John Campbell’s early life is shrouded in the mists of time. We can’t positively identify him until he’s an adult, living in Claiborne County, Tennessee, beginning in 1802. By that time, he would have been roughly 30 years old, married, and probably had 2 or 3 children by his wife, Jane “Jenny” Dobkins, daughter of Jacob Dobkins and Dorcas Johnson.
The closest thing to proof we have that Jane was a Dobkins is Claiborne County lawyer and historian, P.G. Fulkerson (born in 1840) who interviewed old-timers and documented the early families. He stated that Jacob’s daughter, Jane, married John Campbell and his other daughter Elizabeth married George Campbell. Jacob Dobkins died in 1833, and the Claiborne County courthouse burned in 1838, so if Jacob had a will or estate settlement that named his children, it’s lost to flames.
We believe that John Campbell was born in Virginia based on census information from his children in 1880.
John’s children were:
- Jacob Campbell born about 1810, died 1879/1880, Collin Co., TX, married Temperance Rice
- Elizabeth born about 1802, dead before 1842, married Lazarus Dodson
- Elmira born about 1804 married John Pearson
- Jane born about 1807, married a Freeman, then a Cloud
- Martha born 1807/1808, died after 1850, married Elisha Jones, moved to Coles County, Illinois before 1839
- Rutha born about 1813, died after 1870, married Preston Holt
- George Washington Campbell born about 1813, died after 1870, probably in Denton County, Texas, married Nancy Eastridge, then Mary unknown
- William Newton Campbell born 1817, died 1908 Tillman Co. OK, married Sydnia Holt, shown in the photo below

