Charles Dodson (1649-1706) of Richmond County, Virginia was married to a woman named Ann. That much we know, positively.
The first actual record we have of Ann is found with the birth of her son, Thomas.
The North Farnham Parish register tells us that Thomas Dodson was born to Charles and Ann Dodson on May 15, 1681.
Thomas is the only child attributed to Charles and Ann in the North Farnham Parish church records, which are known to be incomplete. In this case, they are quite incomplete.
Ann is still married to Charles at his death and is named as his executrix in early 1705/1706. Charles’ will lists all of their children, including a son named Charles Jr.
Charles Jr. first appears in the records in 1693 as a witness. This suggests strongly that he is age 21 at that time, which would put his birth in approximately 1672. Charles Jr. is also named after Charles Sr., typical for a first son, and he is also listed first in the deeds when his father conveys land on the same day to both Charles Jr. and Thomas in 1702/03.
Even if Charles Jr. is only 16 instead of 21 when he witnessed the two transactions in 1693, his first appearance in county records, that would put his birth no later than 1677.
Presuming that Ann is also the mother of Charles Jr., that means that Ann and Charles Sr. were probably married by 1671 if Charles Jr. was born in 1672, or perhaps they married slightly earlier. They couldn’t have married much earlier, given their ages.
We know from a deposition in 1699 that Charles Sr. was about 50 years of age at that time, putting his birth about 1649.
It stands to reason that Ann would have been born about the same time, or subtracting 20 years from her first child’s birth, about 1652. This meshes nicely with Charles Sr.’s age as well, so I think we can presume that 1671 marriage date is approximately accurate.
Obviously, given all this effort to figure Ann’s birth year, we have no other information about when she was born.
Ann’s Parents
When I first started Dodson research, Ann’s parents were always recorded as unknown. Then, in the past few years, I saw in several locations, including several Ancestry Trees and now WikiTree as well as FamilySearch where Ann was recorded as Ann Elmore, daughter of Peter Elmore.
At first, I was quite excited, especially when I found something that appeared to be relatively well-researched at Family Search – but appearances can be quitey deceiving.
Here’s the entry for Peter Elmore from FamilySearch.



Known Issues
I’m not an Elmore researcher, but I am a Dodson researcher and I don’t want to leave the above information in print without mentioning the known issues with the information, highlighted in red, as follows:
- There is no indication that I can find where Charles Dodson Sr’s wife, who was remarried to John Hill, died on August 1, 1715. However, Charles Dodson Jr. wrote his will on July 8, 1715 and it was probated on May 1, 1716.
- Ann Dodson, wife of Charles Dodson Jr., whose surname is unknown, had her will probated in court on March 4, 1718/1719. Of course to make the situation more confusing both Charles Dodson Sr. and Jr. had wifes with unknown surnames named Ann. Of course, Ann Dodson Hill would have been named Ann Hill in 1718/1719 since she was married to John Hill and had been for more than a decade.
- There is no record that Ann Elmore married Charles Dodson in 1678 in Rappahannock County, or anyplace.
- There is no shred of evidence that Charles Dodson’s parents were Jesse Dodson and Judith Hagar.
- There is no evidence that Charles Dodson was born in Rappahannock County, although a deposition in 1799 does state that that he is about 50 years old.
- There is no evidence that Charles Dodson was christened in 1650 or that his christening, whenever it was, was in Rappahannock County.
- Charles Dodson Sr. did not sign his will on July 8, 1680, but on January 11, 1702/1703.
- However, a deed was registered between Peter Elmore and Charles Dodson on July 7, 1680.
- Charles Dodson Sr. died between October 4, 1705 and February 6, 1705/1706 when his will was probated, not in 1704/1705.
- Charles Dodson Jr. was not born in or about 1679, because he is witnessing deeds in 1693. He was probably born about 1672.
- Other than Charles and Thomas Dodson, there is no indication in the Dodson research when the other children of Charles and Ann Dodson were born. Researchers simply have to fit them into the child-bearing years of Ann, around Charles and Thomas.
- According to Charles Dodson’s will in combination with church and other records, there is no daughter Mary. Charles Dodson Jr. had a daughter Mary born in 1715, several years after Charles Dodson Sr. has died.
Even with the above incorrect information, this is the best information I could find on the Elmore family and how Ann Elmore was thought to be Charles Dodson’s wife. Hopefully the Elmore information is more accurate than the Dodson information.
Is Ann Dodson the daughter of Peter Elmore?
I couldn’t keep the Elmore information straight, so I created this abbreviated tree to track the various Peter Elmores, according to the FamilySearch information.

Peter Elmore proves a bit confusing, because in 1686, the following deed was filed.
Old Rappahannock Co Deed Book 7 – 1686 -1688; pg 306-307
I Wm. Thacker of the County of Lancaster do give William Mathews of the County of Rappa: one Cow Calfe black marked on the right eare with a crop and a slit and the left eare slitt down the midle with the one halfe of her encrease to him his heires and assignes from me my heires forever or from any persons that shall lay claim by me the abovesd Mathews being Son to Mr Wm. Mathews deceased of the Parish of Farnham of the County aforesaid. Peter Elmore being Father in Law to the abovesd Mathews is obliged to see it recorded and to have the other halfe of the encrease of the sd Cow for to looke after them as Witness my hand this 9th day of January 1683/6
Teste Charles Dodson, Wm. Thacker
John Mills marke of
Recordr. in Cur Com Rappa 23d die Martii 1686/7
A Yearling Heifer pide with black and white to be recorded with all her female encrease for Frans: Elmore marked as followeth: Crop in the right eare and a hole and under keeled on the same on the left
Record Cur Com Rappa 23 Marchy 1686/7
Father-in-law in this context probably means step-father, especially given the reference to Frances Elmore, above, and a birth recorded in 1674. Other records from this same time period in this county use the words “father in law” to mean father by law or the person we term as a step-father today.
The only Peter Elmores old enough to be the Peter in the 1686 deed are either Peter Elmore born in 1627 or his son Peter born in 1643.
The Registers of North Farnham Parish 1663-1814 and Lunenburg Parish 1783-1800 Richmond County, Virginia Compiled and Published by George Harrison Sanford King 1966 show:
Elmore, Anne daughter of Peter and Frances Elmore, Aug 29, 1674
Peter, born in 1643, is the only Peter of the age to be having a child, Ann, in 1674, given that his father, Peter born in 1627 is married to Jane and (supposedly) already has a daughter, Ann.
If in fact there was an Ann Elmore born to Peter Elmore Sr., we now have a second, younger Ann Elmore who was born in 1674, shown on the chart below. This younger Ann Elmore is clearly not the wife of Charles Dodson who is having children with his wife Ann at the time the younger Ann Elmore is born in 1674.

