One of my readers asked why we don’t use close relatives for triangulation.
This is a great question because not using close relatives for triangulation seems counter-intuitive.
I used to ask my kids and eventually my students and customers if they wanted the quick short answer or the longer educational answer.
The short answer is “because close relatives are too close to reliably form the third leg of the triangle.” Since you share so much DNA with close relatives, someone matching you who is identical by chance can also match them for exactly the same reason.
If you trust me and you’re good with that answer, wonderful. But I hope you’ll keep reading because there’s so much to consider, not to mention a few gotchas. I’ll share my methodology, techniques, and workarounds.
We’ll also discuss absolutely wonderful ways to utilize close relatives in the genetic genealogical process – just not for triangulation.
At the end of this article, I’ve provided a working triangulation checklist for you to use when evaluating your matches.
Let’s go!
The Step-by-Step Educational Answer😊
Some people see “evidence” they believe conflicts with the concept that you should not use close relatives for triangulation. I understand that, because I’ve gone down that rathole too, so I’m providing the “educational answer” that explains exactly WHY you should not use close relatives for triangulation – and what you should do.
Of course, we need to answer the question, “Who actually are close relatives?”
I’ll explain the best ways to best utilize close relatives in genetic genealogy, and why some matches are deceptive.
You’ll need to understand the underpinnings of DNA inheritance and also of how the different vendors handle DNA matching behind the scenes.
The purpose of autosomal DNA triangulation is to confirm that a segment is passed down from a particular ancestor to you and a specific set of your matches.
Triangulation, of course, implies 3, so at least three people must all match each other on a reasonably sized portion of the same DNA segment for triangulation to occur.
Matching just one person only provides you with one path to that common ancestor. It’s possible that you match that person due to a different ancestor that you aren’t aware of, or due to chance recombination of DNA.
It’s possible that your or your match inherited part of that DNA from your maternal side and part from your paternal side, meaning that you are matching that other person’s DNA by chance.
I wrote about identical by descent (IBD), which is an accurate genealogically meaningful match, and identical by chance (IBC) which is a false match, in the article Concepts – Identical by…Descent, State, Population and Chance.
I really want you to understand why close relatives really shouldn’t be used for triangulation, and HOW close relative matches should be used, so we’re going to discuss all of the factors that affect and influence this topic – both the obvious and little-understood.
- Legitimate Matches
- Inheritance and Triangulation
- Parental Cross-Matching
- Parental Phasing
- Automatic Phasing at FamilyTreeDNA
- Parental Phasing Caveats
- Pedigree Collapse
- Endogamy
- How Many Identical-by-Chance Matches Will I Have?
- DNA Doesn’t Skip Generations (Seriously, It Doesn’t)
- Your Parents Have DNA That You Don’t (And How to Use It)
- No DNA Match Doesn’t Mean You’re Not Related
- Imputation
- Ancestry Issues and Workarounds
- Testing Close Relatives is VERY Useful – Just Not for Triangulation
- Triangulated Matches
- Building Triangulation Evidence – Ingredients and a Recipe
- Aunts/Uncles
- Siblings
- How False Positives Work and How to Avoid Them
- Distant Cousins Are Best for Triangulation & Here’s Why
- Where Are We? A Triangulation Checklist for You!
- The Bottom Line
Don’t worry, these sections are logical and concise. I considered making this into multiple articles, but I really want it in one place for you. I’ve created lots of graphics with examples to help out.
Let’s start by dispelling a myth.
DNA Doesn’t Skip Generations!
Recently, someone emailed to let me know that they had “stopped listening to me” in a presentation when I said that if a match did not also match one of your parents, it was a false match. That person informed me that they had worked on their tree for three years at Ancestry and they have “proof” of DNA skipping generations.
Nope, sorry. That really doesn’t happen, but there are circumstances when a person who doesn’t understand either how DNA works, or how the vendor they are using presents DNA results could misunderstand or misinterpret the results.
You can watch my presentation, RootsTech session, DNA Triangulation: What, Why and How, for free here. I’m thrilled that this session is now being used in courses at two different universities.
DNA really doesn’t skip generations. You CANNOT inherit DNA that your parents didn’t have.
Full stop.
Your children cannot inherit DNA from you that you don’t carry. If you don’t have that DNA, your children and their descendants can’t have it either, at least not from you. They of course do inherit DNA from their other parent.
I think historically, the “skipping generations” commentary was connected to traits. For example, Susie has dimples (or whatever) and so did her maternal grandmother, but her mother did not, so Susie’s dimples were said to have “skipped a generation.” Of course, we don’t know anything about Susie’s other grandparents, if Susie’s parents share ancestors, recessive/dominant genes or even how many genetic locations are involved with the inheritance of “dimples,” but I digress.
DNA skipping generations is a fallacy.
You cannot legitimately match someone that your parent does not, at least not through that parent’s side of the tree.
But here’s the caveat. You can’t match someone one of your parents doesn’t with the rare exception of:
- Relatively recent pedigree collapse that occurs when you have the same ancestors on both sides of your tree, meaning your parents are related, AND
- The process of recombination just happened to split and recombine a segment of DNA in segments too small for your match to match your parents individually, but large enough when recombined to match you.
We’ll talk about that more in a minute.
However, the person working with Ancestry trees can’t make this determination because Ancestry doesn’t provide segment information. Ancestry also handles DNA differently than other vendors, which we’ll also discuss shortly.
We’ll review all of this, but let’s start at the beginning and explain how to determine if our matches are legitimate, or not.
Legitimate Matches
Legitimate matches occur when the DNA of your ancestor is passed from that ancestor to their descendants, and eventually to you and a match in an unbroken pathway.
Unbroken means that every ancestor between you and that ancestor carried and then passed on the segment of the ancestor’s DNA that you carry today. The same is true for your match who carries the same segment of DNA from your common ancestor.
False positive matches occur when the DNA of a male and female combine randomly to look like a legitimate match to someone else.
Thankfully, there are ways to tell the difference.
Inheritance and Triangulation
Remember, you inherit two copies of each of your chromosomes 1-22, one copy from your mother and one from your father. You inherit half of the DNA that each parent carries, but it’s mixed together in you so the labs can’t readily tell which nucleotide, A, C, T, or G you received from which parent. I’m showing your maternal and paternal DNA in the graphic below, stacked neatly together in a column – but in reality, it could be AC in one position and CA in the next.
For matching all that matters is the nucleotide that matches your match is present in one of those two locations. In this case, A for your mother’s side and C for your father’s side. If you’re interested, you can read more about that in the article, Hit a Genealogy Home Run Using Your Double-Sided Two-Faced Chromosomes While Avoiding Imposters.