I spent years, decades actually, chasing the wrong parents for John Campbell. I’ve chased so many parents for this man that I’ve just about ruled everyone out and the ones I haven’t ruled out HAVE to be his parents by process of elimination. If only it were that easy. Campbells are like rabbits – they have huge families, are found everyplace and they all have the same first names. John – how could you be any more generic? And the man we presume is his brother is named George. Not much better. Why not Hezekiah and Azariah???
Several years ago a cousin sent me part of her Campbell research, 4 pages of a 23 page document. In the portion she sent, she states that back in the 1950s, some Campbell relatives were interviewed who were quite elderly, and they reported that John’s father had been James, as told by their grandparents. That information morphed into the James Campbell from the northern part of Hawkins County who was also descended from the Crockett line. This did make some sense, as John’s grandson’s middle name was Crockett, although his first name was David. The problem is that when you track that James in Hawkins County, TN and his widow and children, there is no John and absolutely no hint of a connection with the John Campbell in Claiborne County, Tennessee, nor the George he is so closely associated with. Not only that, but James Campbell lived in Carter’s Valley, no place near Jacob Dobkins whose daughters John and George Campbell both married.
In Hawkins County, there are two very distinctive groups of Campbell men. The group that lived about 20 miles north of Rogersville in Carter’s Valley, who believed they were actually settling in Virginia originally, and Charles Campbell who lived just south of Rogersville across the Holston River on Dodson Creek. The North group is who James Campbell descended from the Crockett family is associated with. Charles Campbell, living on Dodson Creek, had 2 sons, John and George, and Jacob Dobkins, whose daughters John and George married, lived just up the road at Bulls Gap, about 9 miles or so. Charles Campbell lived at the ford of the Holston River, so I’d wager that everyone who crossed the river stopped by to visit, probably including Jacob Dobkins and his daughters.
Charles Campbell was living on Dodson’s Creek in 1788 and possibly as early as 1783. In 1793, he deeded land jointly to John and George Campbell, from Hawkins Co., for 45#, 150 acres on the south side of the Holston River on the west fork of Dodson Creek. Charles signed the deed and John Payne was the witness. The description was metes and bounds except for a stake at the mountain.
On Feb. 26, 1802, book 3-54, George and John Campbell of Hawkins Co. sell to Daniel Seyster the 149 acres on the fork of Dodson Creek where “John Campbell now lives” for 225#. Both men signed and the witnesses are William Paine, Michael Roark and Charles Campbell. It was proved in the May session of the court in 1802 by Michael Roark, which implies that the Campbell men were gone by that time.
John Campbell is no longer found in Hawkins County. On May 1, 1802, John first appears in Claiborne County when he purchases land from Alexander Outlaw. This deed is in the loose papers in the front of deed book A.
Alexander Outlaw of Jefferson Co. TN to John Campbell of Claiborne, copied from Book A page 32 – May 1, 1802 – for $400 in hand and paid by John Campbell, tract of land on the North fork of Sycamore Creek adjoining a survey of 640 acres of James Cooper and Nathaniel Henderson beginning on a grassy hill on the North side of said Creek…300 acres. Alexander signs. Witness Jacob Dobbins and James A. Perreman. Registered July 7 1802.
In the same court session, John Campbell is assigned with other men to “view and lay out a road from Fort Butler to Mulberry Gap and report to next court.”
In 1809, John purchases slaves on the same day, from the same person who sells slaves to Jacob Dobkins. Note that this same male slave, or another by the same name, is sold within the family in 1839 after John Campbell’s death.
March 29, 1809 – Jesse Cheek of Grainger County to John Campbell, negro boy Charles for $300, signed and witnessed by Solomon and Reuben Dobkins. (note this same day Jesse Cheek and his daughter sold slaves to Jacob Dobkins as well).
1809 – Elizabeth Cheek of Grainger does sell and deliver a negro girl named Jamima aged six years unto John Campbell of Claiborne and by virtue and effect of these presents to bind myself and my heirs to warrant and defend said negro from all persons and claims…Elizabeth signs…March 24, 1809 witness Jesse Cheek Senior and Jr.
