two is actually the most difficult because you’re dealing with contemporary records which are not publicly available, fewer descendants, and the topic may be very uncomfortable for some people. It’s also complicated because you’re often not dealing with “full” relationships, but “half,” as in half-sibling, half-niece, half-1C, etc.
You may spend a substantial amount of time trying to solve this puzzle at the first vendor before ordering your next test.
That second test will also take about 6-8 weeks, give or take. I recommend that you order the first two autosomal tests, now.
Order Your First Two Autosomal Tests
The two testing companies with the largest autosomal databases for comparison, Ancestry, and 23andMe, DO NOT accept DNA file uploads from other companies, so you’ll need to test with each individually.
Fortunately, you CAN transfer your autosomal DNA tests to both MyHeritage and FamilyTreeDNA, for free.
You will have different matches at each company. Some people will be far more responsive and helpful than others.
I recommend that you go ahead and order both the Ancestry and 23andMe tests initially, then upload the first one that comes back with results to both FamilyTreeDNA and MyHeritage. Complete, step-by-step download/upload instructions can be found here.
You can also upload your DNA file to a fifth company, Living DNA, but they are significantly smaller and heavily focused on England and Great Britain. However, if that’s where you’re searching, this might be where you find important matches.
You can also upload to GEDMatch, a popular third-party database, but since you’re going to be in the databases of the four major testing companies, there is little to be gained at GEDMatch in terms of people who have not tested at one of the major companies. Do NOT upload to GEDMatch INSTEAD of testing or uploading to the four major sites, as GEDMatch only has a small fraction of the testers in each of the vendor databases.
What GEDMatch does offer is a chromosome browser – something that Ancestry does NOT offer, along with other clustering tools which you may find useful. I recommend GEDMatch in addition to the others, if needed or desired.
Ordering Y and Mitochondrial DNA Tests
We reviewed the basics of the different kinds of DNA, here.
Some people have asked why, if autosomal DNA shows relatives on all of your lines, would one would want to order specific tests that focus on just one line?
It just so happens that the two lines that Y and mitochondrial DNA test ARE the two lines you’re seeking – direct maternal – your mother (and her mother), and direct paternal, your father (and his father.)

These two tests are different kinds of DNA tests, testing a different type of DNA, and provide very focused information, and matches, not available from autosomal DNA tests.
For men, Y DNA can reveal your father’s surname, which can be an invaluable clue in narrowing paternal candidates. Knowing that my brother’s Y DNA matched several men with the surname of Priest made me jump for joy when he matched a woman of that same last name at another vendor.
Here’s a quote from one of the members of a Y DNA project where I’m the volunteer administrator:
“Thank you for your help understanding and using all 4 kinds of my DNA results. By piecing the parts together, I identified my father. Specifically, without Y DNA testing, and the Big Y test, I would not have figured out my parental connection, and then that my paternal line had been assigned to the wrong family. STR testing gave me the correct surname, but the Big Y test showed me exactly where I fit, and disproved that other line. I’m now in touch with my father, and we both know who our relatives are – two things that would have never happened otherwise.”
If you fall into the category of, “I want to know everything I can now,” then order both Y and mitochondrial DNA tests initially, along with those two autosomal tests.
You will need to order Y (males only) and mitochondrial DNA tests separately from the autosomal Family Finder test, although you should order on the same account as your Family Finder test at FamilyTreeDNA.
![]()
If you take the Family Finder autosomal test at FamilyTreeDNA or upload your autosomal results from another vendor, you can simply select to add the Y and mitochondrial DNA tests to your account, and they will send you a swab kit.

Conversely, you can order either a Y or mitochondrial DNA test, and then add a Family Finder or upload a DNA file if you’ve already taken an autosomal DNA test to that account too. Note – these might not be current prices – check here for sales.
You will want all 3 of your tests on the same account so that you can use the Advanced Matches feature.

Using Advanced Matches, you’ll be able to view people who match you on combinations of multiple kinds of tests.

For example, if you’re a male, you can see if your Y DNA matches also match you on the Family Finder autosomal test, and if so, how closely?
Here’s an example.