Deed Book Page 348 Sept 1, 1675 – I Thomas Dusin give grant and make over Anne Elmore the daughter of Peter Elmore and Frances his wife one yearling heifer…to her the said Ann Ellmore her heirs and assigns forever. Signed with mark, witness Peter Calvin and John Ingo
A year after Anne’s birth, Thomas Dusin, for some reason, gives her a one yearling heifer.
Deed Book Page 278 – July 10, 1679 between Peter Elmore of Rappae County, planter and Charles Dodson, same, planter, and his heirs and assignes, as much plantable land as 3 tithables can tend in corn and tabb, with privilege of leaving out for partuidge and further that said Dodson shall have the privilege of coopers and carpenters timber for the use of ye plantation for the term of 19 years from date hereof. (Further the said Elmore doth engage to furnish ye said Dodson with apple trees and peach trees suffichant to make an orchard both of apples and peaches) and further at the expiration of ye said terms the said Dodson is to leave a 30 foot dwelling house and a 50 foot tobacco house tennentable with all fencing in repairs that is at the expiration of the time. An further ye said Dodson to pay ye said Peter Elmore 50 pounds tobacco yearly during he said terme but if said Dodson chance to leave ye said plantation before the expiration of the said time that then ye said Peter Elmore shall have ye refusal before any other.
Signed Peter Elmore with mark and Charles Dodson. Witness William Smoote and Charles Wilson. Looks like it was registered July 7, 1680.
I’m almost positive that this transaction is why Ann Dodson, wife of Charles, is believed to be Ann Elmore, daughter of Peter. I must admit, this transaction, because of its rather strange nature, makes me wonder the same thing. However, if this were a deed to a daughter, one would think that it would not revert to Peter Elmore after 19 years. This is not a gift, but a business arrangement.
Unfortunately, because land isn’t conveyed, we really can’t say for sure whether this is Peter Elmore Sr. or Peter Elmore Jr., because Peter’s wife is not required to sign a release of her dower.
Deed Book Page 282 April 24, 1680 – Henry Dawson to Peter Elmore right in a bill of sale. Witnessed by William Dawson and Charles Dodson
Charles Dodson clearly does have a close relationship with Peter Elmore. Unfortunately, we really don’t know why. Are they just close neighbors, or is there something more? If they are related, keep in mind that we don’t know who Charles Dodson’s parents are, who Peter Elmore’s parents are, who Jane Elmore’s parents are nor who Ann Dodson’s parents are. So if they are actually related, it could be through any of those individuals in any capacity.
Deed Book Page 310 – May 30, 1681 John Harding to Jane Elmore, daughter of Peter Elmore one black cow yearling. Signed with mark. Witness Charles Dodson and Jane Ellmore (signed with mark)
Given that this 1681 deed is witnessed by Jane Ellmore, she surely must be the daughter of the elder Peter Elmore, not the Peter Jr. born in 1643.