Followed directly by…
I, Jesse Cheek, hath bargained and sold unto Jacob Dobkins 4 negroes names Aneker or Anekey, Mitilty, Jiary, Amelyer for the consideration of $130 in hand paid. March 29, 1809 Jesse signs, registered July 30, 1809. John Campbell and Solomon Dobkins witness.
In 1811, John Campbell purchases more land.
Jan. 21, 1811 Abner Chapman of Warren Co., Georgia to John Campbell of Claiborne $100 the land where said John Campbell now lives at the head of the north fork of Sycamore Creek (metes and bounds)…original corner of Chapman grant for 400 acres….stake in Campbell’s line…Campbell’s corner…crossing line in Chapman grant…containing 300 acres more or less. Signed. Wit Walter Evans and Abel Lanham. Registered May 18, 1811
For the next many years, John Campbell along with George Campbell and often Jacob Dobkins are assigned as jurors and to work on and lay out roads. This is normal activity for the timeframe. Courts, which were held quarterly, were quite the social event of the season – and everyone attended. If they weren’t a juror, they certainly wanted to watch the proceedings. It’s said that one time there was so much imbibing that court had to be adjourned because the justices fell off the bench.
It appears in 1812 that John managed to upset someone, although there were two John Campbells, the other being the son of Arthur Campbell of Middlesboro, KY, who lived just beyond the Cumberland Gap. This Martin Beaty did sue numerous people in the Arthur Campbell family, so maybe our John didn’t get himself sued.
March 25, 1812 – pages 18 and 19 – Martin Beaty vs John Campbell, defendant appears in court by Jacob Peck and Charles F. Keith his attys for slander, appealed for unit of error – moved to next court. (Note – Beatty lives where Kentucky Rd. crosses Gap Creek, very near Middlesboro, KY where Arthur Campbell lived.)
In 1817, John Campbell was security for Solomon Dobkins, who was a constable.
In 1823, John Campbell buys and sells some land.
1823, June 4 – William Willoughby of Sullivan Co and John Campbell of Claiborne $600 paid in hand tract of land beginning on Brumfield Ridley’s corner chestnut then down the Valley south…stake in the side of Powell’s mountain…200 acres…being the tract where John Condry and others now live. William Signs. Witness Hugh Graham and R. Rose.
1823 – John Campbell to Jacob Campbell for $300 land on both sides of main road from the spring fork of Sycamore Creek to Little Mulberry Creek being one half of a two hundred acre tract of land granted by the St of NC to Matthew Willoughby of number 79 dated Feb. 13, 1791 and said half begins at a chestnut tree at the beginning of said grant running with the grant line…crossing said road…stake in the side of Powell’s mountain in the grant line…containing 100 acres to Jacob Campbell. John Campbell signs. Witness Walter Evans (he is the clerk). Registered Jan 15 1824. Proved in open court May 1823.
John Campbell dies in 1838. There remains some confusion about exactly where John died. He had some connection to Coles County, Illinois, possibly only because his daughter lived there and the documents in question may only be referring to her residence in Coles County. Some indication is that John died there, but in the subsequent deeds, it suggests that he died in Claiborne County. Regardless, we know that he was dead on or before Sept 22, 1838 when William Hicks built John’s coffin and submitted a receipt for payment for $5.
In 1840, a William Hicks was living 2 doors away from a William and George Campbell, so I’m betting that John Campbell was buried in Claiborne County. William Hicks also purchased items at the estate sale of John Campbell in 1838. If John was buried in Claiborne County, in September, I’m thinking that no one would want to transport a body from Illinois to Claiborne County for burial, by wagon, at about 20 miles a day. Google maps says that it’s about 445 miles so that would equate to about 3 weeks. By that time, I’m thinking they would be burying him along the road someplace or giving him a water burial in the Ohio River.
If John died in Claiborne County, which seems very likely, he could be buried in the old Jacob Dobkins Cemetery which seems to be the family cemetery, shown below, and has many early unmarked graves, including that of Jacob Dobkins and his wife. There was not a cemetery on John Campbell’s land, unless there was an early cemetery where Liberty Church and cemetery stand today, which is certainly possible.