In this case, I requested matches to men with 111 markers who also match the tester on the Family Finder test. I discovered both a father and a full sibling, plus a few more distant matches. There were ten total combined matches to work with, but I’ve only shown five for illustration purposes.
This information is worth its weight in gold.
Is the Big Y Test Worth It?
People ask if the Big Y test is really worth the extra money.
The answer is, “it depends.”
If all you’re looking for are matching surnames, then the answer is probably no. A 37 or 111 marker test will probably suffice. Eventually, you’ll probably want to do the Big Y, though.
If you’re looking for exact placement on the tree, with an estimated distance to other men who have taken that test, then the answer is, “absolutely.” I wish the Big Y test had been available back when I was hunting for my brother’s biological family.
The Big Y test provides a VERY specific haplogroup and places you very accurately in your location on the Y DNA tree, along with other men of your line, assuming they have tested. You may find the surname, as well as being placed within a generation or a few of current in that family line.

Additionally, the Discover page provides estimates of how far in the past you share a common ancestor with other people that share the same haplogroup. This can be a HUGE boon to a male trying to figure out his surname line and how closely in time he’s related to his matches.
Big Y NPE Examples
Y DNA SNP mutations tested with the Big Y test accrue a mutation about every generation, or so. Sometimes we see mutations in every generation.

Here’s an example from my Campbell line. Haplogroups are listed in the top three rows.
I created this spreadsheet, but FamilyTreeDNA provides a block tree for Big Y testers. I’ve added the genealogy of the testers, with the various Big Y testers at the bottom and common ancestors above, in bold.
We have two red NPE lines showing. The MacFarlane tester matches M. Campbell VERY closely, and two Clark males match W. Campbell and other Campbells quite closely. We utilized autosomal plus the Y results to determine where the unknown parentage events occurred. Today, if you’re a Clark or MacFarlane male, or a male by any other surname who was fathered by a Y chromosome Campbell male (by any surname), you’ll know exactly where you fit in this group of testers on your direct paternal line.
Y DNA is important because men often match other men with the same surname, which is a HUGE clue, especially in combination with autosomal DNA results. I say “often,” because it’s possible that no one in your line has tested, or that your father’s surname is not his biological surname either.
Y and mitochondrial DNA matches can be HUGELY beneficial pieces of information either by confirming a close autosomal relationship on that line, or eliminating the possibility.
Lineage-Specific Population Information
In addition to matching other people, both Y and mitochondrial DNA tests provide you with lineage-specific population or “ethnicity” information for this specific line which helps you focus your research.
For example, if you view the Y DNA Haplogroup Origins shown for this tester, you’ll discover that these matches are Jewish.

The tester might not be Jewish on any other genealogical line, but they definitely have Jewish ancestry on their Y DNA, paternal, line.