Deed Book Page 151 November 1684 – Mr Colston, I should desire you to record for Ann Elmore my eldest daughter two cowes with calves by their sides with all their increase and in soe doeing shall obleig. Signed Peter Elmore by mark
And likewise one cowe and calfe to be between my two youngest sons with their increase. Signed Peter Elmore by mark
And likewise a black heifer of 2 years to William Mathews my son-in-law with all her increase Signed Peter Elmore by mark
This deed executed in November 1684 provides us with even more information about Peter Elmore Jr. This has to be Peter Elmore Jr. because he refers to William Matthews, so this Ann Elmore is the Ann born in 1674.
The close relationship between Charles Dodson and Peter Elmore continues, as we see by the following transactions.
Will Book Jan. 29, 1686/87 Edward Johnson will, Charles Dodson executor, Peter Elmore witness.
Court Order Book March 2, 1686/7 page 15 Ordered Richard White, William Smoote, Peter Elmore or any 2 of them do sometime between this and the next court meet to inventory and appraise the estate of Edward Johnson.
Deed Book Page 165 Charles Dodson convey to beloved son Thomas Dodson brown cow called by the name of Nancy marked with a crop and swallow forke on the left eare and a crop on the right eare together with all her female increase being in exchange with him my said son Thomas for one cow given him by his Godfather Peter Elmore. July 31, 1693 signed, wit William Ward and William Colston
Does Ann Elmore, Daughter of Peter Elmore Sr., Exist?
This 1793 document explains something about the relationship between Charles Dodson and Peter Elmore. Peter is the godfather, not the grandfather, of Charles and Ann’s son Thomas Dodson, born in 1681. If Peter was the child’s grandfather, this deed would have said grandfather, not godfather – because blood would trump any other kind of relationship, since a relationship was identified. If Peter Elmore was Peter Elmore Jr., it would have said uncle, not godfather.
Furthermore, there is no child named Peter among Ann Dodson’s children, nor a child named Jane, Peter Elmore’s wife’s name.
I’m beginning to wonder if Anne Elmore, daughter of Peter Sr., born in 1627, ever actually existed at all. There is nothing anyplace to suggest that she did. Jane, yes – Ann, no.
I’m beginning to think that perhaps Ann Elmore was added to the list of Peter Elmore’s children by a genealogist because someone deduced that Ann Dodson was Ann Elmore because of the 1689 transaction between Charles Dodson, whose wife’s name was Ann, and Peter Elmore.
Charles and Ann Dodson obviously were very close to Peter Elmore, but why?
We’ve now produced evidence that suggests Ann Dodson is not Ann Elmore. However, we still have no idea who Ann Dodson is.
We also don’t know who Charles Dodson’s parents were, or where he came from either. We do know that there is no record of any Dodson family in the region before Charles first appears in the 1679 transaction between Charles Dodson and Peter Elmore.
For all we know, Charles and Ann may have married in England, or wherever they were before they are found in Rappahannock County in 1679.
By that time, Ann and Charles have at least one son, Charles Jr., have probably been married about 9 years and most likely have had about 4 children. We know that Charles Jr. lived to adulthood, and it’s safe to say that Thomas born in 1781 is the second son that lived, but we don’t know if any of the children born between Charles and Thomas survived.
Can Ann Dodson Write?
Ann witnesses four documents in 1693, 1694 and 1705. It appears that she signed her name, although that may simply be because the clerk did not mention that she could not write and signed with a mark. Given that her son, Charles Jr., also married an Ann, it’s difficult to discern which Ann was signing, although the ones where Charles Jr. is absent are much more likely to have been signed by Ann, wife of Charles Sr.
If Ann is literate, it makes the probability that she was raised in England much more likely than being raised in early Virginia.
Court Order Book May 1, 1693 Power of Attorney Easter Mills of Richmond Co. constitute my trusty and loving friend Edward Reid of same to be my attorney to ask a deed above made by my husband John Mills and myself unto Charles Richardson of the same of 125 acres. Wit Ann Dodson, Charles Dodson, Jr, Charles Dodson Sr. Book 1, page 71
Deed Book May 28, 1694 William Richardson and Elizabeth his wife of Richmond Co planter to John Henley of same, planter, 50 ac parcel in Farnham parish adj said Richardson’s land and Thomas Dusin part of a devident of land purch of John Mills of Richmond Co on main branch of Totuskey. Wit Ann Dodson, Charles Dodson Jr, Charles Dodson Sr. Ack June 6, 1694 Book 2 page 29
Notice that in the above deed, no one is noted as signing with an X, but below, having to do with the same deed, both Ann and Charles Jr. are noted as signing by their marks.
Court Order Book May 28, 1694 Elizabeth Richardson POA to Thomas Dusin to acknowledge deed. Signed with mark, wit Ann Dodson by mark, Charles Dodson Jr. by mark and Charles Dodson Sr.
Will Book 24 Apr 1704-04 Oct 1705. Richmond Co, Virginia Wills, Will of Eve Smith. Grandson William and John Goad; daughter Catherine to have her father, John Williams’ chest; granddaughter Hannah Goad; exec. son Abraham Goad; Wits: William Dodson, Charles Dodson, Sr., Anne Dodson.
Life on the Northern Neck
Life on the Northern Neck of Virginia at that time revolved around the planting, nurturing and harvesting of tobacco, a very labor intensive crop.
Charles Dodson was very clearly a man with a great deal of initiative and drive, given that he started out in 1679 by working the land of Peter Elmore that he would never own, and by the time he died, 27 years later, he owned 900 acres.
Ann’s life too would have revolved around crops, seasons and church. While church attendance was mandatory at the time, most people, especially women, didn’t need much encouragement to attend. Where the court sessions were an important social occasion for men, women didn’t usually attend court, and church provided that same type of camaraderie for women.
Charles and Ann lived in, along or on Briery Swamp, a part of the Totuskey watershed. They paid for their land with tobacco, the traditionally accepted money in colonial Virginia.
Ann’s husband did the normal male things of the day. He witnessed wills, witnessed deeds and attended court, occasionally serving as a juror. Charles apparently settled differences with people amicably, because for a very long time, he wasn’t sued and he didn’t sue anyone.
He was highly thought of in the community, because in 1686/1687, when neighbor John Lincoln died, it was reported that John would “have none other than Charles Dodson” for his executor.
In 1688, Charles and Ann would have been about 38 years old.
Something began to change. The first suit was filed against Charles Dodson, with a second one following at the same court tern.
In 1693, a rather unusual transaction occurred where Charles Dodson trades cows with his son, Thomas, who was age 12.
Charles continues to sign deeds as a witness and appear in court, until in 1695, when the “Ozgrippin event” occurred. According to depositions, Charles, along with two other men went to the house of Matthew Ozgrippen (or Ozgriffen), apparently Charles Dodson’s tenant, and forcibly entered the house, beat Matthew and destroyed his tobacco and corn crop.
For two years, and with Murphy of Murphy’s law in attendance, Charles Dodson and Matthew Ozgrippen battled in the courts, with Matthew ultimately winning, but not nearly as much money (tobacco) as he had requested.
Charles then begins to file suits and not appear afterwards.
The behavior of Charles has changed perceptibly and I have to wonder if he changed at home too. He would have been between 40 and 50 at this time. His behavior is similar to what I’ve witnessed up close and personal when strokes or closed head injuries are incurred.
About 1698, the 19 year “arrangement” for Charles to farm and improve Peter Elmore’s land expires, and apparently Charles and Ann built a new house on a new plantation on land they owned, because Charles’ will in 1702/1703 references it as such.
In 1699, when he is age 50, Charles does serve on a jury once more, gives a deposition and is also involved with Ozgrippen again in a suit. Ann must have been holding her breath, waiting on one of those two men to kill the other.
In January 1702/03, Charles Dodson wrote his will. He would have been about 53 at the time. He didn’t pass away right away, in fact, not for 3 more years – and he resumes filing suit and not showing up for court too.
In March of 1705/1706, Charles Dodson’s estate is probated, with Ann as executrix.
Charles Dodson’s Estate Inventory
Charles Dodson’s estate inventory was filed with the court on Oct. 17, 1706, as follows:
- Feather bed and bedstead and parcel of sheets and one blanket and one rugg – 0600
- One flock bed and paire of blankets one sheet and rug and bolster and bedstead – 0500
- One saw and six reep hooks and one paire of old pestells holsters and one old chest and one old bill book – 0200
- Eight chairs – 0800
- Two wooden chairs – 0100
- One chest of drawers and table – 1000
- Two chest – 0250
- One small table couch – 0150
- One warming pan two paire of tongs and one box iron – 0200
- One pair hilliards – 0250
- One super table cloth and 12 napkins – 0200
- Four old napkins and one old table cloth – 0050
- One feather bed curtains and valens one blankett one pair of sheets and two pillows – 1100
- A parcel of old books – 0150
- Ole looking glass and lantron? – 0050
- One old flock bed 2 blankets rug bolster and pillows – 0400
- 2 spinning wheels – 0150
- 3 pots 3 pothooks and 3 pot hangers one spit and one iron pestell – 0450
- 99 weight of pewter – 0950
- One bellmettle pestle and mortar 0 0700
- 7.5 pounds of brass – 0130
- One servant man 3 years and 8 months to serve – 2200
- One pare of small hilliards and two smoothing iron and two cutting knives and skewers – 0150
- One mare and two horses – 2400
- Parcel of old iron – 0100
- Pair of cart wheels – 0060
- Old crosscut saw – 0150
- One saddle and pillow or pillion – 0120
- 3 cows and 3 years old – 1800
- One cow and calfe – 0500
- 6 two yeare olde – 1200
- One steere of 5 years old – 0500
- 2 barren cows and heifer and one calfe – 1400
- 3 old sheep – 0300
- 3 lambs – 0200
Total 18780
Signed John Rankin, William Smoot and Richard R. White (his mark)
I absolutely love estate inventories, because they tell us exactly what was in the household and on the farm when the man died. Inventories included everything owned by the couple, because the man was presumed to own all property of any kind except for the wife’s clothes and any real estate deeded to her individually after they were married. The wife was entitled to one third of the value of the husband’s estate unless the husband provided for more. However, the estate’s real value was established by the sale of the inventory items, not by the inventory itself, so everything was inventoried prior to sale. In some cases, the widow was made an initial allocation so she and the children could simply survive.
The feather bed clearly was the bed that Charles and Ann slept in, but it’s worth noting that there were no bedcurtains or valances which would have suggested a more upper-class household.
There were three beds in the inventory, two of flock which meant a mattress of scraps of fabric and wool instead of feathers. However, Ann and Charles had 8 children and a servant. Obviously there was a lot of bed-sharing going on and not everyone had a bed. The servant may have slept in the barn or on straw in the kitchen.
The spinning wheels certainly weren’t tools used by Charles and were obviously Ann’s.
This photo of a woman with a spinning wheel was taken about 1920, but not a lot had changed in spinning wheel design in the past couple hundred years.