On the 1839 tax list, John is listed thus in the Rob Camp District in the far northeast part of the county:
- John Campbell, decd – 443 acres worth $1300, 25 school acres worth $10, 2 slaves worth $900
Will Book A – page 71 – inventory of the estate of John Campbell, decd and of sales (3 pages) William Fugate and Jacob Campbell admin.
In the cousin’s research that she sent, she indicated that Henley Fugate was the uncle of John Campbell, and was married to Elizabeth Campbell, sister of John, although that would make Henley John’s brother-in-law, not his uncle. Henley and Elizabeth’s son, William, according to the cousin, was administrator of John’s estate, along with Jacob Campbell, John’s son, and that somehow William Fugate and Jacob Campbell cheated the heirs out of their money. There are 4 different court entries accounting for the funds, which don’t look in any way unusual, but there is always a back story to be found, it seems, especially having to do with estate settlements. The Fugates do seem very connected to the Campbell family, so there may well be a family relationship there. The cousin also indicated that the families had lived adjacent in Virginia but since I can’t seem to find a location in Virginia, I have been unable to confirm that tidbit of data.
John Campbell’s sale was huge, as these things go, and as compared to other estates of the time.
- Cash on hand after paying note – $649
- Note from Johoel and William Fugate – $15
- Notes from others – $385.22
Apparently John was in the business of lending money as he was owed notes from several people.
John’s estate sale was Feb. 25, 1839. We don’t know what the weather was like that day. In Claiborne County, it could have been anything from snowing, slick and miserable to sunny and warm. The administrators of John’s estate likely wanted to get things sold and felt early spring was a good time because farmers were likely to purchase things they needed for the upcoming planting season.
Sadly, the widow, Jane Campbell, had to purchase her own things at the estate sale, because all property was deemed to be that of the husband. Therefore, Jane Campbell, widow, purchased the following items for a total of $87.63 and a half cents:
- 1 saw
- 1 little wheel
- 1 set spools
- 1 cupboard furniture
- 1 reel bed and bedding
- 1 chaff bed and feather bed
- 1 lot of gums (guns?)
- Sheet of cotton
- 1 trunk
- 1 clock and case
- 1 lot of hay
- 1 bucket
- 1 set fire irons and shovel
- 1 tin trunk
- 1 set chairs
- 1 lot barrels
- Tub and lard
- 1 ewe and lamb
- 1 mare
- 1 lot of casting
- 1 cow
She obviously purchased her spinning wheel. I have to wonder at the lack of a listing for the family Bible.
Others at the same purchased:
- 1 tub
- 1 chipping ax
- 1 lot tubs
- 690 lbs bacon
- 1 broad ax
- 1 big wheel
- 1 trunk
- Raxor and box
- Table
- Ax
- 2 pr gears
- 1 yoke oxen
- 2 baskets
- Hoe
- Curry comb and chair
- Piece of steel
- Ax
- Harrow
- 1 bull
- 1 grindstone shovel, plows and bridle
- Remnant of corn
- 1 box shoemakers tools
- Side leather
- 2 lots tools
- Fire irons
- 1 coult
- 1 cow
- Cow
- Horse
- 1 lot sheep
- 4 yearlings
- 1 scythe blade
- Cross cut saw
- Candle stand
- 1 saddle
- 2 pitch forks
- Double tree
- Wheet sive
- Wagon
- Skillet and lid
- Lot plunder
- Lot corn basket and pickett book
- Yoke of oxen
- Lot of tools
- Coult
- 1 horse
- 1 lock chain
- Cow and calf
- 1200# ?
- 1 plain
- 1 mare
- 1 bridle
- 2 hoes
- Coulter and iron
- Remnant of oats
- Cutting knife and hammer
- 202 lb bacon
- 1 lot castings
- Saddle
- Lot of hogs
- Set of chains
- Big plow
- 13 bushels and 3 peck wheat
- Plow
- 50 bushels corn
- Big plow
- Mill peck
- Plow
- Sack of cotton
- Large plow and matchk
- Hoe and stretchers
- 1 bridle
- Grindstone
- 1 shovel, plows
- 1 chair
- Lot tools
- 1 beef hide
- 1 bee gum
- Hoe and rake
- Bridle and lot of corn
- Big sugar
- Bureau
- 1 pair chains
- 1 little when
- 1 side leather and castings
- 1 press
- 1 bee gums
- Blacksmith tools
- Piece of iron
- 2 leather aprons
- Lot of castings and coffee mill
- 1 pair steelyards
- 1 cack bank
- 1 scythe and cradle and houe
- 1 cupboard
- 100 dozen binds of oats
- 1 mattock
- 1 bedstead
- 3 scythes
- 1 cutting knife and scythe
- Plow
The total of the estate sale was $958.58
Was John a shoemaker or a blacksmith? Was his slave trained to one of these professions?
What else does this tell us about John’s life? He was obviously a farmer, but everyone was. He had several horses; 2 mares, 2 colts, 3 horses and 4 yearlings. He had a “lot of hogs,” which of course means a group that was sold together, and he also had almost 1000 pounds of bacon. Fall was slaughtering time, so there were quite a few hogs that had been killed and processed, probably in a smoke house. There was one ewe and lamb and obviously Jane felt fondly towards them. There was also a “lot of sheep.” There were 3 cows and a bull and there were 2 yoke of oxen. Oxen were matched and trained to work together, so they were often sold together as well.
They also had bee gums, which were gum trees that bees lived in. So in essence, he was an early beekeeper. This means, of course, that they also had honey, which might be connected to the item called “big sugar.”
They had 3 beds, 3 trunks, 2 cupboards, a bureau and a clock, which was a luxury. John was not a poor farmer. In fact, few people in Claiborne County had slaves, so John having 2 was rather unusual. Those who did have slaves had 1 or 2 and a very few people had 10 or more. In the 1830 census, John had 2 slaves and his father-in-law, Jacob Dobkins, had 4. Finding this heritage of slavery within the family saddens my heart, although I realize that it was socially acceptable, even desirable, at the time. Well, desirable by everyone except the slave. Slaves on small farms were often well treated and had good lives, and I hope that is how these people were treated.
