

I didn’t do it. I really didn’t. Ok, I wanted to, but I didn’t.
Yes, I seriously considered exhuming my father. Ok, now that you’ve stopped gasping, let me tell you about the story, and what I did instead, and how successful it was, and wasn’t.
My father, William Sterling Estes, died in a car accident in 1963. That means he’s been dead now for 50 years, half a century. Depending on the source, he had between 2 and several children. His obituary names me as his daughter, then inadvertently mixed up my mother, his x-wife’s name with that of his sister. So my mother is listed as my father’s sister in his obit and his sister isn’t listed at all. Neither is his other daughter, my half-sister. For any of you who follow my family story, you already know it’s bizarre, so this unfortunate error should come as no surprise and would only provide Jeff Foxworthy with fodder for his “you might be….if” series.
But, as you’ll see, that obituary is part of the problem and so is the fact that he has been dead 50 years now. That’s 50 years for his DNA to degrade.
My father was, well, ahem, somewhat of a playboy. I keep finding children, and rumors of children, scattered about as I kept researching. I keep waiting for a solid half-sibling match to some poor unsuspecting person on one of these autosomal tests too. It hasn’t happened yet, but I’m just sure that one day it will.
And I haven’t published my blog article on Ilo yet, but suffice it to say that if you know of an Ilo (or maybe Flo?) who had a male child about 1920 in or near Battle Creek, Michigan and was briefly “married” to William Sterling Estes who was serving at Camp Custer at the time….I need to talk to you.
Now you’d think with all of these alleged children, there would be a male child to test, but the only male child I knew of back when DNA testing began was the male child of Ilo who I have never been able to identify, let alone locate. I hadn’t found my “brother” Dave yet at that time, but as it turned out, Dave’s DNA did not match the Estes line anyway, so that would have been a red herring.
My Estes line out of Claiborne County Tennessee, for all of the males in earlier generations, dwindled to only a few, then to none in my generation. The best I could do was a descendant of a male 3 or 4 generations upstream in my tree, and where there are paternity questions in more recent generations, a descendant from up the tree isn’t helpful, or wasn’t before autosomal testing.
Ah yes, that paternity question. You see, it wasn’t definite. A descendant tested the Y chromosome, and he was off just enough markers to be considered a problematic match. But, it was enough to introduce doubt. And doubt is a horrible nag for a companion – especially for the family genealogist who has spent the past three and a half decades working on this “doubtful” family. In other words, OMG!!! This was the genealogical equivalent of a panic attack. And what could I do? There was no one else to test.
On the chart below, the green line is the Estes ancestral line, as we know it today, proven by both genetics and genealogy. The purple is the anonymous participant that tested and had the questionable match to the green ancestral Estes line. The yellow group was then “suspect” because of the questionable match. When I found David, supposedly my father’s son, and he tested, matching neither the purple participant nor the Estes ancestral line, it nearly put me over the edge. My cousin, Buster agreed to test, which confirmed the ancestral Estes line back to Lazarus, which left the yellow still in the questionable realm. There were no living males to test in the yellow line.
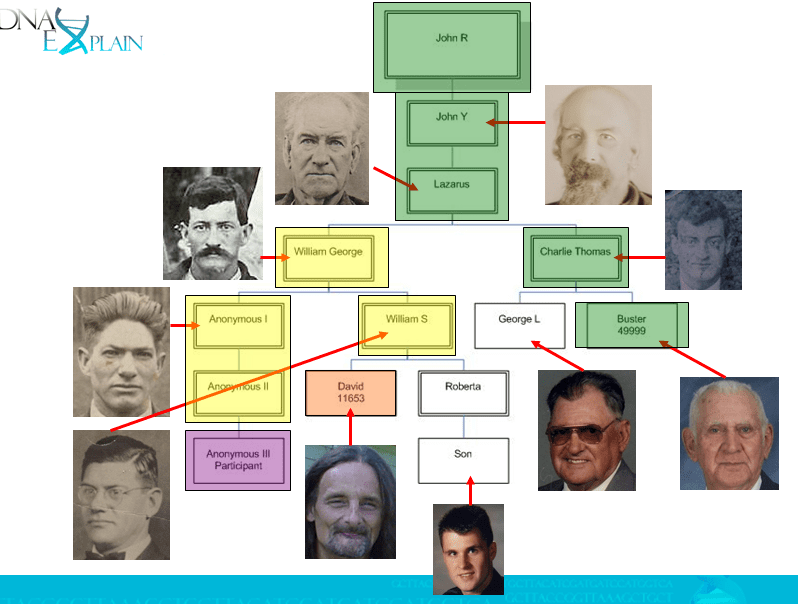
So, I considered exhuming Dad. That possible paternity issue had shaken me, pretty much to the bone, and I desperately wanted to know. Was I barking up the wrong tree? Was my Dad not my Dad, but David’s Dad? David and I clearly were not genetic half-siblings, suggested at that time by CODIS testing, but proven eventually by 23andMe testing. Was my Dad not the child of his father, William George? Was his father maybe not the child of his father, Lazarus? Why did my grandfather not look like the other Estes men? We knew that John R. Estes matched the ancestral Estes line, but we had no one else to test below John R. on the tree.
Below, my great-great-grandfather, John Y. Estes, at left, my great-grandfather, Lazarus, center and my grandfather, William George, at right.