The looking glass may have been a shared resource. Looking glasses were scarce and status symbols.
I do wonder why there were no pots and pans, silverware, candle holders, etc. The absence of these items if very unusual for this time period – and let’s face it, you can’t live without candles and silverware and Charles Dodson, while he wasn’t rich, he certainly was not a poor man.
Ann Remarries
Four months after Charles’ will is probated, Ann has remarried to John Hill, probably between March 6th and July 3rd, 1706.
John Hill is no stranger. In fact, he has been a lifelong friend of Charles Dodson. John Hill had previously married the widow of John Lincoln and she had probably recently died as well, assuming Ann married the same John Hill. They probably knew each other well, possibly for their entire lives. A decision to marry would have benefitted both parties. Life alone was difficult if not impossible in colonial Virginia, and Ann would probably have had some children yet at home given that she was probably between 50 and 55 when Charles died. Women had children until they biologically could not, generally between the ages of 41-45, which meant Ann probably had at least 5 or 6 children remaining at home.
Court Order Book Page 137 March 6, 1705/06 Will of Charles Dodson proved by oath of Christopher Petty with oath of John Beckwith.
Will Book Page 171 July 3, 1706 Upon petition of John Hill and Anne his wife, exec of the will of Charles Dodson decd ordered that John Rankin, William Smoote, John Mills and Richard White or any 3 of them meet at the house of John Hill and inventory and appraise the estate of Charles Dodson. All sworn plus John Hill and Anne, his wife.
Court Order Book Page 262 April 3, 1707 Action brought by Thomas Dodson against John Hill marrying the executrix of Charles Dodson is dismissed, plt not prosecuting.
Thomas Dodson was Ann’s second oldest son, of course, who would have about 26 years old at the time and had been married since 1701. Something upset him enough to file suit, although the issue was apparently resolved within the family as the suit was obviously dropped. I wonder if his suit had anything to do with what appears to be missing estate inventory items.
Court Order Book Page 275 May 7, 1707 John Hill and Anne his wife exec of Charles Dodson confest judgement to Katherine Gwyn exec of will of Majr David Gwyn for 8 pounds 19 shillings and 8 pence 3 farthings and 731 pounds of sweet scented tobacco due upon balance of accounts ordered to be paid with costs.
Court Order Book Page 281 May 8, 1707 Imparlance granted in suite between John Harper plt and John Hill and Anne his wife exec of Charles Dodson decd, till next court.
Court Order Book Page 292 July 3, 1707 John Harper against John Hill and Anne his wife exec of Charles Dodson decde, deft for 500 pounds of tobacco upon balance of accounts, def pleaded they owed nothing and plt asked time to next court.
Court Order Book Page 303 Sept. 4, 1707 Judgement granted to John Harper against John Hill and Anne his wife exec of Charles Dodson, decd, for 405 pounds tobacco due by account proved by oath of plt ordered paid with costs.
Court Order Book Page 323 Dec. 4, 1707 John Hill and Anne his wife exe of will of Charles Dodson decd against John Harper dismissed, plt not prosecuting.
Court Order Book Page 40 June 2 1709 Judgment granted to John Davis Sr. against John Hill and Anne, wife, exec of Charles Dodson decd for 136 pounds tobacco due by account ordered paid with costs.
John Hill
As with Charles Dodson previously, we now have to track Ann’s life through husband, John Hill. As we might expect, it appears there is more than one John Hill, at least eventually. We can’t tell the difference between the two, if there are two this early, and we don’t know when Ann died.
Court Order Book Page 27 June 1, 1709 Ordered Luke Hanks officiate as constable for the ensuing year in room and stead of John Hill in the precincts between Totuskey and Farnham Creeks.
Court Order Book Page 337 Sept. 8, 1715 Petition of Thomas Mountjoy and John Hill for their keep an ordinary at the place where they now live is granted provided they give bond and security as the law directs.
Court Order Book Page 475 May 2, 1716 Ordered the Sheriff to summon William Hill and John Hill to appear to answer the presentment of the grand jury against them for stopping the creek and mill road from the Folly Neck in Farnham Parish within this 3 months.