John’s children and their spouses also attended his estate sale except for his daughter, Martha, who lived in Illinois. It’ must have been a sad day to see your parents things being divided like so much excess and being sold away from your mother. Jane did, of course, retain her dower right to one third of his estate, but that didn’t stop the estate sale.
In July of 1839, the court record shows each of the children of John Campbell and what they received during their lifetimes.
July 22, 1839 – Estate of John Campbell, amounts received during this lifetime:
- Jacob Campbell $210
- George Campbell (blank)
- Lazarus Dodson 192.95
- Preston and Ruth Holt 170.00
- Jane Freeman 43.50
- Jefferson and Elmire? (Eliza?) Pearson 124.50
- William Campbell 214.00
- Martha Jones 65.75 of Illinois
Page 206 – settlement estate of John Campbell by William Fugate and Jacob Campbell before Wiley Huffaker, clerk of court – paid William Hicks for coffin- Sept 22, 1838 – $5.00 Paid Jane Campbell for her dower June 25, 1839
By 1839, John’s heirs are selling his land to their sibling, along with a slave described as a boy in this document, so not the same person purchased in 1809.
July 29, 1839 – Elisha Jones and Martha Jones his wife, formerly Martha Campbell and daughter of John Campbell, now decd of Coale Co., Illinois, to William and George Campbell of Claiborne Co., for $187.50 assign all right and interest of 1/8th share in consequence of Martha being a daughter and heir of the said John Cambell in tract of land containing 345 acres adjacent the lands of William McVay and Marcurioius Cook it being the tract of land where on the John Campbell formerly lived and whereon the said John Campbell died seized and possessed of subject to the dower of the widow and all right and title after the death of the widow. Elisha signs and Martha with an X. Witness William Niel and Jacob Campbell.
This is the entry that caused the confusion about where John died. We know that Martha Campbell lived in Illinois, and given the other information we do have, I believe this is mean to convey that Martha Jones is of “Coale Co., Illinois” and not John Campbell. The words “formerly lived” is always used after death. John was clearly still very invested in Claiborne County, judging from his significant estate.
The East Tennessean Newspaper on Saturday, March 7th, 1840 ran the following legal notice:
On the 13th day of Match next at the late residence of John Campbell, dec’d, upon Little Sycamore Creek in Claiborne County – offer at public sale to the highest bidder, three slaves, Charles, 51 or 52, Jenny, 38 years and Berry, 25 years. William Fugate and Jacob Campbell administrators of John Campbell, decd. February 8, 1840.
On March 30, 1840, John Campbell’s negroes were sold.
In April 1841, the court notes reflect that John’s estate was now worth $2897.64 and two thirds cents.
In July 1841, Wiley Huffaker was the guardian to the children of Elizabeth Campbell Dodson, deceased, and Lazarus Dodson.
Feb 1843 – Settlement of the estate of John Campbell by William Fugate and Jacob Campbell admin. Amount given to each heir of John Campbell as received by them in the lifetime of said deceased.
- Jacob Campbell $210.00
- George Campbell 103.65
- Lasarous (Lazarus) Dotson 192.75
- Preston Holt 170.16 and a half cents
- Jane Freeman 43.50
- Elmire Pearson 124.50
- William Campbell 214.00
- Martha Jones 65.75
This is a great list, as it shows that John Campbell loaned or gave his children part of their inheritance early.
Jacob Campbell, George Campbell, Jane Freeman, Jefferson Pearson, Preston Holt and Jane Campbell sell to William Campbell for $33.03 and 1/3 cents negro boy Charles which John Campbell died seized and possessed and Jefferson Pearson and Preston Holt having interest in said negro by their marriage with daughters of said John Campbell. Signed except Jane who makes mark of a plus sign. Witness Gray Garrett and Hugh Dobkins and registered Jan. 13, 1840.
In October 1843, a final settlement was made with the children of Elizabeth Campbell Dodson which lists her children, by name.
On Jan. 24, 1852, William Campbell sells to Daniel Jones of the same for $1300 the land where Daniel Jones now lives including the residence of John Campbell decd lying on Little Sycamore Creek including part of 2 grants, one to Alexander Outlaw and the other to Abner Chapman, beginning….southwest corner of Outlaw grant…closing line of Chapman grant…conditional corner between William Campbell and Daniel Jones…Outlaw grant. Signed. Registered March 10, 1852. Witness Tennessee Cook and William Fugate.
This last deed clearly identifies which John Campbell we are talking about. I brought these deeds forward in time, hoping to find a landmark of some sort that I could locate today. I was very lucky. Skipping several transactions, I found this:
1903 – Jane Ann Jones et all to G.R. Sulfridge – deed of trust – all the old Daniel Jones home farm and tract deeded to Ann Jane Jones except that previously deeded to H. Friar and others, beginning at Sycamore Creek at Nancy Coles, Nancy Cooks line, across ridge to John Cunningham’s line, Buis corner, top of ridge, George Runions, Friar’s line, public road in Little Sycamore Valley, except the grave yard plot of 3/4 acre deeded to Liberty Church, 140 acres.