You can see in this example that you inherited all As from your Mom and all Cs from your Dad.
- A legitimate maternal match would match you on all As on this particular example segment.
- A legitimate paternal match would match you on all Cs on this particular segment.
- A false positive match will match you on some random combination of As and Cs that make it look like they match you legitimately, but they don’t.
- A false positive match will NOT match either your mother or your father.
To be very clear, technically a false positive match DOES match your DNA – but they don’t match your DNA because you share a common ancestor with your match. They match you because random recombination on their side causes you to match each other by chance.
In other words, if part of your DNA came from your Mom’s side and part from your Dad’s but it randomly fell in the correct positional order, you’d still match someone whose DNA was from only their mother or father’s side. That’s exactly the situation shown above and below.

Looking at our example again, it’s evident that your identical by chance (IBC) match’s A locations (1, 3, 5, 7 & 9) will match your Mom. C locations (2, 4, 6 8, & 10) will match your Dad, but the nonmatching segments interleaved in-between that match alternating parents will prevent your match from matching either of your parents. In other words, out of 10 contiguous locations in our example, your IBC match has 5 As alternated with 5 Cs, so they won’t match either of your parents who have 10 As or 10 Cs in a row.
This recombination effect can work in either direction. Either or both matching people’s DNA could be randomly mixed causing them to match each other, but not their parents.
Regardless of whose DNA is zigzagging back and forth between maternal and paternal, the match is not genealogical and does not confirm a common ancestor.
This is exactly why triangulation works and is crucial.
If you legitimately match a third person, shown below, on your maternal side, they will match you, your first legitimate maternal match, and your Mom because they carry all As. But they WON’T match the person who is matching you because they are identical by chance, shown in grey below.
The only person your identical by chance match matches in this group is you because they match you because of the chance recombination of parental DNA.

That third person WILL also match all other legitimate maternal matches on this segment.
In the graphic above, we see that while the grey identical by chance person matches you because of the random combination of As from your mother and Cs from your father, your legitimate maternal matches won’t match your identical by chance match.
This is the first step in identifying false matches.
Parental Cross-Matching

Removing the identical by chance match, and adding in the parents of your legitimate maternal match, we see that your maternal match, above, matches you because you both have all As inherited from one parent, not from a combination of both parents.
We know that because we can see the DNA of both parents of both matches in this example.
The ideal situation occurs when two people match and they have both had their parents tested. We need to see if each person matches the other person’s parents.

We can see that you do NOT match your match’s father and your match does NOT match your father.
You do match your match’s mother and your match does match your mother. I refer to this as Parental Cross-matching.
Your legitimate maternal matches will also match each other and your mother if she is available for testing.

All the people in yellow match each other, while the two parents in gray do not match any of your matches. An entire group of legitimate maternal matches on this segment, no matter how many, will all match each other.
If another person matches you and the other yellow people, you’ll still need to see if you match their parents, because if not, that means they are matching you on all As because their two parents DNA combined just happened, by chance, to contribute an A in all of those positions.

In this last example, your new match, in green, matches you, your legitimate match and both of your mothers, BUT, none of the four yellow people match either of the new match’s parents. You can see that the new green match inherited their As from the DNA of their mother and father both, randomly zigzagging back and forth.
The four yellow matches phase parentally as we just proved with cross matching to parents. The new match at first glance appears to be a legitimate match because they match all of the yellow people – but they aren’t because the yellow people don’t match the green person’s parents.
To tell the difference between legitimate matches and identical by chance matches, you need two things, in order.
- Parental matching known as parental phasing along with parental cross-matching, if possible, AND
- Legitimate identical by descent (IBD) triangulated matches
If you have the ability to perform parental matching, called phasing, that’s the easiest first step in eliminating identical by chance matches. However, few match pairs will have parents for everyone. You can use triangulation without parental phasing if parents aren’t available.
Let’s talk about both, including when and how close relatives can and cannot be used.
Parental Phasing
The technique of confirming your match to be legitimate by your match also matching one of your parents is called parental phasing.
If we have the parents of both people in a match pair available for matching, we can easily tell if the match does NOT match either parent. That’s Parental Cross Matching. If either match does NOT match one of the other person’s parents, the match is identical by chance, also known as a false positive.
See how easy that was!
If you, for example, is the only person in your match pair to have parents available, then you can parentally phase the match on your side if your match matches your parents. However, because your match’s parents are unavailable, your match to them cannon tbe verified as legitimate on their side. So you are not phased to their parents.
If you only have one of your parents available for matching, and your match does not match that parent, you CANNOT presume that because your match does NOT match that parent, the match is a legitimate match for the other, missing, parent.
There are four possible match conditions:
- Maternal match
- Paternal match
- Matches neither parent which means the match is identical by chance meaning a false positive
- Matches both parents in the case of pedigree collapse or endogamy
If two matching people do match one parent of both matches (parental cross-matching), then the match is legitimate. In other words, if we match, I need to match one of your parents and you need to match one of mine.
It’s important to compare your matches’ DNA to generationally older direct family members such as parents or grandparents, if that’s possible. If your grandparents are available, it’s possible to phase your matches back another generation.
Automatic Phasing at FamilyTreeDNA
FamilyTreeDNA automatically phases your matches to your parents if you test that parent, create or upload a GEDCOM file, and link your test and theirs to your tree in the proper places.

