Margaret Elizabeth Lentz was born on December 31, 1822, New Year’s Eve, in Pennsylvania, probably in Cumberland County near Shippensburg, to Jacob Lentz and Johanna Fridrica Ruhle or Reuhle. Her mother went by the name Fredericka for her entire lifetime, with the exception of the 1850 census where she was listed as Hannah. Using the middle name is the normal German naming pattern.
Margaret Elizabeth, however, was different, parting for some reason with German naming tradition, she was always called by her first name, Margaret.
Margaret was the 7th of 10 children born to her parents, although two of her siblings had died before she was born. Her brother Johannes died as a small child in Germany in 1814, just two and a half years old. In 1813, Fredericka had a daughter, Elizabeth Katharina who would die on the ship coming to America at age 4 or 5. It appears that Margaret Elisabeth was named, in part, for her deceased sister.
Jacob and Fredericka had immigrated from Germany, beginning in the spring of 1817 and finally arriving in January 1819 after being shipwrecked in Norway and surviving two perilous voyages. Their trials and tribulations arriving in America are documented in Fredericka’s article. In 1822 when Fredericka had Margaret, the couple would have completed their indenture to pay for their passage and would likely have been farming on their own, although we don’t find them in either the 1820 nor the 1830 census in either Pennsylvania or Ohio.
Pennsylvania to Ohio
Jacob and Fredericka and their entire family moved from Shippensburg to Montgomery County in about 1829 or 1830.
Fredericka would have been about 7 or 8 years old and probably found riding in a wagon to a new home in a new location quite the adventure. Perhaps she laid in the back on her tummy, kicking her bare feet in the air and watched the scenery disappear. Or perhaps she rode on the seat with the driver, probably her father or oldest brother, and watched the new landscape appear in the distance. Maybe she cradled a doll on her lap, or maybe a younger sibling.

At about 10 miles a day, the trip would have taken about 40 days. They may have made better time, or worse, depending on the weather.
Margaret’s mother may have been pregnant for her last sibling, Mary. For all we know, Mary may have been delivered in that wagon. I shudder to think.
We find Margaret’s parents on tax records beginning in the mid-1830s in Madison Township in Montgomery County, Ohio where they would purchase land from their son, Jacob F. Lentz in 1841.

Cousin Keith Lentz provided the 1851 tract map above with an arrow pointing to Jacob Lentz’s land, with his name misspelled, but located in the correct location on Section 3, according to deeds.
Brethren
We don’t have much direct information about Margaret during this time, other than we know the family was Brethren. Jacob and Fredericka had been Lutheran when they left Germany, according to church records, but sometime after that and before their deaths, they converted to the Brethren religion.
Their two oldest children were not Brethren, but the rest of their children were practicing Brethren for the duration of their lifetimes, except for the youngest, Mary, who died a Baptist in Oklahoma – although she assuredly was raised Brethren if her older siblings were.
Jacob and Fredericka’s eldest children, Jacob L. and daughter Fredericka, were born in 1806 and 1809, respectively. Son Jacob remained Lutheran for his lifetime, from the age of 17, according to his obituary. This suggests that perhaps his parents converted when Jacob F. was a teenager, so maybe in the early/mid 1820s. If that is the case, Margaret would have been raised from childhood in the Brethren Church, so she likely never knew anything different.
The Brethren, as a general rule, avoided records like the plague, including church records and what we know today as civil records. They didn’t like to file deeds, wills and especially did not like to obtain marriage licenses. However, because Jacob and Fredericka did not begin life as Brethren and the German Lutherans recorded everything, perhaps they were more tolerant of those “necessary evils.” At least some of their children did obtain marriage licenses and deeds were registered, albeit a decade later, although Jacob had no will.
The Happy Corners Brethren Church was located about two miles from where Margaret lived with her family, at the intersection of current Shiloh Springs and Olive Road on the western edge of Dayton. At that time, Happy Corners was known as the Lower Stillwater congregation, named for nearby Stillwater River.