The Liberty Church! I knew exactly where that was located. Here’s a photo of some of the old settlers and the Old Liberty Church taken about 1902. The church itself was founded in 1856 and the building in this photo was built in 1883, so this church did not exist when John Campbell was alive, but the fact that the cemetery was deeded to the church helped us locate John’s land.

The Liberty church sits down on Little Sycamore road, but the cemetery sits up on a ridge beside the church and directly behind John Campbell’s house.
From this vantage point, you look down over the valley. It’s quite beautiful! John Campbell might be buried here.

This photo, below, is John’s house from in the cemetery.

It’s very likely that when John died, William Hicks made his casket, someone preached his funeral, and John was carried up the hill, probably in his wagon by his own team of oxen, and he was buried right here, forever standing silent sentry, looking over his land from what is called Little Ridge.
Here’s the house from the road. My cousin, Daryl and I went to visit. Once we discovered the landmark of Liberty Church, we couldn’t NOT visit.

The cemetery stands above the house on top of the ridge.
This was a prime piece of real estate, because it had a natural spring which still flows today. The head of the spring is under the rocks and you can see that it has hollowed out a bed downstream.

You can see the stream here, located in front of the house, where it’s not far to carry fresh water to the house.


The current owners were very gracious allowing us to photograph the property and answering many questions.

You can easily see the original house in the center. The owners told us the center part is made of logs.

We asked about this odd part of the foundation and discovered that there is a hidden “room” under the house. The owners told us that they had been told that it was for travelers from long ago so that they could stay someplace without disturbing the household if they arrived at night. I wondered about the Civil War because this area was rife with marauding soldiers from both side and many families have stories about hiding from the soldiers.

The door into the original cabin and the original steps. Most of the steps in this region are stones like this. I have the stone from one of my ancestor’s cabins that is now my back step. I’m not sure how I’d have gotten this one in my Jeep, but had it been offered, Daryl and I would have found a way, rest assured!
George and John Campbell, Brothers or Not?
One enduring mystery is the relationship of George Campbell and John Campbell. If you believe Fulkerson, and there isn’t any reason not to, they married Dobkins sisters, but what he did not say was that they were brothers, although based on the joint deed from Charles Campbell, the timing and the enduring relationship between the Campbell men, it’s certainly a logical conclusion. But is it accurate?
One fine day, when Daryl and I were researching on one of our many library trips, we stumbled on one right juicy lawsuit in which the divorce of one of John Campbell’s daughters is discussed. It seems that one fall during “hog killing,” while married, she was “discovered” in a compromising position in the barn with her Campbell cousin, George’s son, who was named and identified as her cousin. Woohooo…..our lucky day. Until we realized that John’s daughter and George’s son would have been cousins through their mother’s as well. If John and George were brothers then their children would have been double first cousins. Thankfully, she apparently didn’t get pregnant from the encounter, just divorced. I bet that was the talk of the neighborhood for a very long time.
These families didn’t live far apart. It was closer over the mountains, and they had wagon trails and roads across the ridges that don’t exist today.
On the map below, the red arrow at left shows the approximate location of the land of George Campbell on Russell Creek. The top arrow shows Jacob Dobkins land and the bottom arrow shows the circle drive today around the cemetery above John Campbell’s home. These properties were about 3 miles from each other, John’s being “across the ridge” from the others.

I turned to DNA hoping that perhaps I could discover something more about the relationship between John and George Campbell. Maybe, if I was lucky they would have a family mutation that linked them. Maybe, today, they would match exactly to a family line out of Virginia. When the descendants of both George and John were first Y DNA tested, several years ago, we certainly weren’t that lucky.
John’s descendant who tested is Jim Campbell and George’s descendant is Paul Campbell.
I would expect both Jim and Paul to match closely. They do match, but not closely.
Both men are 5 generations from their oldest known ancestor, meaning John and George, so they would be 6 generations from a common ancestor if George and John are brothers.
At 67 markers they have 4 mutations difference. This would be expected, at the 50th percentile, at about 8 generations, using the TIP tool at Family Tree DNA. Of course, I’ve discussed this tool, its drawbacks and the fallacy of averages, but sometimes it’s the only tool you have and it’s certainly better than nothing.
At 37 markers Jim and Paul have 2 mutations, at 25 markers, they aren’t shown as a match, so that means 2 mutations (deduced because that is what they have at 37). They are not showing as a match at 12 markers either, so more than 1 mutation difference in the first panel.
Moving to the Campbell DNA project, I can see the DNA results for the group that the administrator, Kevin Campbell has grouped both Jim and Paul into. Fortunately, it is the same group, R1b-group 30.
Comparing their results with others in the group, we see that Jim (yellow 80569) has several mutations, and Paul (blue 81430) seems to match the modal value perfectly, so in essence has had no mutations since the common ancestor of this group.
Paul is the closest match to kit 23564 whose oldest ancestor is:
David J. Campbell, a son of Mark Washington Campbell and Mary Ann Campbell, was born on 26 August 1846 in Franklin County, PA. It is speculated that he was born in Dry Run. Also, according to speculation, his father, Mark W. Campbell, was born 15 December 1815 in the same county. David married Marie Edna Gribble in 1870 and had six children. The family migrated to Clinton County, IA, McLean County, IL, Kearney County, NE, and Payette County, ID.
Jim’s closest match has 3 mutations, which isn’t terribly close, kit 28877 whose oldest ancestor is:
Solomon Campbell born Sept 1805, married Margaret Laurie, John N’s son James N Campbell Born Feb 2 1835. Other children of John N are Martha, William, Margaret, Thomas L., James N., Solomon J., Jane. It states on the 1841 Scottish census (Crofthead, Neilston, Renfrewshire) that John N and family were born in Ireland except for Jane who was born in Neilston. Family also listed in Scotland 1851 census. Came to America in June of 1853, settled in Mason NH, John N. died 1878 Townsend Mass.
There is clearly no commonality in terms of either ancestors or location comparing the two closest matches. Furthermore, Jim’s closest match is in Massachusetts when we know that John Campbell did arrive from Virginia, born in the 1770s, and was very likely part of the Scots/Irish migration from Pennsylvania through Virginia – simply given the historical patterns and logistics.
Let’s move to the individual markers and see what we can tell.