The same holds true for mitochondrial DNA as well. The main difference with mitochondrial DNA is that the surname changes with each generation, haplogroups today (pre-Million Mito) are less specific, and fewer people have been tested.
Y and Mitochondrial DNA Benefits
Knowing your Y and mitochondrial DNA haplogroups not only arm you with information about yourself, they provide you with matching tools and an avenue to include or exclude people as your direct line paternal or maternal ancestors.
Your Y and mitochondrial DNA can also provide CRITICALLY IMPORTANT information about whether that direct line ancestor belonged to an endogamous population, and where they came from.
For example, both Jewish and Native populations are endogamous populations, meaning highly intermarried for many generations into the past.
Knowing that helps you adjust your autosomal relationship analysis.
Why Order Multiple Tests Initially Instead of Waiting?
If you’ve been adding elapsed time, two autosomal tests (Ancestry and 23andMe), two uploads (to FamilyTreeDNA and MyHeritage,) a Y DNA test, and a mitochondrial DNA test, if all purchased serially, one following the other, means you’ll be waiting approximately 6-8 months.
Do you want to wait 6-8 months for all of your results? Can you afford to?
Part of this answer has to do with what, exactly, you’re seeking, and how patient you are.
Only you can answer that question.
A Name or Information?
Are you seeking the name or identity of a person, or are you seeking information about that person?
Most people don’t just want to put a name to the person they are seeking – they want to learn about them and the rest of the family that door opens.
You will have different matches at each company. Even after you identify the person you seek, the people you match may have trees you can view, with family photos and other important information. (Remember, you can’t see living people in trees.) Your matches may have first-person information about your relative and may know them if they are living, or have known them.
Furthermore, you may have the opportunity to meet that person. Time delayed may not be able to be recovered or regained.
One cousin that I assisted discovered that his father had died just six weeks before he broke through that wall and made the connection.
Working with data from all vendors simultaneously will allow you to combine that data and utilize it together. Using your “best” matches at each company, augmented by X, Y, and/or mitochondrial DNA, can make MUCH shorter work of this search.
Your closest autosomal matches are the most important and insightful. In this series, I will be working with the top 15 autosomal results at each vendor, at least initially. This approach provides me with the best chance of meaningful close relationship discoveries.
Data and Vendor Results Integration
Here’s a table of my two closest maternal and paternal matches at the four major vendors. I can assign these to maternal or paternal sides, because I know the identity of my parents, and I know some of these people. If an adoptee was doing this, the top 4 could all be from one parent, which is why we work with the top 15 or so matches.
| Vendor | Closest Maternal | Closest Paternal | Comments |
| Ancestry | 1C, 1C1R | Half-1C, 2C | I recognized both of the maternal and neither of the paternal. |
| 23andMe | 2C, 2C | 1C1R, half-gr-niece | Recognized both maternal, one paternal |
| MyHeritage | Mother uploaded, 1C | Half-niece, half-1C | Recognized both maternal, one paternal |
| FamilyTreeDNA | Mother tested, 1C1R | Parent/child, half-gr-niece uploaded | Recognized all 4 |
To be clear, I tested my mother’s mitochondrial DNA before she passed away, but because FamilyTreeDNA archives DNA samples for 25 years, as the owner/manager of her DNA kit, I was able to order the Family Finder test after she had passed away. Her tests are invaluable today.
Then, years later, I uploaded her results to MyHeritage.
If I was an adopted child searching for my mother, I would find her results in both databases today. She’ll never be at either 23andMe or Ancestry because she passed away before she could test there and they don’t accept uploads.
Looking at the other vendors, my half-niece at MyHeritage is my paternal half-sibling’s daughter. My half-sibling is deceased, so this is as close as I’ll ever get to matching her.
At 23andMe, the half-great-niece is my half-siblings grandchild.
It’s interesting that I have no matches to descendants of my other half-sibling, who is also deceased. Maybe I should ask if any of his children or grandchildren have tested. Hmmmm…..
You can see that I stand a MUCH BETTER chance of figuring out close relatives using the combined closest matches of all four databases instead of the top matches from just one database. It doesn’t matter if the database is large if the right person or people didn’t test there.
Combine Resources
I’ll be providing analysis methodologies for working with results from all of the vendors together, just in case your answer is not immediately obvious. Taking multiple DNA tests facilitates using all of these tools immediately, not months later. Solving the puzzle sooner means you may not miss valuable opportunities.
You may also discover that the door slams shut with some people, or they may not respond to your queries, but another match may be unbelievably helpful. Don’t limit your possibilities.
Let’s take a look at the strengths of each vendor.
Vendor Strengths and Things to Know
Every vendor has product strengths and idiosyncracies that the others do not. All vendors provide matches and shared matches. Each vendor provides ethnicity tools which certainly can be useful, but the features differ and will be covered elsewhere.
- Ancestry – Ancestry has the largest autosomal database and includes ThruLines, but no Y or mitochondrial DNA testing, no clusters, no chromosome browser, no triangulation, and no X chromosome matching or reporting. Ancestry provides genealogical records, advanced tools, and full tree access to your matches’ trees with an Ancestry subscription. Ancestry does not allow downloading your match list or segment match information, but the other vendors do.