The current church was built in 1870. At the time Margaret attended, the church was a log cabin and Margaret had moved to Indiana decades before the new church was built.
Marriage
Margaret is recorded in the 1840 census with her family, or at least there is a female recorded in an “age appropriate” location for Margaret. On the last day of 1840, her 18th birthday, she married Valentine Whitehead III, the son of another Brethren family.
I can’t help but wonder if there is some significance to the fact that she married ON her 18th birthday. Was her family for some reason opposed to the union and this was the first day she could marry without her father’s signature? Did he refuse to sign on “Brethren” principles or for some other, unknown, reason?
Was this birthday marriage a celebration or a not-so-covert act of rebellion?
Valentine Whitehead was born on February 1, 1821, so he was about 23 months older than Margaret.
The Whitehead land can be seen on the 1851 plat map about a mile and a half distant from Jacob’s land, in section 12, to the east. The families would have been near-neighbors and given that there was only one Brethren Church in the vicinity, they assuredly attended the same church. Margaret and Valentine had probably known each other since they were children.
Elkhart County, Indiana
The newly married couple wasted little time leaving Ohio and settling in Elkhart County, Indiana. That trip took between a week and two weeks by wagon according to other settlers who undertook that same journey. They were among the pioneers in Elkhart County, but they weren’t the first who had arrived nearly a dozen years earlier and spent their first winter in lean-tos before they could build rudimentary cabins. Many of the earliest families were Brethren too, so by the time Margaret and Valentine arrived, a community had been established for a decade, was welcoming and thirsty for news and letters from “back home.”
An excerpt from the book, “The Story of a Family, Argus and Myrtle Whitehead” by William Eberly and Eloise Whitehead Eberly published in 1986 reads:
Adam Whitehead (Margaret’s brother-in-law) Whitehead…decided to leave Montgomery County and go west. he came to northern Indiana to seek land for himself and others in his family and purchased about 2000 aces west and soth of New Paris, in Elkhart County. Between 1832 and 1836, nine of he Whitehead brothers and sisters and their families moved to the New Parish area. The migration included Adam, John, Esther W. and Jacob Stutsman, Samuel, Peter, Lewis, Valentine III (Margaret’s husband), Mary W and Solomon Conrad nd Margaret W. and Adam Lentz.
Most (if not all) of thes families were members of he German Baptist Brethren church, now known as the Church of the Brethren. A churchhouse was uilt in 1854 n this Whitehead community which was known for a long time as the “Whitehead Church.” Peter gave half of hte land for the church building (the east side) while Lewis gave the west. John gave land on the north of the road for the cemetery. Jacob Miller, the son-in-law of Lewis Whitehead was he head carpenter. The church and cemetery are located about the middle of the second mile wes of State Road 15 and County Road 46, southwest of New Paris. At first it ws one of the meeting houses of he Turkey Creek congregation, but in 1906 it becaem a separate congregation, taking the name of Maple Grove.
The original Whitehead churchbuilding was abut 36 by 44 feet, with no basement. The church was built with two doors on the north end of he building, one on each side of the center, oen for men and one for women. The men sat on the left side of he meetign house after coming in the door on the left. The women sat on the right. There were exceptions, however. At funerals the family could sit togethre and when young men brought their girlfriends, they could sit goether on the women’s side. Sometime later the two doors were boarded up and a large double door was put in the center of the churchbuilding. Still, for a long time, the men still sat on one side and the women on the other. A small kitchen was added on the south end of the building in which the communion beef was cooked and to store the communion utensils.

The church, her husband and her children defined Margaret’s first several years in Indiana.
Early Life in Indiana
The 1850 census suggests that Margaret and Valentine can both read and write. The final column showing to the right of the form designates ” persons over 20 years of age who cannot read and write.” That column is not checked. What we don’t know is whether than means English or German, or both. We also don’t know how well they might have understood the census taker if the census taker didn’t speak German.

The 1850 census confirms that Margaret’s first child, Lucinda, was born on December 13, 1842 in Ohio, but her second child, Samuel, was born a year later in Indiana, as were the rest of their children. From this, we know that sometime between December 1842 and June 1844, at the ripe old age of 21 or 22, Margaret, Valentine and their baby made their way to the frontier grasslands of Elkhart County. She too may have been pregnant on that wagon ride.