I looked at the markers, and I think that DYS389(2) is having spontaneous mutations. I say this because IF and assuming that truly, kit 81430 has not mutated, then all of the mutations in the 80569 kit happened after Charles Campbell who was born about 1750 or maybe slightly earlier. It’s obvious from looking at oldest ancestors of the matches who have a value of 31 at DYS389(2) that they could not all be descended from someone who lived since Charles Campbell.
Both Paul and Jim have taken the Family Finder autosomal test. Let’s see what that says about their relationship. I searched Jim’s account for matches having a surname of Campbell. Sure enough, there were 5 results, but none of them were Paul. These men should be 5th cousins if Charles Campbell is the father of both John and George. That is a long way back and we would expect, on average for 5th cousins to carry only about 3cM of common DNA and less than 1%. The FTDNA threshold is 7cM.
Jim’s sister has also taken the Family Finder test. On the chance that she inherited differently, I checked to see if she perhaps matches Paul. She does not.
We know that at Family Tree DNA matching threshold is set to approximately 7cM and that matches have to meet other criteria as well to be considered a match, like minimum SNPs and a minimum total cM as well. Therefore, people with small amounts of matching DNA are not shown as matches at Family Tree DNA, but may share DNA that is important to find. At GedMatch, you can set the matching thresholds yourself.
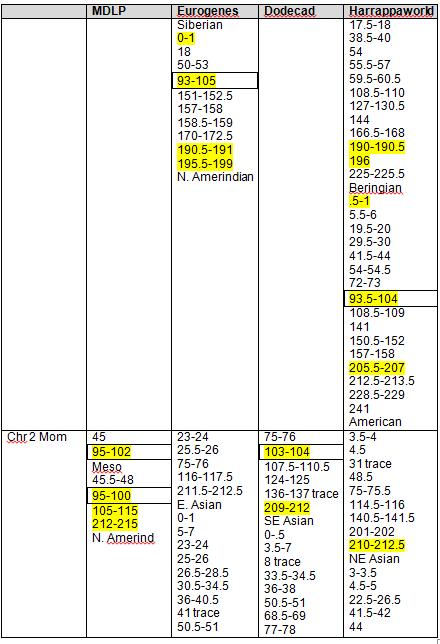
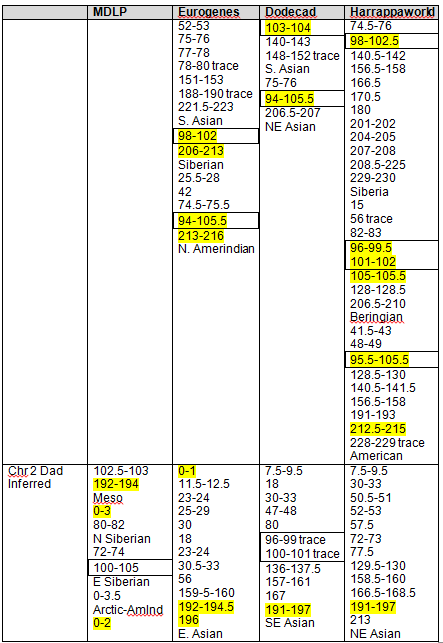
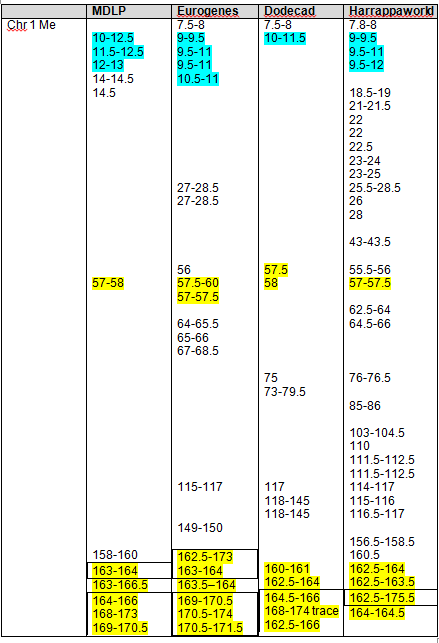
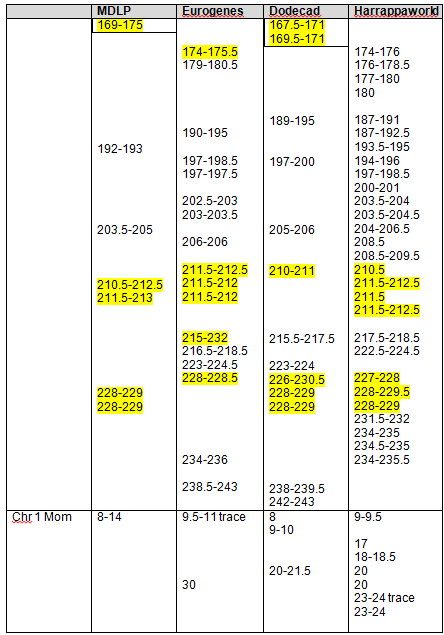
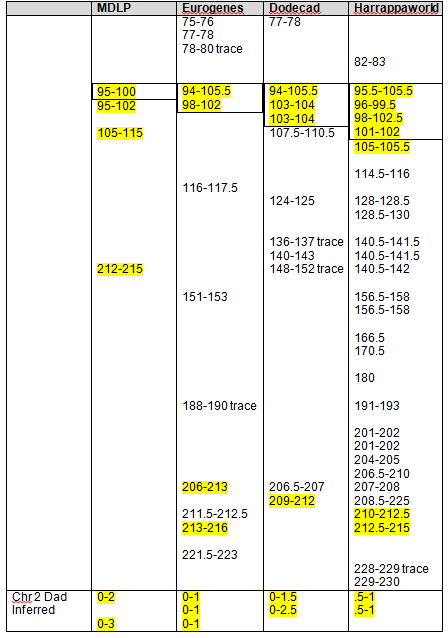
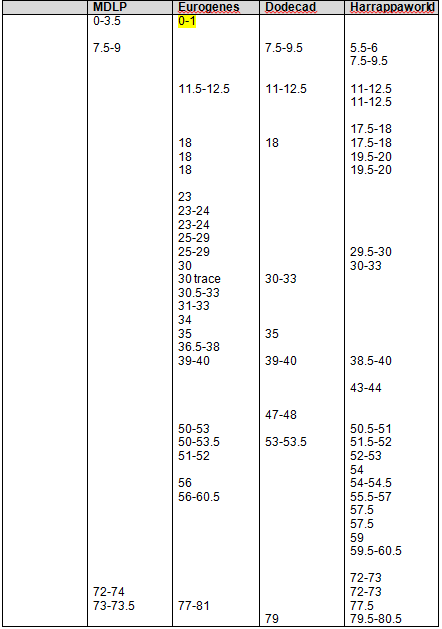
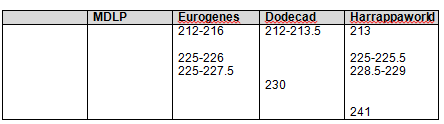
Let’s take a look at GedMatch to see if the John Campbell descendants match the George Campbell descendants. Below, Jim and Paul’s autosomal DNA is compared for matches.