Why did my son look so much like my father? Was I just seeing things that weren’t there? Below, my father as a teen in his military uniform and my son about the same age.

Without a male to test the Estes Y-line DNA, how would I ever know?
One day, a package arrived in the mail. My step-mother had died some years ago, and her daughter had found a group of letters in her mother’s belongings that she felt I should have. Among those letters were letters from my grandfather to my father.
Letters? Envelopes? Stamps? Saliva? DNA? JACKPOT!!! WOOHOOOO!!!!!!!
At the time my grandfather mailed those letters to my father, in the 1960s, my grandfather was living alone, so he should have licked the envelope and the stamp himself.
I called Bennett Greenspan at Family Tree DNA. He referred me to a private lab that “does things like this,” called Trace Genetics. Before you start googling, the company was subsequently sold and has now been defunct for years. However, at that time they were doing custom processing of private forensic samples.
Yes, anything like that is considered forensic. Anything you have to extract DNA from before you can have it processed in a regular lab is forensic work.
So, I got an estimate, took out a loan, and told them to go ahead. You think I’m kidding, but I’m not. The cost was in the $2000 range FOR EACH ATTEMPT. So, we tried the envelope first. No DNA. Then we tried the stamp. We got DNA, but it was female, so we knew it was contaminant DNA. Think of how many people handle an envelope in the processing and delivery of mail, not to mention all the people who had handled it since. Then we tried a second envelope. No dice.
I was beyond frustrated and so were the two wonderfully patient scientists I was working with at Trace Genetics. We all desperately wanted DNA. In all fairness, they told me very clearly up front that there was a less than 50% chance of obtaining ANY DNA, let alone usable DNA, let alone Y-line DNA. Yes, the odds were very much stacked against me, and I knew it.
Y-line DNA is the least obtainable. Most forensic work is done using mitochondrial DNA. That’s because in each cell there is a total of 1 Y chromosome and there are thousands of mitochondria. So the chances of recovering mitochondria are much greater than a Y chromosome.
Still, I had to try. If you’re thinking of the word obsessed, I certainly wouldn’t argue with you.
Then I remembered, I had my father’s VFW hat. I had it stored away in an old train case with other memorabilia from my childhood. That was the one and only thing of my father’s I ever had – that hat. I still remember him wearing it and I remember going to the VFW hall with him. They had a slot machine and sometimes he used to let me pull the arm on the machine. That was great fun.
I asked my friendly scientist at Trace Genetics what to do with the hat. He suggested that I look for hairs in the interior of the hat, under the hatband, and then he told me how to extract the hair without touching it myself using sterile gloves. I did so, put the hair in a Kleenex, put the Kleenex in an envelope and overnighted it to Trace Genetics. This hair had the all-important follicle attached, the only part of the hair that will provide DNA.
I was positive, just positive, that this time was the jackpot. But it wasn’t, and neither was the next hair.
Are you adding up the numbers in your mind? Well, I assure you, I was adding them up. And it wasn’t the money that bothered me, but the lack of results. I was devastated.

So, I considered exhumation. I looked into it, and I discovered a couple of things that were very important and were likely show-stoppers.
- In order to exhume someone, you have to petition the court and give a reason. Then, you have to obtain the written, notarized, permission from every single descendant. Yes, I said EVERY SINGLE DESCENDANT. If even one disagrees, or refuses, it’s done, a deal-killer, dead.
- The cost of said exhumation is about $20,000 including all expenses, like attorney fees, backhoe, medical examiner, etc..
Choke, sputter, cough….clutching chest….
I happened to know someone who actually did exhume their ancestor, not for DNA testing, but because the cemetery was going to wind up at the bottom of a lake. And yes, the entire process did cost in the neighborhood of 20K, a price-tag they did not anticipate in advance nor expect.
I had my doubts that any court would approve an exhumation for obtaining DNA for genealogy, but they might approve it to move the grave to Tennessee where my father’s family was buried. Dad was (and is) buried alone in Indiana.