FamilyTreeDNA‘s Family Matching assigns or “buckets” your matches maternally and paternally. Matches are assigned as maternal or paternal matches if one or both parents have tested.
Additionally, FamilyTreeDNA uses triangulated matches from other linked relatives within your tree even if your parents have not tested. If you don’t have your parents, the more people you identify and link to your tree in the proper place, the more people will be assigned to maternal and paternal buckets. FamilyTreeDNA is the only vendor that does this. I wrote about this process in the article, Triangulation in Action at Family Tree DNA.
Parental Phasing Caveats
There are very rare instances where parental phasing may be technically accurate, but not genealogically relevant. By this, I mean that a parent may actually match one of your matches due to endogamy or a population level match, even if it’s considered a false positive because it’s not relevant in a genealogical timeframe.
Conversely, a parent may not match when the segment is actually legitimate, but it’s quite rare and only when pedigree collapse has occurred in a very specific set of circumstances where both parents share a common ancestor.
Let’s take a look at that.
Pedigree Collapse
It’s not terribly uncommon in the not-too-distant past to find first cousins marrying each other, especially in rather closely-knit religious communities. I encounter this in Brethren, Mennonite and Amish families often where the community was small and out-marrying was frowned upon and highly discouraged. These families and sometimes entire church congregations migrated cross-country together for generations.
When pedigree collapse is present, meaning the mother and father share a common ancestor not far in the past, it is possible to inherit half of one segment from Mom and the other half from Dad where those halves originated with the same ancestral couple.
For example, let’s say the matching segment between you and your match is 12 cM in length, shown below. You inherited the blue segment from your Dad and the neighboring peach segment from Mom – shown just below the segment numbers. You received 6 cM from both parents.

Another person’s DNA does match you, shown in the bottom row, but they are not shown on the DNA match list of either of your parents. That’s because the DNA segments of the parents just happened to recombine in 6 cM pieces, respectively, which is below the 7 cM matching threshold of the vendor in this example.
If the person matched you at 12 cM where you inherited 8 cM from one parent and 4 from the other, that person would show on one parent’s match list, but not the other. They would not be on the parent’s match list who contributed only 4 cM simply because the DNA divided and recombined in that manner. They would match you on a longer segment than they match your parent at 8 cM which you might notice as “odd.”
Let’s look at another example.

click to enlarge image
If the matching segment is 20 cM, the person will match you and both of your parents on different pieces of the same segment, given that both segments are above 7 cM. In this case, your match who matches you at 20 cM will match each of your parents at 10 cM.
You would be able to tell that the end location of Dad’s segment is the same as the start location of Mom’s segment.
This is NOT common and is NOT the “go to” answer when you think someone “should” match your parent and does not. It may be worth considering in known pedigree collapse situations.
You can see why someone observing this phenomenon could “presume” that DNA skipped a generation because the person matches you on segments where they don’t match your parent. But DNA didn’t skip anything at all. This circumstance was caused by a combination of pedigree collapse, random division of DNA, then random recombination in the same location where that same DNA segment was divided earlier. Clearly, this sequence of events is not something that happens often.
If you’ve uploaded your DNA to GEDmatch, you can select the “Are your parents related?” function which scans your DNA file for runs of homozygosity (ROH) where your DNA is exactly the same in both parental locations for a significant distance. This suggests that because you inherited the exact same sequence from both parents, that your parents share an ancestor.

If your parents didn’t inherit the same segment of DNA from both parents, or the segment is too short, then they won’t show as “being related,” even if they do share a common ancestor.
Now, let’s look at the opposite situation. Parental phasing and ROH sometimes do occur when common ancestors are far back in time and the match is not genealogically relevant.
Endogamy
I often see non-genealogical matching occur when dealing with endogamy. Endogamy occurs when an entire population has been isolated genetically for a long time. In this circumstance, a substantial part of the population shares common DNA segments because there were few original population founders. Much of the present-day population carries that same DNA. Many people within that population would match on that segment. Think about the Jewish community and indigenous Americans.

Consider our original example, but this time where much of the endogamous population carries all As in these positions because one of the original founders carried that nucleotide sequence. Many people would match lots of other people regardless of whether they are a close relative or share a distant ancestor.
People with endogamous lines do share relatives, but that matching DNA segment originated in ancestors much further back in time. When dealing with endogamy, I use parental phasing as a first step, if possible, then focus on larger matches, generally 20 cM or greater. Smaller matches either aren’t relevant or you often can’t tell if/how they are.
At FamilyTreeDNA, people with endogamy will find many people bucketed on the “Both” tab meaning they triangulate with people linked on both sides of the tester’s tree.