Sure enough, Jim and Paul match each other on four segments, one just above 3cM, just as predicted, and three more just over 1cM each. Without a proven family connection, we would ignore segments of this size, but in a known family situation, these are important matching segments.
Let’s see if Jim’s sister matches Paul.

Yes, Jim’s sister and Jim both match Paul and in the same location on chromosome 7.
Do I match Paul?

I do match Paul significantly. On two chromosomes, the segments are 12 and 13 cm. On chromosome 12, I match Paul on the same location at Jim’s sister. On chromosome 13, I match on the same location as Jim matches Paul.
The GedMatch estimate is interesting in that it is 4.2 generations. We know positively that we are a minimum of 7 generations distant, assuming that Charles is the father of both George and John. Paul and I do not share any other ancestors.
Do I match Joy, the other George descendant?
Yes, I do, below. Again, a minimum of 7 generations between us.

Does Jim match Joy? No.
Does Joy match Jim’s sister? No.
Does Paul match Joy? Both are descended from George. Yes, on 10 different chromosomes. These should be more closely matched than any John/George descendant matches, but they are further than 2.7 generations.

Do I match Jim, who is also descended from John Campbell? Yes.

Do I match Jim’s sister? Yes, on far more segments that I match Jim.

The segments on chromosome 5 are identical between me, Jim and his sister. Clearly, that came from John Campbell. Our common ancestor, John Campbell is 5 generations from Jim and his sister, and 6 from me.
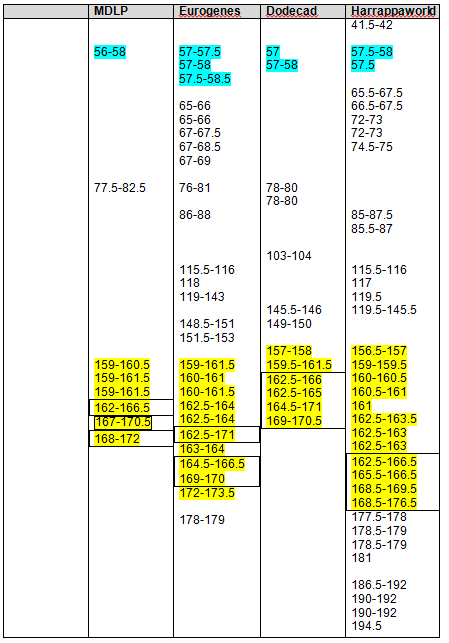
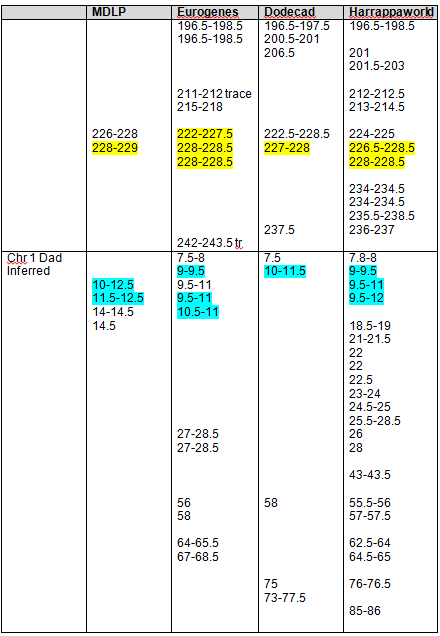
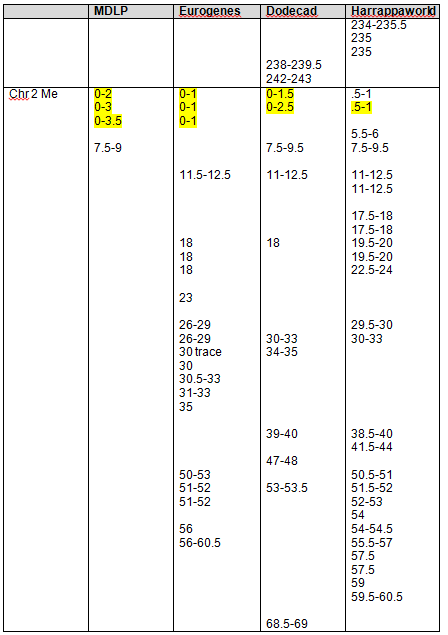
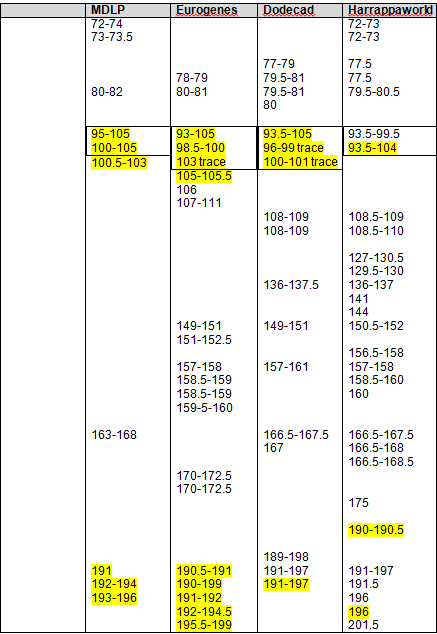
I created the following table of the results. We have two descendants from George who match each other most closely. Conversely, the descendants of John match each other more closely than the descendants of John match the descendants of George. However, given the generational distance, the descendant of John and George do fall into the expected tolerance in the case of Paul matching Jim, John and me.
|
Jim (John) |
Jim’s sister |
Paul (George) |
Me (John) |
Joy (George) |
| Jim |
na |
siblings |
1,3,7,13 |
5, 7, 11, 15 |
No |
| Jim’s sister |
siblings |
na |
7, 10, 12, 13 |
2, 3, 5, 10, 11, 12, 13 |
No |
| Paul |
1,3,7,13 |
7, 10, 12, 13 |
na |
4, 9, 10, 12, 13 |
1, 2, 3, 5, 6, 7, 9, 12, 15, 16 |
| Me |
5, 7, 11, 15 |
2, 3, 5, 10, 11, 12, 13 |
4, 9, 10, 12, 13 |
na |
16, 17 |
| Joy |
No |
No |
1, 2, 3, 5, 6, 7, 9, 12, 15, 16 |
16, 17 |
na |
What else can we do now to further identify the parents of John and George Campbell, presuming that they are indeed brothers as the results above suggest?
At this point, there are three avenues open for study.
- Upgrade both Jim and Paul to 111 markers and hope for line marker mutations.
- Upgrade both Jim and Paul to the Big Y hoping for identical mutations, and if not, ones that will connect to another Campbell line. This option is very expensive at this time, and according to the Campbell surname administrator there are either few or no project members who have ordered the Big Y.
- Utilize Family Finder to search both Jim and Paul’s matches for consistent matches and hope for a clear genealogy clue as to where to begin the search for the common family of John and George.
- Add a dash of luck!
One thing is certain, whether John and George share a father or not, and whether that father is Charles Campbell who died before 1825 in Hawkins County, TN, or not, they do at some point not terribly distant past, share a common Campbell ancestor. I surely wish there were any other proven children of Charles Campbell to test against.
As a matter of curiosity, I did check to see if any of the five of us Campbell descendants have matches to people with Fugate as an ancestral surname – and we all do. However, many of these people also have Campbell ancestry and/or are from the Claiborne County region where we all have roots, so it would require more research to draw any inferences or conclusions on the Fugate question.
The Campbell lineage has been exceedingly frustrating. Why, oh why, didn’t they register that deed in 1825 in Hawkins County listing the heirs of Charles Campbell???
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
Genealogy Services
Genealogy Research

























































































{kind=link}
{kind=link}
{kind=link}