But to move him, the cost of the exhumation would increase exponentially. Moving a body which is considered medical waste is not inexpensive. By way of comparison, to bring my sister home from Arizona to Michigan for burial was in the neighborhood of 10K. And that would have been in addition to the 20K for exhumation.
For a minute, I thought about my brother, Dave, the long haul truck driver and I wondered if he had any room in that truck between pallets of yogurt. But I got a grip on myself before asking him. I had visions of Dave putting Dad back in the sleeper cab…but I digress.
Ok, now we were talking the price of a car or a small house…a vacation home maybe or a trip around the world. And it wasn’t 2K at a time, but an all or nothing proposition.
Not only did I not have the 20K or 30K, I couldn’t justify borrowing it, so I decided to leave sleeping Dad’s lie, so to speak.
I also decided that really, while I desperately did want to know about the paternity issue and its resolution, that I’m an Estes no matter what. It’s my maiden name, it’s my name now that I’m married (I married a Kvochick, need I say more) and it will be my name on my tombstone. So, I’m an Estes no matter whether I descended from them genetically or not.
I intentionally have not addressed any moral or ethical issues about exhumation. Some feel the dead should be left alone, undisturbed. However, there is precedent… the Catholic church regularly exhumes their saints to see if the body is well preserved. I didn’t know what to think, truthfully, along those lines, and before I could have and would have actually made that decision, I would have had to think long and hard about it. Would I have been there for the exhumation? Could I have stayed away? Would I have wanted to see my father like that? All questions I would have had to answer, but did not have to, because the other issues precluded exhumation.
The first issue I would have encountered was who, exactly, were his descendants, and how, exactly, legally, was that determined? I mean, does the court go by the obituary? If so, my mother was his sister. But I had a real half-sister. Was she included? No place did it say that she was his descendant. He didn’t have a will. And what about the children we knew about but couldn’t find? Would that preclude the exhumation? Or should we just stay quiet about them? No, too many ethical issues and thorny problems, and that is BEFORE you get to the money issue.
I’m glad I didn’t slog through that mess, because before long, autosomal testing came about – not CODIS testing – which was inconclusive at best – but wide spectrum testing using hundreds of thousands of DNA positions, today’s 23andMe and Family Tree DNA’s Family Finder tests.
I have several Estes cousins who aren’t direct male lines but who who are fairly close genetically and I’m not related to any of them through any other genealogical lines. If I matched them, it would be proof positive that I indeed was a blood descendant of the Estes line. I wasn’t happy testing just one or two, so I tested 5 or 6 of my cousins from different children of my great and great-great-grandfather – and yes, I did indeed match all of them.
What a relief! I didn’t have to dig up Dad or spend the equivalent of a couple years of college education.
But for those who are indeed as desperate as I was, let me tell you the following.
- There are very few labs that will do this kind of processing. It is very unpopular as you basically have to shut the entire lab, sanitize it, and run no other tests until you are done. You can see a forensic lab clean room in Ripan Malhi’s lab at the University of Illinois.
- Best case, with a relatively recent sample, meaning one from someone who died recently, you have about a 50% chance of useable DNA retrieval. That’s BEST CASE.
- Skin is good. The best is an electric razor contents. Do NOT touch them. Put the entire razor with contents into a plastic bag and DO NOT seal it. Keep it in a temperature stable environment. No attic or basement. Sometimes hairbrushes have skin flakes in with the hair.
- Hearing aids are good. Again, do not touch, etc. Blood is good. Spit is good. A Kleenex is wonderful, providing you are sure it is their Kleenex. If your mother was like my mother, check her bathrobe pockets.
- Older things like hair, sweat, envelopes etc. are not so good. The older the sample, the less likely you’ll be able to retrieve DNA. It degrades with time and these aren’t particularly good to begin with.
- Digging up a grave without doing all of the paperwork is illegal, and the legalities vary by locality – so consult an attorney and get the check book ready. I just thought I should mention that little illegal detail, just in case. I know genealogists are innovative and sometimes desperate people.
Having said all of that, don’t go throwing anything away. There is new technology on the horizon that will only need one cell of DNA – so I’m told. Seeing how far we’ve come in the past decade, I don’t doubt that someday this will be true, and someday may be closer than you think. And no, I do not know how far away that horizon is.
So, store your DNA item safely. Label it. Do not seal it in plastic. Do not store it in the attic (heat) or basement (cold, humidity) but someplace fairly temperature regulated.
One time when working with an archaeological specimen, we were told to freeze the sample. Well, we did, in a plastic cool-whip container with water. However, the electricity went out while the person whose freezer the specimen was stored in was out of town. Their friend went to their house and did them the very big favor of disposing of everything in the fridge and freezer before they came home. Needless to say, we were just sick. So, don’t freeze it either. Besides that, freezing in a frost-free refrigerator (that by definition defrosts itself regularly) is not the same as freezing a specimen in a laboratory temperature controlled stable environment.
So, what’s the upshot of this?
- Forensic genetics is expensive
- Exhumations are extremely expensive and fraught with all kinds of legal and technical landmines
- There are very few labs, if any, that will process private forensic samples
- When DNA is retrieved from a forensic specimen, it may be contaminant, not the DNA of the person you think it belongs to
- When DNA is retrieved from a forensic specimen, you still have to pay for the DNA testing, in addition – and it may not work
- When DNA is retrieved from a forensic specimen, if it does amplify, it will most likely be mitochondrial DNA
- Using today’s combined genetic genealogy tests, there is almost always a way around the lack of a particular DNA donor, making exhumation and or forensic testing unnecessary
And if you’re considering grabbing a shovel, an urge which I well understand, I’ll leave you with the advice of an ethicist that Family Tree DNA invited to speak at their annual conference a few years ago, “Don’t do anything in the dark of night that you wouldn’t do in the middle of the day.” Put another way, don’t do anything you wouldn’t be comfortable seeing in the headlines, because if you get caught, that’s where you’ll be:)
But then again, those headlines would certainly be something interesting for future generations of genealogists to dig up about you!
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research

















{kind=link}