An example of a Jewish person’s bucketed matches based on triangulation with relatives linked in their tree is shown above.
Your siblings, their children, and your children will be related on both your mother’s and father’s sides, but other people typically won’t be unless you have experienced either pedigree collapse where you are related both maternally and paternally through the same ancestors or you descend from an endogamous population.
How Many Identical-by-Chance Matches Will I Have?
If you have both parents available to test, and you’re not dealing with either pedigree collapse or endogamy, you’ll likely find that about 15-20% of your matches don’t match your parents on the same segment and are identical by chance.
With endogamy, you’ll have MANY more matches on your endogamous lines and you’ll have some irrelevant matches, often referred to as “false positive” matches even though they technically aren’t, even using parental phasing.
Your Parents Have DNA That You Don’t
Sometimes people are confused when reviewing their matches and their parent’s match to the same person, especially when they match someone and their parent matches them on a different or an additional segment.
If you match someone on a specific segment and your parents do not, that’s a false positive FOR THAT SEGMENT. Every segment has its own individual history and should be evaluated individually. You can match someone on two segments, one from each parent. Or three segments, one from each parent and one that’s identical by chance. Don’t assume.
Often, your match will match both you and your parent on the same segment – which is a legitimate parentally phased match.
But what if your match matches your parent on a different segment where they don’t match you? That’s a false positive match for you.
Keep in mind that it is possible for one of your matches to match your parent on a separate or an additional segment that IS legitimate. You simply didn’t inherit that particular segment from your parent.
That’s NOT the same situation as someone matching you that does NOT match one of your parents on the same segment – which is an identical by chance or false match.
Your parent having a match that does not match you is the reverse situation.
I have several situations where I match someone on one segment, and they match my parent on the same segment. Additionally, that person matches my parent on another segment that I did NOT inherit from that parent. That’s perfectly normal.
Remember, you only inherit half of your parent’s DNA, so you literally did NOT inherit the other half of their DNA. Your mother, for example, should have twice as many matches as you on her side because roughly half of her matches won’t match you.
That’s exactly why testing your parents and close family members is so critical. Their matches are as valid and relevant to your genealogy as your own. The same is true for other relatives, such as aunts and uncles with whom you share ALL of the same ancestors.
You need to work with your family member’s matches that you don’t share.
No DNA Match Doesn’t Mean You’re Not Related
Some people think that not matching someone on a DNA test is equivalent to saying they aren’t related. Not sharing DNA doesn’t mean you’re not related.
People are often disappointed when they don’t match someone they think they should and interpret that to mean that the testing company is telling them they “aren’t related.” They are upset and take issue with this characterization. But that’s not what it means.
Let’s analyze this a bit further.
First, not sharing DNA with a second cousin once removed (2C1R) or more distant does NOT mean you’re NOT related to that person. It simply means you don’t share any measurable DNA ABOVE THE VENDOR THRESHOLD.
All known second cousins match, but about 10% of third cousins don’t match, and so forth on up the line with each generation further back in time having fewer cousins that match each other.
If you have tested close relatives, check to see if that cousin matches your relatives.
Second, it’s possible to match through the “other” or unexpected parent. I certainly didn’t think this would be the case in my family, because my father is from Appalachia and my mother’s family is primarily from the Netherlands, Germany, Canada, and New England. But I was wrong.
All it took was one German son that settled in Appalachia, and voila, a match through my mother that I surely thought should have been through my father’s side. I have my mother’s DNA and sure enough, my match that I thought should be on my father’s side matches Mom on the same segment where they match me, along with several triangulated matches. Further research confirmed why.
I’ve also encountered situations where I legitimately match someone on both my mother’s and father’s side, on different segments.
Third, imputation can be important for people who don’t match and think they should. Imputation can also cause matching segment length to be overreported.
Ok, so what’s imputation and why do I care?
Imputation
Every DNA vendor today has to use some type of imputation.
Let me explain, in general, what imputation is and why vendors use it.
Over the years, DNA processing vendors who sell DNA chips to testing companies have changed their DNA chips pretty substantially. While genealogical autosomal tests test about 700,000 DNA locations, plus or minus, those locations have changed over time. Today, some of these chips only have 100,000 or so chip locations in common with chips either currently or previously utilized by other vendors.
The vendors who do NOT accept uploads, such as 23andMe or Ancestry, have to develop methods to make their newest customers on their DNA processing vendor’s latest chip compatible with their first customer who was tested on their oldest chip – and all iterations in-between.
Vendors who do accept transfers/uploads from other vendors have to equalize any number of vendors’ chips when their customers upload those files.
Imputation is the scientific way to achieve this cross-platform functionality and has been widely used in the industry since 2017.
Imputation, in essence, fills in the blanks between tested locations with the “most likely” DNA found in the human population based on what’s surrounding the blank location.
Think of the word C_T. There are a limited number of letters and words that are candidates for C_T. If you use the word in a sentence, your odds of accuracy increase dramatically. Think of a genetic string of nucleotides as a sentence.
Imputation can be incorrect and can cause both false positive and false negative matches.
For the most part, imputation does not affect close family matches as much as more distant matches. In other words, imputation is NOT going to cause close family members not to match.
Imputation may cause more distant family members not to match, or to have a false positive match when imputation is incorrect.
Imputation is actually MUCH less problematic than I initially expected.
The most likely effect of imputation is to cause a match to be just above or below the vendor threshold.
How can we minimize the effects of imputation?
- Generally, the best result will be achieved if both people test at the same vendor where their DNA is processed on the same chip and less imputation is required.
- Upload the results of both people to both MyHeritage and FamilyTreeDNA. If your match results are generally consistent at those vendors, imputation is not a factor.
- GEDmatch does not use imputation but attempts to overcome files with low overlapping regions by allowing larger mismatch areas. I find their matches to be less accurate than at the various vendors.
Additionally, Ancestry has a few complicating factors.
Ancestry Issues
AncestryDNA is different in three ways.
- Ancestry doesn’t provide segment information so it’s impossible to triangulate or identify the segment or chromosome where people match. There is no chromosome browser or triangulation tool.
- Ancestry down-weights and removes some segments in areas where they feel that people are “too matchy.” You can read Ancestry’s white papers here and here.
These “personal pileup regions,” as they are known, can be important genealogically. In my case, these are my mother’s Acadian ancestors. Yes, this is an endogamous population and also suffers from pedigree collapse, but since this is only one of my mother’s great-grandparents, this match information is useful and should not be removed.
- Ancestry doesn’t show matches in common if the shared segments are less than 20cM. Therefore, you may not see someone on a shared match list with a relative when they actually are a shared match.