I have to wonder if Margaret ever saw her parents again. It’s very unlikely even though they only lived what is today about a 4 hour drive. There were men who made the trip back and forth a couple of times on horseback, bringing news and shepherding more settlers, but women were tied at home with children and tending livestock.
Margaret’s parents didn’t pass away for another 20+ years, 1863 for Fredericka and 1870 for Jacob, so Margaret would have spent a lot of years of missing them, or perhaps sending letters back and forth. Receiving a letter telling you about the death of your parents would be a devastating letter to receive. I can only imagine the excitement of receiving a letter combined with the dread of the news it might hold. Talk about mixed emotions. Did her hands shake as she opened letters as her parents aged? Was she able to read the letters herself, or did she have to have someone read them to her?
When I was a young mother, I was constantly asking my mother something…for family recipes, advice about how to deal with childhood illness or tantrums of a 2 year old, exasperating husbands, and more. I talked to Mother by phone or in person at least once a day. While I was all too happy to leave home as a teen, I grew up quickly and can’t imagine leaving my mother at that age, knowing I would never see or speak with her again. I left the area where my parents lived in my mid-20s, and it nearly killed me, even with telephones and returning to visit every couple of weeks, for decades. There is nothing like the security of knowing Mom lives nearby.
I don’t know if Margaret was brave or foolhearty. Regardless, she would have formed other bonds with older women with advice to offer within the church in Elkhart County. Furthermore, nearly all of the Whitehead family settled in Elkhart County, including Valentine’s parents and most of his siblings, one of whom was also married to Margaret’s brother, Adam. Adam Lentz married Margaret Whitehead who then became Margaret Lentz, which caused a great deal of confusion between Margaret Lentz Whitehead and Margaret Whitehead Lentz.
Adam’s wife, Margaret Whitehead Lentz, died in Elkhart County on July 17, 1844 and is buried in the Whitehead Cemetery under the name of Margaret Lentz and was mistaken for our Margaret Lentz Whitehead for many years.

We know that our Margaret spoke German, possibly exclusively, as she lived in a German farming community. The Brethren Church in Elkhart County was still holding German language services into the 1900s and the Brethren families still spoke German, although by then, they spoke English too. My mother remembered her grandmother, Margaret’s daughter Evaline, speaking German, but her primary language by that time, in the 1920s and 1930s, was English.
The first Brethren church services in Elkhart County were held in private homes and barns, so it’s entirely possible that Margaret took her turn and had “church” at her house, with the entire neighborhood attending and then having a good old-fashioned German “pot-luck” afterwards.
The Whitehead School was established in 1836.
From the book “Elkhart County One Room Schools, The 3 Rs” by Dean Garber, I found the following:
Whitehead School, district #6, began on he west side of present day CR 19 north of CR 48 in Sect 17. Samuel Whitehead 1811-1874 settled in what became known as the Whitehead settlement, southwest of New Paris, Indiana. About 1836 a round log cabin with a clapboard roof was built on his property. This first schoolhouse was about 12X16 in size and was replaced by a wood frame building and was in use until the 1880s when it was replaced by a brick school building. For some reason this school is not shown on any of the county maps before 1874. But it has been found that David B. Miller born in 1838 did attend this school in 1854. This school closed in 1913 because of the consolidation of the township schools.
In the 1850s, Valentine Whitehead taught at this school.
This 1874 plat map of Jackson Township in Elkhart County, below, shows a school on the D. Whitehead property on the northeast corner of Section 8, and the “D. Ch” across from a cemetery on the border between sections 8 and 17. “D Ch” means Dunker Church and the cemetery across from the church is the Whitehead Cemetery.

The Whitehead descendants erected a marker in the cemetery in 1939 commemorating the early Whitehead settlers.

The verbiage on the commemoration stone says that 9 of Valentine Whitehead’s children settled in Elkhart County with him, including Valentine Jr. and his wife, Margaret Lentz. Three of Valentine Sr.’s children remained in Ohio. According to Whitehead genealogists, the Whitehead family began purchasing land in Elkhart County the 1830s and moved from Ohio in the early 1840s. It’s likely that they formed the “Whitehead Wagon Train” and all relocated together to the prairie frontier so that they could mutually assist each other with clearing land, building homes and establishing farms. Land was plentiful in northern Indiana, but was all taken in Montgomery County, Ohio.
Cousin Keith Lentz visited Elkhart County in 2015 and located the land owned by Valentine Whitehead and Margaret Lentz Whitehead near the intersection of County Roads 50 and 21. Margaret’s brother, Adam Lentz who married Margaret Whitehead, owned land just a couple miles up the road.