Please note that you can click to enlarge any image.
Folly Neck is the point of land on the south side of Tosuskey Creek where it intersects with the Rappahannock River. Folly Neck Road (614) intersects with the main road (3). Did Ann live here with John Hill, or did they live on one of Charles Dodson’s plantations? Was this one of Charles Dodson’s plantations? Folly Neck is just south of Totuskey Creek and not far from Rich Neck, shown a the top of the map below, where Charles Dodson’s land deeded to both Charles Jr. and Thomas in 1703 was located.
The old Farnham Parish church is just south of Emmerton in the bend of the road and the new church, built in 1737, is currently located at Farnham. The river near Sharps is Farnham Creek and the one heading northwest underneath the word Simonson is Morattico Creek.

Court Order Book Page 43 August 2, 1716 John Hill his action of case against Ann Dodson executrix of the will of Charles Dodson decd for 313 pounds tobacco due by account is dismissed, plt not prosecuting.
This Charles Dodson is Charles Dodson Jr., the son of Charles Sr. and Ann Dodson Hill, and the Ann Dodson mentioned here is the wife of Charles Jr.
Deed Book September 1716 Deed between Thomas Mountjoy and John Hill.
Deed Book Page 66 October 4, 1716 John Doyle from Edward Barrow gent, one of his majesties justices of the peace for this county, against the estate of John Hill for 261 pounds of tobacco is dismissed, the plt not prosecuting.
Given that this 1716 record doesn’t say John Hill, deceased, it’s unclear whether or not this John Hill in question is deceased. It seems unlikely since there has been no other mention of a will or probate estate in any existing court or will book for Richmond County. The same day, John Hill is in court, noted below.
Deed Book Page 67 October 4, 1716 John Hill came into court and confessed until Augustine Higgins 4167 pounds of tobacco which is ordered to be paid with costs.
Court Order Book Page 72 October 4, 1716 Action of debt between Joseph Hutchinson Plt and Thomas Mountjoy and John Hill, deft, for 750 pounds tobacco due by bill being called and not appearing on motion judgement is granted him against William Carter, returned security for the deft for the aforesaid sum and costs unless defts appear at next court and answer action.
Court Order Book Page 73 October 4, 1716 Mary Stevens action of debt against John Hill for 600 pounds tobacco due by bill, dismissed, plt not prosecuting.
Court Order Page 91 Feb. 7, 1716/17 Joseph Hutchison action of debt against Thomas Mountjoy and John Hill dismissed the plt not prosecuting.
John Hill was appointed constable, but I failed to copy the date which was in either the 1716 -1717 Court Order book or the 1717-1718 book.
Assuming this John Hill is the same John Hill that was married to Ann Dodson, she has died sometime between June 2, 1709 when she is last mentioned in the court records pertaining to the estate of Charles Dodson, and March 7, 1721/1722, when John Hill’s new wife released her down in land John Hill sells.
Court Order Book Page 36 March 7, 1721/22 Frances Hill wife of John Hill relinquished right of dower in piece of land sold by her husband unto Thomas Creele and ack last Jan court.
The Creele family does live in the neighborhood, because in later generations, the Dodson family intermarries with Creeles. Based on the next entry, John Hill has obviously married a recently widowed woman, for the third time. Given that he seems to have a propensity for that, I wonder if Ann Dodson Hill had just recently died in late 1721 or early 1722.
Court Order Book Page 36 March 7, 1721/22 John Hill and Frances Hill, relict of Robert Reynolds, decd came into court and made oath that Robert Reynolds departed this life without making any will so farr as they know or believe and on their petition and giving security for their just and faithful administration of the decds estate, certificate granted them for obtaining probate.
Court Order Book Page 36 March 7, 1721/22 John Hill, Frances Hill, Caron Brannon and James Neale came into court and ack bond for John Hill and Frances Hill admin of estate of Robert Reynolds, decd.
Court Order Book Page 36 March 7, 1721/22 Thomas Dodson, Christopher Petty, Bartholomew Richard Dodson and Thomas Scurlock or any 3 of them to appraise estate of Robert Reynolds decd. All sworn plus John and Frances Hill, the admins.
It’s impossible to tell whether the above John Hill is the same one that was married to Ann Dodson, but the continued interaction with the Dodson family suggests possibly so. It’s also possible that we are dealing with a second generation John Hill, although Jr. and Sr. is never used in these records.
Court Order Book Page 83 January 2, 1722/23 Ordered John Hill in the Forrest of Moratico of Northumberland Parish to answer to the presentment of the grand jury for unlawfully absenting themselves from their Parish Church for one month last past.
This entry is somewhat confusing, because there is not now nor was there ever, that I an find, a Northumberland Parish in Richmond County, Virginia. There was a Northumberland County formed in 1648, a neighbor to Richmond County, but the parishes in Northumberland were called St. Stephens and Wycomico (Wicomico) when the county was founded. Northumberland Parish, is therefore, a bit of a mystery.
If John Hill lived in the Forest of Moratico, so did Ann. This reminds me of Sherwood Forest, although I’m sure I’m being overly romantic. I could not find the Forest of Moratico on current maps, or any map between now and then. Clearly, it’s someplace near the Moratico River which is in the general vicinity of the Dodson lands in Richmond County.