If two people both match a third person on less than a 20 cM segment at Ancestry, the third person won’t appear on the other person’s shared match list. So, if I match John Doe on 19 cM of DNA, and I looked at the shared matches with my Dad, John Doe does NOT appear on the shared match list of me and my Dad – even though he is a match to both of us at 19 cM.
The only way to determine if John Doe is a shared match is to check my Dad’s and my match list individually, which means Dad and I will need to individually search for John Doe.
Caveat here – Ancestry’s search sometimes does not work correctly.
Might someone who doesn’t understand that the shared match list doesn’t show everyone who shares DNA with both people presume that the ancestral DNA of that ancestor “skipped a generation” because John Doe matches me with a known ancestor, and not Dad on our shared match list? I mean, wouldn’t you think that a shared match would be shown on a tab labeled “Shared Matches,” especially since there is no disclaimer?
Yes, people can be forgiven for believing that somehow DNA “skipped” a generation in this circumstance, especially if they are relatively inexperienced and they don’t understand Ancestry’s anomalies or know that they need to or how to search for matches individually.
Even if John Doe does match me and Dad both, we still need to confirm that it’s on the same segment AND it’s a legitimate match, not IBC. You can’t perform either of these functions at Ancestry, but you can elsewhere.
Ancestry WorkArounds
To obtain this functionality, people can upload their DNA files for free to both FamilyTreeDNA and MyHeritage, companies that do provide full shared DNA reporting (in common with) lists of ALL matches and do provide segment information with chromosome browsers. Furthermore, both provide triangulation in different ways.
Matching is free, but an inexpensive unlock is required at both vendors to access advanced tools such as Family Matching (bucketing) and triangulation at Family Tree DNA and phasing/triangulation at MyHeritage.
I wrote about Triangulation in Action at FamilyTreeDNA, here.
MyHeritage actually brackets triangulated segments for customers on their chromosome browser, including parents, so you get triangulation and parental phasing at the same time if you and your parent have both tested or uploaded your DNA file to MyHeritage. You can upload, for free, here.

In this example, my mother is matching to me in red on the entire length of chromosome 18, of course, and three other maternal cousins triangulate with me and mother inside the bracketed portion of chromosome 18. Please note that if any one of the people included in the chromosome browser comparison do not triangulate, no bracket is drawn around any others who do triangulate. It’s all or nothing. I remove people one by one to see if people triangulate – or build one by one with my mother included.
I wrote about Triangulation in Action at MyHeritage, here.
People can also upload to GEDmatch, a third-party site. While GEDmatch is less reliable for matching, you can adjust your search thresholds which you cannot do at other vendors. I don’t recommend routinely working below 7 cM. I occasionally use GEDmatch to see if a pedigree collapse segment has recombined below another vendor’s segment matching threshold.
Do NOT check the box to prevent hard breaks when selecting the One-to-One comparison. Checking that box allows GEDmatch to combine smaller matching segments into mega-segments for matching.

I wrote about Triangulation in Action at GEDmatch, here.
Transferring/Uploading Your DNA
If you want to transfer your DNA to one of these vendors, you must download the DNA file from one vendor and upload it to another. That process does NOT remove your DNA file from the vendor where you tested, unless you select that option entirely separately.
I wrote full step-by-step transfer/upload instructions for each vendor, here.
Testing Close Relatives Is VERY Useful – Just Not for Triangulation
Of course, your best bet if you don’t have your parents available to test is to test as many of your grandparents, great-aunts/uncles, aunts, and uncles as possible. Test your siblings as well, because they will have inherited some of the same and some different segments of DNA from your parents – which means they carry different pieces of your ancestors’ DNA.
Just because close relatives don’t make good triangulation candidates doesn’t mean they aren’t valuable. Close relatives are golden because when they DO share a match with you, you know where to start looking for a common ancestor, even if your relative matches that person on a different segment than you do.
Close relatives are also important because they will share pieces of your common ancestor’s DNA that you don’t. Their matches can unlock the answers to your genealogy questions.
Ok, back to triangulation.
Triangulated Matches
A triangulated match is, of course, when three people all descended from a common ancestor and match each other on the same segment of DNA.
That means all three people’s DNA matches each other on that same segment, confirming that the match is not by chance, and that segment did descend from a common ancestor or ancestral couple.
But, is this always true? You’re going to hate this answer…
“It depends.”
You knew that was coming, didn’t you! 😊
It depends on the circumstances and relationships of the three people involved.
- One of those three people can match the other two by chance, not by descent, especially if two of those people are close relatives to each other.
- Identical by chance means that one of you didn’t inherit that DNA from one single parent. That zigzag phenomenon.
- Furthermore, triangulated DNA is only valid as far back as the closest common ancestor of any two of the three people.
Let’s explore some examples.
Building Triangulation Evidence – Ingredients and a Recipe
The strongest case of triangulation is when:
- You and at least two additional cousins match on the same segment AND
- Descend through different children of the common ancestral couple
Let’s look at a valid triangulated match.