Thanks to Keith for providing this map.
Valentine Dies
The first decade of Margaret’s married life blessed her with 4 children and a migration to the Indiana frontier. Valentine and Margaret became established in their new community and like all farm families, lived by the routine of the seasons and the Sundays. Sunday was church and sometimes a bit of leisure or rest. Baths in washtubs were taken on Saturday night, hair was washed, and on Sunday morning, women wore their best dresses and prayer bonnets and rode in the wagon to church, after feeding the livestock of course. Little changed in the next hundred years, except you rode to church in a car or buggy.
The rest of the week was work from sunup to sundown, and sometimes longer by candlelight.
However, life was not to remain rosey for Margaret.
Margaret, the bride at 18 was a widow at 29 with 4 children and one on the way. Margaret was 2 months pregnant for Mary when Valentine died. Mary was born in February 1852 after Valentine’s death on July 24, 1851.
Margaret buried Valentine in the Whitehead Cemetery, just down the road from where they lived and across the road from the church she attended every Sunday. I wonder if she sat in church and stared out at the cemetery, where he lay. Did she wander over to visit his grave every Sunday after the church was built in 1854?
I surely wonder what took Valentine at age 30 in the middle of summer. I wonder about things like appendicitis, farm accidents, falling from a horse or perhaps something like typhoid. The only clue we have is that Valentine did write a will on June 3rd, 1851, recorded in Will Book 1, page 59 and 60 wherein he does not name his wife but does name children Lucinda, Jacob, Samuel and Emanual. This executor was Adam Lantz (Lentz) and Samuel Whitehead and Robert Fenton were the witnesses. If Valentine was ill, then he was ill from June 3rd until August 10th when he died.
In the book, “The Midwest Pioneer, His Ills, Cures and Doctors” by Madge Pickard and R. Carlyle Buley published in 1946, we discover that Elkhart County was plagued by “bilious disorders” and typhoid.
For fifty years after their first settlement the river towns along the Ohio and the Wabash suffered from malarial diseases.
In the middle 1830’s the people of Elkhart County had an epidemic of typhoid and pneumonia and in 1838 almost half the population was affected with bilious disorders. The wave of erysipelas which enveloped the whole Northwest in the early 1840’s struck Indiana with unusual severity. Dysentery, scarlatina, phthisis (consumption), pneumonia, bronchitis, occasionally yellow and spotted fevers, whooping cough, and diphtheria appeared in many parts of the state. The summer of 1838 was a bad one, and “the afflicting dispensations of Providence” laid many low along the Ohio, the Wabash, the Illinois and lakes Michigan and Erie.
The Milwaukee Sentinel of October 9, 1838, boasted that, notwithstanding the fact that the season had been bad in most sections, Wisconsin had no prevailing diseases. The Sentinel and the Green Bay Wisconsin Democrat reported that canal work had been suspended in Illinois and Indiana, that the people were much too sick to harvest crops, and that there was nothing that looked like life, even in the populous towns. The Daily Chicago American, May 2, 1839, declared that “the whole West was unusually sickly” the preceding fall, that Michigan, Ohio, and Indiana suffered most, but that Illinois was affected only among the Irish laborers along the canal lines.
There were those who felt that the habits of the settlers were as much to blame for prevailing illness as the environment. James Hall of Vandalia, in years to come to be the West’s most famous historian and advocate, took this view. In his address at the first meeting of the Illinois Antiquarian and Historical Society in 1827 he stated that the pioneer’s exposure to the weather, his food — too much meat and not enough fresh vegetables, excessive use of ardent spirits, and lack of attention to simple diseases, were more responsible than the climate.
Again in 1845 came a “disastrous and melancholy sickly season” in the West; the South Bend St. Joseph Valley Register noted that it was the seventh year from the last bad outbreak, as if that explained it.
Granted, this doesn’t say anything about 1851, but it is suggestive of a recurring health issue in this area – and the family did live along Turkey Creek which fed the Elkhart River, emptying in a swampy area a few miles distant.