I’m guessing that the Forest of Morattico would be someplace near Morattico Creek shown at the red balloon, above. There are several wooded areas, including three state-owned areas shown in green above. Below, you can see the extent of the tree cover.

The involvement between the Dodson clan and John Hill continues.
Deed Book Dec. 10, 1723 Thomas Durham to Thomas Dodson Sr. 5 shillings 100 acres formerly belonging to Abraham Marshall bounded by Spanish Oak corner tree of Charles Dodson part of patent formerly granted to William Thatcher by the main branch of Totoskey and then (metes and bounds.) Signed Thomas and Mary Durham, wit John Hill, William Walker and Jeremiah Greenham
Deed Book Dec. 10, 1723 between Thomas Durham to Thomas Dodson Sr. of Richmond Co. 5000 pounds tobacco received by Thomas Dodson Sr certain parcel of land formerly belonging to Abraham Marshall bearing date 25th of 9ber, 1692, containing 100 acres bounded (same as lease above). Signed Thomas Durham, Mary Durham, wit John Hill, William Walker, Jeremiah Greenham
Thomas Dodson Sr. is Ann’s son.
Court Order Book Page 307 Sept. 7, 1726 William Garland plt and Edward Jones deft, the deft being called and not appearing, judgement granted him against deft and John Hill his security for the sum sued for in the declaration shall appear next court with cost providing deft does not then appear and answer thereto.
Court Order Book Page 307 Sept. 7, 1726 John Nancy vs John Hill deft damage 100 pounds sterling the plt being called and not appearing, at deft’s motion ordered that he be nonsuited and that he pay the deft damage according to law and attorney’s fees with costs.
Court Order Book Page 308 Sept. 7, 1726 John Hill his case damage 20 pounds sterling against Richard Woollard dismissed, the plt not prosecuting.
I made a note that there is a John Hill listed in the book, Richmond Co Will Book 4 1717-1725 by TLC, but unfortunately, I did not copy the page. The date could be wrong as well, as the books at the Allen County Public Library in this series appears to have the covers mixed up. This site shows that John’s will was probated April 3, 1728 where he leaves the plantation and land to his wife, who is unnamed.
I expect the 1728 entry is “our” John Hill, as he is clearly dead by April 1728 when Frances is shown in the court records as his executrix. Furthermore, three sons of Charles and Ann Dodson are still connected with this man.
Court Order Book Page 399 April 3, 1728 Last will of John Hill decd presented by Frances Hill, executrix and oath of James Wilson and John Hightower, two witnesses.
Court Order Book Page 399 April 3, 1728 Frances Hill, John Hightower and Lambert Dodson came into court and ack bond for Frances Hill’s administration of will of John Hill decd.
Court Order Book Page 399 April 3, 1728 Thomas Scurlock, Thomas Dodson, John Hightower and Bartholomew Richard Dodson or any 3 of them to appraise estate of John Hill. Oaths admin to all 3 plus Frances Hill.
Court Order Book Page 435 October 2, 1728 Action of debt between Frances Hill executrix of will of John Hill, decd, plt and Thomas Livack and Mary, wife executrix of will of John Mills, decd, for 16,000 pounds tobacco due by bond, the def being called and not appearing the motion of the plt judgement is granted her against the defts.
These next two orders show that there was unquestionably (at least) two John Hills, because one is still living.
Court Order Book Page 644 May 3, 1732 Thomas Dodson, Sr, Jeremiah Greenham and John Hill on grand jury.
Court Order Book Page 172 April 1, 1734 Jeremiah Greenham and John Hill on jury.
At this point in time, it’s very unlikely for this John Hill, active in court, to be the husband of Ann Dodson Hill. Ann would have been about 85 years old by now, and John probably as well. They are very likely both deceased by this time and if John isn’t deceased, he’s probably not riding his horse to court. I stopped extracting John Hill information at this point.
I believe that Ann died before 1721/1722 when John had remarried to Frances.
Where is Ann Buried?
In the book, “The Registers of North Farnham Parish 1663-1814,” the following map of the current and old Farnham Parish churches is shown. The current church was built in 1737, and the previous church was located some distance away, on the main road.