In this first example, the magenta segment of DNA is at least partially shared by four of the six cousins and triangulates to their common great-grandfather. Let’s say that these cousins then match with two other people descended from different children of their great-great-great-grandparents on this same segment. Then the entire triangulation group will have confirmed that segment’s origin and push the descent of that segment back another two generations.
These people all coalesce into one line with their common great-grandparents.
I’m only showing 3 generations in this triangulated match, but the concept is the same no matter how many generations you reach back in time. Although, over time, segments inherited from any specific ancestor become smaller and smaller until they are no longer passed to the next generation.
In this pedigree chart, we’re only tracking the magenta DNA which is passed generation to generation in descendants.
Eventually, of course, those segments become smaller and indistinguishable as they either aren’t passed on at all or drop below vendor matching thresholds.

This chart shows the average amount of DNA you would carry from each generational ancestor. You inherit half of each parent’s DNA, but back further than that, you don’t receive exactly half of any ancestor’s DNA in any generation. Larger segments are generally cut in two and passed on partially, but smaller segments are often either passed on whole or not at all.
On average, you’ll carry 7 cM of your eight-times-great-grandparents. In reality, you may carry more or you may not carry any – and you are unlikely to carry the same segment as any random other descendants but we know it happens and you’ll find them if enough (or the right) descendants test.
Putting this another way, if you divide all of your approximate 7000 cM of DNA into 7 cM segments of equal length – you’ll have 1000 7 cM segments. So will every other descendant of your eight-times-great-grandparent. You can see how small the chances are of you both inheriting that same exact 7 cM segment through ten inheritance/transmission events, each. Yet it does happen.
I have several triangulated matches with descendants of Charles Dodson and his wife, Anne through multiple of their 9 (or so) children, ten generations back in my tree. Those triangulated matches range from 7-38 cM. It’s possible that those three largest matches at 38 cM could be related through multiple ancestors because we all have holes in our trees – including Anne’s surname.

Click to enlarge image
It helps immensely that Charles Dodson had several children who were quite prolific as well.
Of course, the further back in time, the more “proof” is necessary to eliminate other unknown common ancestors. This is exactly why matching through different children is important for triangulation and ancestor confirmation.
The method we use to confirm the common ancestor is that all of the descendants who match the tester on the same segment all also match each other. This greatly reduces the chances that these people are matching by chance. The more people in the triangulation group, the stronger the evidence. Of course, parental phasing or cross-matching, where available is an added confirmation bonus.
In our magenta inheritance example, we saw that three of the males and one of the females from three different descendants of the great-grandparents all carry at least a portion of that magenta segment of great-grandpa’s DNA.
Now, let’s take a look at a different scenario.
Why can’t siblings or close relatives be used as two of the three people needed for triangulation?
Aunts and Uncles
We know that the best way to determine if a match is valid is by parental phasing – your match also matching to one of your parents.
If both parents aren’t available, looking for close family matches in common with your match is the next hint that genealogists seek.
Let’s say that you and your match both match your aunt or uncle in common or their children.

You and your aunts or uncles matching DNA only pushes your common ancestor back to your grandparents.
At that point, your match is in essence matching to a segment that belongs to your grandparents. Your matches’ DNA, or your grandparents’ DNA could have randomly recombined and you and your aunt/cousins could be matching that third person by chance.
Ok, then, what about siblings?
Siblings
The most recent common ancestor (MRCA) of you and someone who also matches your sibling is your parents. Therefore, you and your sibling actually only count as one “person” in this scenario. In essence, it’s the DNA of your parent(s) that is matching that third person, so it’s not true triangulation. It’s the same situation as above with aunts/uncles, except the common ancestor is closer than your grandparents.
The DNA of your parents could have recombined in both siblings to look like a match to your match’s family. Or vice versa. Remember Parental Cross-Matching.
If you and a sibling inherited EXACTLY the same segment of your Mom’s and Dad’s DNA, and you match someone by chance – that person will match your sibling by chance as well.