- 23andMe – 23andMe has the second largest database. They provide triangulation and genetic trees that include your closest matches. Many people test at 23andMe for health and wellness information, so 23andMe has people in their database who are not specifically interested in genealogy and probably won’t have tested elsewhere, but may be invaluable to your search. 23andMe provides Y and mtDNA high-level haplogroups only, but no matching or other haplogroup information. If you purchase a new test or have a V5 ancestry+health current test, you can expand your matches from a limit of 1500 to about 5000 with an annual membership. For seeking close relatives, you don’t need those features, but you may want them for genealogy. 23andMe is the only vendor that limits their customers’ matches.
- MyHeritage – MyHeritage has the third largest database that includes lots of European testers. MyHeritage provides triangulation, Theories of Family Relativity, and an integrated cluster tool* but does not report X matches and does not offer Y or mitochondrial DNA testing. MyHeritage accepts autosomal DNA file uploads from other testing companies for free and provides access to advanced DNA features for a one-time unlock fee. MyHeritage includes genealogical records and full feature access to advanced DNA tools with a Complete Subscription. (Free 15 days trial subscription, here.)
- FamilyTreeDNA Family Finder (autosomal) – FamilyTreeDNA is the oldest DNA testing company, meaning their database includes people who initially tested 20+ years ago and have since passed away. This, in essence, gets you one generation further back in time, with the possibility of stronger matches. Their Family Matching feature buckets and triangulates your matches, assigning them to your maternal or paternal sides if you link known matches to their proper place in your tree, even if your parents have not tested. FamilyTreeDNA accepts uploads from other testing companies for free and provides advanced DNA features for a one time unlock fee.
- FamilyTreeDNA – FamilyTreeDNA is the only company that offers both Y and mitochondrial DNA testing products that include matching, integration with autosomal test results, and other tools. These two tests are lineage-specific and don’t have to be sorted from your other ancestral lines.
I wrote about using Y DNA results, here.
I wrote about using mitochondrial DNA results, here.
*Third parties such as Genetic Affairs provide clustering tools for both 23andMe and FamilyTreeDNA. Clustering is integrated at MyHeritage. Ancestry does not provide a tool for nor allow third-party clustering. If the answer you seek isn’t immediately evident, Genetic Affairs clustering tools group people together who are related to each other, and you, and create both genetic and genealogical trees based on shared matches. You can read more about their tools, here.
Fish in all the Ponds and Use All the Bait Possible
Here’s the testing and upload strategy I recommend, based on the above discussion and considerations. The bottom line is this – if you want as much information as possible, as quickly as possible, order the four tests in red initially. Then transfer the first autosomal test results you receive to the two companies identified in blue. Optionally, GEDMatch may have tools you want to work with, but they aren’t a testing company.
| What | When | Ancestry | 23andMe | MyHeritage | FamilyTreeDNA |
| Order autosomal | Initially | X | X | ||
| Order Y 111 or Big-Y DNA test if male | Initially | X | |||
| Order mitochondrial DNA test | Initially if desired | X | |||
| Upload free autosomal | When Ancestry or 23andMe results are available | X | X | ||
| Unlock Advanced Tools | When you upload | $29 | $19 | ||
| Optional GEDMatch free upload | If desired, can subscribe for advanced tools |
When you upload an autosomal DNA file to a vendor site, only upload one file per site, per tester. Otherwise, multiple tests simply glom up everyone’s match list with multiple matches to the same person.
Multiple vendor sites will hopefully provide multiple close matches, which increase your opportunity to discover INFORMATION about your family, not just the identity of the person you seek.
Or maybe you prefer to wait and order these DNA tests serially, waiting until one set of results is back and you’re finished working with them before ordering the next one. If so, that means you’re a MUCH more patient person than me. 😊
Our next article in this series will be about endogamy, how to know if it applies to you, and what that means to your search.
_____________________________________________________________
Follow DNAexplain on Facebook, here or follow me on Twitter, here.
Share the Love!
You’re always welcome to forward articles or links to friends and share on social media.
If you haven’t already subscribed (it’s free,) you can receive an email whenever I publish by clicking the “follow” button on the main blog page, here.
You Can Help Keep This Blog Free
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Uploads
- FamilyTreeDNA – Y, mitochondrial, and autosomal DNA testing
- MyHeritage DNA – Autosomal DNA test
- MyHeritage FREE DNA file upload – Upload your DNA file from other vendors free
- AncestryDNA – Autosomal DNA test
- 23andMe Ancestry – Autosomal DNA only, no Health
- 23andMe Ancestry Plus Health
Genealogy Products and Services
- MyHeritage FREE Tree Builder – Genealogy software for your computer
- MyHeritage Subscription with Free Trial
- Legacy Family Tree Webinars – Genealogy and DNA classes, subscription-based, some free
- Legacy Family Tree Software – Genealogy software for your computer
- Newspapers.com – Search newspapers for your ancestors
- NewspaperArchive – Search different newspapers for your ancestors
My Book
- DNA for Native American Genealogy – by Roberta Estes, for those ordering the e-book from anyplace, or paperback within the United States
- DNA for Native American Genealogy – for those ordering the paperback outside the US
Genealogy Books
- Genealogical.com – Lots of wonderful genealogy research books
Genealogy Research
- Legacy Tree Genealogists – Professional genealogy research