This map gives the only locations I have ever seen of the original church, other than a general description.

What I don’t know is whether this is an approximation, or if the old-timers actually knew the location of the old church.
Regardless, given this map, I was able to find the location on Google maps today based on the bends in the road.

Map above, satellite view below.

The X on the map from the Farnham Parish book would be found approximately where the Calvary United Methodist Church is found today.


A closer view allows us to see the lay of the land.

The church does have a cemetery, although we have no idea of course whether this cemetery predates this church or whether the original Farnham Parish church was even in this location.

The original church was certainly someplace nearby, so let’s take a drive down this road.

What a beautiful white country church. Whether the original Farnham Parish Church church was in this location or not, Ann would have seen this beautiful countryside on her way to church.

The earliest burials in this cemetery with markers are a Ficklin in 1873 and a Lyell 1884. The area of the cemetery is quite large, so there may well be many unmarked burials in the churchyard. I was unable to find any history of this particular church online.

The fields beside the church would have been prime farmland – flat and dry. At that time, they would have been planted in tobacco (for 3 years) or corn (for 3 years), or lieing fallow (for 20 years), waiting for the nutrients to replenish so that the fields could be planted once again.
Ann’s Children
Ann and Charles had several children who survived at least until Charles made his will in January 1702/1703. There were likely several more children born to Ann as well. In the following generations, there were at least three grandchildren named for Charles but only one that we know of named for Ann. Of course, we don’t know the identities of the children of William, Anne or Elizabeth and only two names of children of Richard Bartholomew who are remembered in Charles’ will, but we know nothing further.
If Ann was born about 1652 and had her first child in 1672, she would have been having children until about 1695 or so when she would have been about 43 years of age.

- Charles Junior was born between 1672 and 1677 and likely closer to 1672 given that he witnessed a document in 1693. Based on the deeds by Charles and the fact that he was named for his father, he was most likely the eldest son, if not the eldest child. Charles married an Anne whose surname is unknown. Charles Jr. died between July of 1715 and May of 1716 when his will was probated.
- Child born about 1674
- Child born about 1676
- Child born about 1678
- Thomas Dodson was born on May 15, 1681, married Mary Durham on August 1, 1701 and died on November 21, 1740 in Richmond County.
We don’t have birth dates for the remainder of the children, so I’ve listed them as best we know.
- Child born about 1683
- Elizabeth possibly born about 1685, nothing further known except that she was alive when her father wrote his will in 1703
- Anne possibly born about 1687, nothing more is known except that she was alive when her father wrote his will in 1703
- Bartholomew Richard Dodson married Elizabeth Clark and their first child, James was born on December 23, 1716 according to the North Farnham Parish Records. This would suggest his birth date probably around 1689 if James was the first child. They are last found in the Richmond County records in 1734 selling their land to brother Thomas Dodson, listing themselves as “of Northumberland County.” Unfortunately, Northumberland County records are mostly missing and Bartholomew Richard disappears after this date.
I suspect that Bartholomew Richard’s name may be a hint as to the parents of either Ann or Charles, given that middle names were not utilized at that time unless they were family names and Bartholomew was a very unusual name.
- William Dodson born about 1691, about whom nothing more is known. He may have died before a 1717 land conveyance by James Tune and Bartholomew Richard Dodson that could have been his land, or he may simply have moved away, abandoning his land with no record.
- John Dodson born about 1693 was married to Elizabeth Goad about 1724 and died in Shenandoah Co., VA in 1784. In 1726, John sold or leased to Robert Mathews his 100 acres for the use of Mathews for 3 natural lifetimes, with the actual ownership remaining with John, per Charles Sr.’s wishes in his will. In 1737, two of John’s sons, Charles age 1 and Moses age 8 were taken into the care of the church, although nothing more is said as to why. John left soon thereafter and is found in Augusta County by 1741 when his daughter Elizabeth was baptized. John bequeaths his land, leased for 3 lifetimes, to his son, Charles, in his will.
- Lambeth Dodson was born about 1695 and married a Sarah whose surname is unknown. Lambeth sold the land he inherited from his father being “the new dwelling plantation with 100 acres of land belonging to it” to his brother, Thomas, who bequeathed the land in his will in 1739 to his son Greenham Dodson. By 1753, Lambeth is found in Halifax County, VA and in Guilford Co., NC by 1779.
Lambeth’s son, Greenham Dodson married Eleanor Hightower and sold the 100 acres of Charles’ land to Jeremiah Greenham in 1746, Richmond County deeds 10-373. This land needs to be tracked forward from Jeremiah, with the hope that it can be located today.
Ann’s DNA
The only DNA that we could specifically identify today of Ann’s would be her mitochondrial DNA which is passed from mothers to all of their children, but only passed on to subsequent generations by females. Unfortunately, we know absolutely nothing about what happened to Ann’s two daughters, Anne and Elizabeth. We only know they existed because Charles’ will mentions them. They could have died or married, but regardless, we have no further records of these women, so we can’t obtain Ann’s mitochondrial DNA.
Many people carry autosomal DNA tracking back to Charles and Ann. Some of that DNA is undoubtedly Ann’s DNA, but when we have DNA attributed to a couple, the only way to tell whose DNA is whose is to be able to track specific segments upstream to either the Dodson side or Ann’s side.
The way to do that is to track those segments by finding them in Dodson’s, for example, who do not descend through Ann or Charles – meaning through Charles Dodson’s siblings. Since we don’t know who Charles’ parents nor Ann’s parents were, we don’t know who their siblings are either, so our figurative hands are tied relative to identifying whether segments descending from this couple are his or hers. We can only tell that they are “theirs.”
At Family Tree DNA, where I can both search for current and ancestral surnames, AND compare people to look for matching segments in a chromosome browser, I did just that.
I found a total of 22 people who either have the current surname of Dodson or have Dodson listed in their Ancestral Surnames. Some have trees, and some don’t.