Margaret’s children with Valentine were:
- Lucinda born Dec. 13, 1842
- Samuel born January 7, 1844
- Jacob Franklin born October 10, 1846
- Emmanuel born January 15, 1849
- Mary J. born February 11, 1852
The book Pictorial and Biographical Memoirs of Elkhart and St. Joseph Counties of Indiana published by Goodspeed in 1893 says:
Valentine Whitehead removed to Indiana at an early day, having married Margaret Lentz in Ohio and settled on a woodland farm of 160 acres in Jackson Twp., Elkhart Co, which he did much to improve prior to his death which occurred July 24, 1851. He was a member of the German Baptist church, a democrat in early life and afterward became a Republican in political principles, although he but seldom exercised the privilege of suffrage. Five children were the result of this union, Lucinda wife of Joseph B. Haney was born Dec 13, 1842, Samuel, a carpenter of Goshen was born in 1845, Jacob is a farmer of Bates Co, Missouri, Emanuel of Kosciusko Co., Indiana is married to Elizabeth Ulery by whom he has 4 children, Argus, Jesse, Clayton and Calvin. Mary J., born February 11 1852, is the wife of John D. Ulery. After the death of her husband, Mrs. Whitehead married John D. Miller of New Paris who was born near Dayton Ohio in 1812, a son of David Miller. To her union with Mr. Miller 3 children were born, Evaline, Ira and Perry. Mr. and Mrs. Miller are residents of Jackson Twp., Elkhart Co.
We don’t know how Margaret survived after Valentine’s death. Her children were too young to help on the farm, at least not significantly, the oldest being 9.
However, Margaret’s father-in-law and eight of Valentine’s siblings lived in close proximity, as did some of Margaret’s siblings.
- Adam Lentz and his wife, Margaret Whitehead were in Elkhart County by 1844 when Margaret Whitehead Lentz died. Adam remarried to Elizabeth Neff in 1845 and remained in Elkhart County until sometime between 1867 and 1870 when he moved on to Macoupin County, Illinois.
- Benjamin Lentz moved to Elkhart County between 1854 and 1859 and remained until his death in 1903.
- Margaret’s sister Mary who was married to Henry Overlease (Overleese) moved to Elkhart County between 1852 and 1854. She and Henry moved on to Illinois between 1866 and 1870.
- If Louis or Lewis Lentz was Margaret’s brother, he was living a couple counties away, in Peru in Miami County – too far away to help Margaret. He moved from Ohio between 1857 and 1859.
Marriage to John David Miller
Five years later, on March 30, 1856, Margaret Lentz Whitehead married the Brethren widower, John David Miller. His wife had died a year earlier, in March of 1855, leaving him with 7 children, ages 4 to 22.
The Lentz and Miller families were both from Montgomery County before arriving in Elkhart County, so not only did they know each other, their families knew each other the generation before as well. Margaret and John David probably knew each other as children and attended the same church, although he was a decade older than Margaret.

At the time of their marriage, their living children were stairstepped.

Hester Miller had already married, but the rest of the children were at home when Margaret married John David Miller. They had 11 children living with them between the ages of 4 and 18.
The 1860 census in Elkhart County shows the two families merged. This census indicates that John David Miller can read and write, but Margaret cannot.

It’s no wonder census documents confuse genealogists. This was a blended family and although Margaret’s children from her first marriage are listed last, they are not listed with their Whitehead surname.
Three of Margaret’s children are listed, but two are missing. Jacob Whitehead was born in 1846, so would certainly still be living at home in 1860 as would Samuel who was born in 1844. Where are these children? They aren’t found living with relatives or elsewhere in the county either, and we know they survived to adulthood.
Furthermore, John D. Miller’s age looks for all the world to be 21, but he was 47. Maybe they wrote the 4 and forgot the 7. Lastly, some of the children’s ages are illegible as well, and Martha Miller, who would have been age 13, is missing entirely and we know she lived to marry and have children.
Margaret Lentz and John David Miller have had two children of their own by 1860, Louisa Evaline born March 29, 1857, my mother’s grandmother, and Ira, born July 26, 1859.

In the 1870 census, the last child born to Margaret and John David Miller, Perry, is also shown. I wonder where they came up with that name? It’s certainly not a family name. Perhaps Brethren naming traditions were changing a bit.
According to Rex Miller, Ira Miller’s grandson, Perry Miller born in 1862 died at the age of 18 from appendicitis, so about 1880.
The 1870 census does not show that Margaret is unable to read and write.
The 1880 census shows Margaret and John Miller with their three youngest children and a Whitehead grandson.