In this example, you can see that both siblings 1 and 2 inherited the exact same segments of DNA at the same locations from both of their parents.
Of course, they also inherited segments at different locations that we’re not looking at that won’t match exactly between siblings, unless they are identical twins. But in this case, the inherited segments of both siblings will match someone whose DNA randomly combined with green or magenta dots in these positions to match a cross-section of both parents.
How False Positives Work and How to Avoid Them
We saw in our first example, displayed again above, what a valid triangulated match looks like. Now let’s expand this view and take a look more specifically at how false positive matches occur.
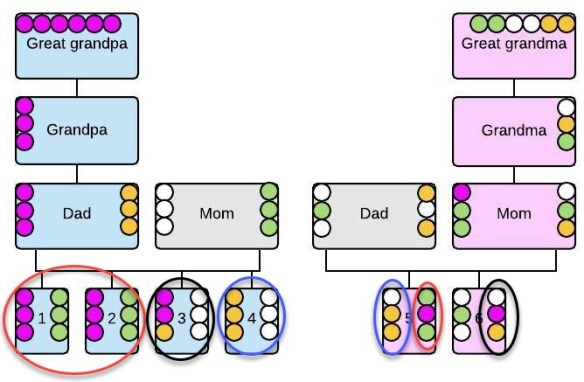
On the left-hand (blue) side of this graphic, we see four siblings that descend through their father from Great-grandpa who contributed that large magenta segment of DNA. That segment becomes reduced in descendants in subsequent generations.
In downstream generations, we can see gold, white and green segments being added to the DNA inherited by the four children from their ancestor’s spouses. Dad’s DNA is shown on the left side of each child, and Mom’s on the right.
- Blue Children 1 and 2 inherited the same segments of DNA from Mom and Dad. Magenta from Dad and green from Mom.
- Blue Child 3 inherited two magenta segments from Dad in positions 1 and 2 and one gold segment from Dad in position 3. They inherited all white segments from Mom.
- Blue Child 4 inherited all gold segments from Dad and all white segments from Mom.
The family on the blue left-hand side is NOT related to the pink family shown at right. That’s important to remember.
I’ve intentionally constructed this graphic so that you can see several identical by chance (IBC) matches.
Child 5, the first pink sibling carries a white segment in position 1 from Dad and gold segments in positions 2 and 3 from Dad. From Mom, they inherited a green segment in position 1, magenta in position 2 and green in position 3.
IBC Match 1 – Looking at the blue siblings, we see that based on the DNA inherited from Pink Child 5’s parents, Pink Child 5 matches Blue Child 4 with white, gold and gold in positions 1-3, even though they weren’t inherited from the same parent in Blue Child 4. I circled this match in blue.
IBC Match 2 – Pink Child 5 also matches Blue Children 1 and 2 (red circles) because Pink Child 5 has green, magenta, and green in positions 1-3 and so do Blue Children 1 and 2. However, Blue Children 1 and 2 inherited the green and magenta segments from Mom and Dad respectively, not just from one parent.
Pink Child 5 matches Blue Children 1, 2 and 4, but not because they match by descent, but because their DNA zigzags back and forth between the blue children’s DNA contributed by both parents.
Therefore, while Pink Child 5 matches three of the Blue Children, they do not match either parent of the Blue Children.
IBC Match 3 – Pink Child 6 matches Blue Child 3 with white, magenta and gold in positions 1-3 based on the same colors of dots in those same positions found in Blue Child 3 – but inherited both paternally and maternally.
You can see that if we had the four parents available to test, that none of the Pink Children would match either the Blue Children’s mother or father and none of the Blue Children would match either of the Pink Children’s mother or father.
This is why we can’t use either siblings or close family relatives for triangulation.
Distant Cousins Are Best for Triangulation & Here’s Why
When triangulating with 3 people, the most recent common ancestor (MRCA) intersection of the closest two people is the place at which triangulation turns into only two lines being compared and ceases being triangulation. Triangle means 3.
If siblings are 2 of the 3 matching people, then their parents are essentially being compared to the third person.
If you, your aunt/uncle, and a third person match, your grandparents are the place in your tree where three lines converge into two.
The same holds true if you’re matching against a sibling pair on your match’s side, or a match and their aunt/uncle, etc.
The further back in your tree you can push that MRCA intersection, the more your triangulated match provides confirming evidence of a common ancestor and that the match is valid and not caused by random recombination.
That’s exactly what the descendants of Charles Dodson have been able to do through triangulation with multiple descendants from several of his children.
It’s also worth mentioning at this point that the reason autosomal DNA testing uses hundreds/thousands of base pairs in a comparison window and not 3 or 6 dots like in my example is that the probability of longer segments of DNA simply randomly matching by chance is reduced with length and SNP density which is the number of SNP locations tested within that cM range.
Hence a 7 cM/500 SNP minimum is the combined rule of thumb. At that level, roughly half of your matches will be valid and half will be identical by chance unless you’re dealing with endogamy. Then, raise your threshold accordingly.
Ok, So Where are We? A Triangulation Checklist for You!
I know this has been a relatively long educational article, but it’s important to really understand that testing close relatives is VERY important, but also why we can’t effectively use them for triangulation.
Here’s a handy-dandy summary matching/triangulation checklist for you to use as you work through your matches.
- You inherit half of each of your parents’ DNA. There is no other place for you to obtain or inherit your DNA. There is no DNA fairy sprinkling you with DNA from another source:)
- DNA does NOT skip generations, although in occasional rare circumstances, it may appear that this happened. In this situation, it’s incumbent upon you, the genealogist, to PROVE that an exception has occurred if you really believe it has. Those circumstances might be pedigree collapse or perhaps imputation. You’ll need to compare matches at vendors who provide a chromosome browser, triangulation, and full shared match list information. Never assume that you are the exception without hard and fast proof. We all know about assume, right?
- Your siblings inherit half of your parents’ DNA too, but not the same exact half of your parent’s DNA that you other siblings did (unless they are identical twins.) You may inherit the exact same DNA from either or both of your parents on certain segments.
- Your matches may match your parents on different or an additional segment that you did not inherit.
- Every segment has an individual history. Evaluate every matching segment separately. One matching segment with someone could be maternal, one paternal, and one identical by chance.
- You can confirm matches as valid if your match matches one of your parents, and you match one of your match’s parents. Parental Phasing is when your match matches your parent. Parental Cross-Matching is when you both match one of each other’s parents. To be complete, both people who match each other need to match one of the parents of the other person. This rule still holds even if you have a known common ancestor. I can’t even begin to tell you how many times I’ve been fooled.