I checked each tree to see how my matches descend from a Dodson ancestor. I discovered that we descend through at least two sons of Charles and Ann Dodson. Several people are brick walled and don’t have their genealogy back far enough to connect.
However, the Dodson DNA connects us when compared to known Dodson descendants.
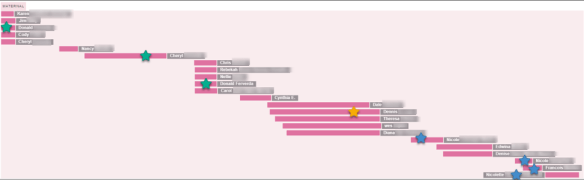
I pushed all of these people through to the chromosome browser, 5 at a time, and downloaded the matching results, combining them into one working spreadsheet. In total, I had 22 matches that matched me on a total of 452 separate segments. Many of these people matched me on some of the same segments
There are two sizeable segments of chromosome 5 that have, amazingly, arrived intact from the Dodson line.

This first segment is staggered across the first half of the chromosome, and of this group, only two, the yellow and orange have their Dodson lines proven back to Charles. Both the yellow and orange descend through son Thomas, the same as me.
The cM values and ranges for the people shown above as compared to me are:

While the chromosome browser tells me that all of these people match me on the same chromosome – all chromosomes have two sides – Mom’s and Dad’s. Furthermore, these matches are staggered, so not entirely overlapping. Therefore, some of the people may not match each other either because their overlapping portion of the segment on chromosome 5 isn’t large enough to be considered a match to each other, or because some people could be matching me from a line on my mother’s side.
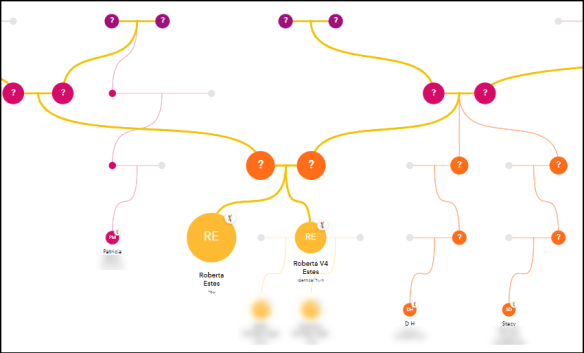
To see if these people all match each other, I used the Matrix tool.

Three of these individuals match each other, plus me, although a matrix match does not guarantee a match on the same segment(s). It does, however, create a genetic network of people known to match and share ancestors, or in this care, a mixture of people proven to Charles and Ann and people whose genealogy isn’t proven quite that far back but who are Dodson descendants.
Two individuals do not match each other. If the overlap occurs without enough DNA matching to be over the threshold, non-matching can be the result. As you can see in the table and also on the chromosome graphic above, the orange and magenta are very offset from the other 3. Sure enough, these two don’t match the other 3 more closely aligned matches over the matching threshold, so either they don’t belong in this group or their overlap isn’t large enough for a match to each other. Looking for other clues, neither of those two are assigned to my father’s side through phased matching.
But wait, there’s more.
A second matching segment on chromosome 5 is even more remarkable.

These segments are even longer and more robust. Five people are shown above on the chromosome browser, above, and in the first 5 rows below.

Three additional people match on these segments, but the chromosome browser only displays 5 at a time. The row below green would be the exact same segment as the green segment. The segment with only 1.37 cM is very small and the last segment, at 13.34 is a known cousin, so I omitted that individual from the browser.
To be as sure as I can be that these segments are legitimate and that these people also match each other, I used the matrix tool again.

This matrix shows that all of the individuals in the matrix match. I’ve included two of the three individuals whose DNA did not fit in the chromosome browser, excluding the one small segment match. All match each other, except for the last row who is the known cousin whose matching segment is much smaller and does not extend the full length of the segments of the other individuals who are matching to me. Therefore, that cousin matches some, but not others, as might be expected.
While Family Tree DNA does not have explicit triangulation, the combination of the chromosome browser showing matches on the same segment, the same family line and the matrix tool indicating that these people also match each other is a very powerful indication that triangulation would or will occur if you can verify that these people also match each other. These individuals form a match group.
So, at this point, we can assume that of these people, all of the group in the second matrix and at least 3 of the 5 in the first matrix all descend from Charles and Ann Dodson, for a minimum total of 10 people plus me.
This is actually quite remarkable, because these large segments have survived through 10 generations on my side alone – plus about as many generations for each of them as well.

If one can assume that the other people matching that chromosome 5 segment are also 10 generations removed from Charles and Ann, they would be my 9th cousins.
The shared cM chart doesn’t even go as far out as 9th cousins. The highest is 8th, with the maximum amount of shared DNA by cM for 8th cousins being 16 cM with an average of 9. These centiMorgans ranging from 15 to 39 for this entire group is really quite amazing. The Dodson DNA seems to “stick together” quite well.
Now if we could just tell if we are looking at Ann’s DNA or Charles’ DNA, or some combination of both. Maybe someday there will be an avenue to associate this segment with the Dodson line or Ann’s family line – and if that day comes, maybe we’ll finally be able to solve the mystery of who Ann Dodson, wife of Charles Dodson, really was.
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
Genealogy Services
Genealogy Research
Like this:
Like Loading...








































































































































































































{kind=link}