- 15-20% (or more with endogamy) of your matches will be identical by chance because either your DNA or your match’s DNA aligns in such a way that while they match you, they don’t match either of your parents.
- Your siblings, aunts, and uncles will often inherit the same DNA as you – which means that identical by chance matches will also match them. That’s why we don’t use close family members for triangulation. We do utilize close family members to generate common match hints. (Remember the 20 cM shared match caveat at Ancestry)
- While your siblings, aunts, and uncles are too close to use for triangulation, they are wonderful to identify ancestral matches. Some of their matches will match you as well, and some will not because your close family members inherited segments of your ancestor’s DNA that you did not. Everyone should test their oldest family members.
- Triangulate your close family member’s matches separately from your own to shed more light on your ancestors.
- Endogamy may interfere with parental phasing, meaning you may match because you and/or your match may have inherited some of the same DNA segment(s) from both sides of your tree and/or more DNA than might otherwise be expected.
- Pedigree collapse needs to be considered when using parental phasing, especially when the same ancestor appears on both sides of your family tree. You may share more DNA with a match than expected.
- Conversely, with pedigree collapse, your match may not match your parents, or vice versa, if a segment happens to have recombined in you in a way that drops the matching segments of your parents beneath the vendor’s match threshold.
- While you will match all of your second cousins, you will only match approximately 90% of your third cousins and proportionally fewer as your relationship reaches further back in time.
- Not being a DNA match with someone does NOT mean you’re NOT related to them, unless of course, you’re a second cousin (2C) or closer. It simply means you don’t carry any common ancestral segments above vendor thresholds.
- At 2C or closer, if you’re not a DNA match, other alternative situations need to be considered – including the transfer/upload of the wrong person’s DNA file.
- Imputation, a scientific process required of vendors may interfere with matching, especially in more distant relatives who have tested on different platforms.
- Imputation artifacts will be less obvious when people are more closely related, meaning closer relatives can be expected to match on more and larger segments and imputation errors make less difference.
- Imputation will not cause close relatives, meaning 2C or closer, to not match each other.
- In addition to not supporting segment matching information, Ancestry down-weights some segments, removes some matching DNA, and does not show shared matches below 20cM, causing some people to misinterpret their lack of common matches in various ways.
- To resolve questions about matching issues at Ancestry, testers can transfer/upload their DNA files to MyHeritage, FamilyTreeDNA, and GEDmatch and look for consistent matches on the same segment. Start and end locations may vary to some extent between vendors, but the segment size should be basically in the same location and roughly the same size.
- GEDmatch does not use imputation but allows larger non-matching segments to combine as a single segment which sometimes causes extremely “generous” matches. GEDmatch matching is less reliable than FamilyTreeDNA or MyHeritage, but you can adjust the matching thresholds.
- The best situation for matching is for both people to test at the same vendor who supports and provides segment data and a chromosome browser such as 23andMe, FamilyTreeDNA, or MyHeritage.
- Siblings cannot be used for triangulation because the most recent common ancestor (MRCA) between you and your siblings is your parents. Therefore, the “three” people in the triangulation group is reduced to two lines immediately.
- Uncles and aunts should not be used for triangulation because the most recent common ancestors between you and your aunts and uncles are your grandparents.
- Conversely, you should not consider triangulating with siblings and close family members of your matches as proof of an ancestral relationship.
- A triangulation group of 3 people is only confirmation as far back as when two of those people’s lines converge and reach a common ancestor.
- Identical by chance (IBC) matching occurs when DNA from the maternal and paternal sides are mixed positionally in the child to resemble a maternal/paternal side match with someone else.
- Identical by chance DNA admixture (when compared to a match) could have occurred in your parents or grandparent’s generation, or earlier, so the further back in time that people in a triangulation group reach, the more reliable the triangulation group is likely to be.
- The larger the segments and/or the triangulation group, the stronger the evidence for a specific confirmed common ancestor.
- Early families with a very large number of descendants may have many matching and triangulated members, even 9 or 10 generations later.
- While exactly 50% of each ancestor’s DNA is not passed in each generation, on average, you will carry 7 cM of your ancestors 10 generations back in your tree. However, you may carry more, or none.
- The percentage of matching descendants decreases with each generation beyond great-grandparents.
- The ideal situation for triangulation is a significant number of people, greater than three, who match on the same reasonably sized segment (7 cM/500 SNP or larger) and descend from the same ancestor (or ancestral couple) through different children whose spouses in descendant generations are not also related.
- This means that tree completion is an important factor in match/triangulation reliability.
- Triangulating through different children of the ancestral couple makes it significantly less likely that a different unknown common ancestor is contributing that segment of DNA – like an unknown wife in a descendant generation.
Whew!!!
The Bottom Line
Here’s the bottom line.
- Don’t use close relatives to triangulate.
- Use parents for Parental Phasing.
- Use Parental Cross-Matching when possible.
- Use close relatives to look for shared common matches that may lead to triangulation possibilities.
- Triangulate your close relatives’ DNA in addition to your own for bonus genealogical information. They will match people that you don’t.
- For the most reliable triangulation results, use the most distant relatives possible, descended through different children of the common ancestral couple.
- Keep this checklist of best practices, cautions, and caveats handy and check the list as necessary when evaluating the strength of any match or triangulation group. It serves as a good reminder for what to check if something seems “off” or unusual.
Feel free to share and pass this article (and checklist) on to your genealogy buddies and matches as you explain triangulation and collaborate on your genealogy.
Have fun!!!
_____________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
Genealogy Products and Services
Books
Genealogy Research