The 1880 census indicates that Margaret cannot read and write.
The 1900 census is our last census glimpse of the family before John and Margaret’s deaths. By now, both John and Margaret are elderly, with no children or grandchildren living with them. At their age, I don’t know if that is a blessing or a curse.

The 1900 census may hold the key to why 2 of the past 4 census schedules said Margaret could read AND write and 2 said she could not. In 1900, the categories of read and write are separated and the census says Margaret can read but cannot write, and that she can speak English. It also tells us that they have been married for 45 years, and that Margaret has had 9 children, with 8 living.
This also gives Margaret’s birth year and month as December 1821 which is a little perplexing because her death certificate gives her year of birth as 1822.
Interestingly enough, they had a boarder who was a medicine peddler. You know there’s a story there!
When Margaret married John David Miller, she moved to his farm. I don’t know what happened to the Valentine Miller land, but it stands to reason that his children would have inherited that land (or the proceeds therefrom) as soon as they were of age.
It’s not like Margaret had far to move.
On the 1874 plat map below, you can see the J. Miller (John David) property abutting the D.B. Miller property, in green. D. B. Miller is John David’s brother, David, based on the 1860 and 1870 census.
You can see on the plat map above that John David Miller’s land was about a mile from the school and a little more than a mile from the church. A section of land is one mile square. The land owned by Margaret and Valentine was about another mile and a half or so further south, not shown on this part of the map.
The Whitehead School was located on the western edge of section 5 and 8. Both the Whitehead and Miller children would have attended this school as it was the only school in the area. We know from the census that the children attended school.
The Brethren Church on the Whitehead land was the first Brethren Church, other than meeting within members’ homes, in Elkhart County. Margaret Lentz Whitehead and John David Miller would have known each other for decades, and been well acquainted since moving to Elkhart County. John David, I’m sure, was at Valentine Whitehead’s funeral, and Margaret would have attended Mary Miller’s.
I wonder if Margaret and John David’s marriage was one of love or convenience, or maybe a bit of both. It surely stands to reason that with a combined family when they married of 12 children, many of them small, they both needed a spouse badly in a culture and economy where couples shared work and responsibilities. Farming was almost impossible without a helpmate. Someone had to work the land and do the chores, daily, and someone had to cook and clean and watch the children. One person couldn’t do both.
To help put things in perspective, I’ve created the map below which shows the approximate locations of important landmarks.

The top arrow is the Baintertown Cemetery, also known as the Rodibaugh Cemetery where most of the early Millers are buried including John David Miller, Margaret Lentz Whitehead Miller and John David’s first wife, Mary Baker. It stands to reason that the child born to Margaret and John David Miller that died is buried here as well, although the grave is not marked.
The bottom arrow is the land where Valentine Miller lived with Margaret Lentz Miller.
The arrow above that is the Whitehead Cemetery, also known as Maple Grove along with Maple Grove Church of the Brethren. The arrow directly above that at the intersection of 142 and 21 is the location of John David Miller’s land where Margaret Lentz Whitehead Miller lived for more than half of her life.
The house built by John David Miller which incorporates the cabin first built when he first arrived in the 1830s still stands today. This is where Margaret Miller would live for almost half a century, the most stable period of her life, although it got quite “exciting” towards the end.

This property today is located at 67520 County Road 21, New Paris, Indiana. It sits sideways because the road has been substantially changed since the house was built.

This is the only semi-decent picture we have of either Margaret or John David.
The above people are John David Miller and Margaret Lentz Whitehead Miller seated in the front row. Rear, left to right, Matilda Miller Dubbs, David Miller, Eva Miller Ferverda, Washington Miller and Sarah Jane Miller Blough. Matilda and Washington are children from John David’s first marriage and the other three are Margaret’s children with John David.
Margaret raised the Miller children and was their step-mother for substantially longer than their own mother, Mary Baker, was able to remain on this earth. I think after that long, and after raising step-children as your own, you tend to forget that they are step-children aren’t yours biologically – that is – until something brings it to light…which would happen soon for Margaret.

These are two traditionally garbed Brethen elders, noting her full length skirt, apron and prayer bonnet and his beard, hat and dark clothing.
Rex Miller allowed me to scan this photo of John David Miller and Margaret by their home. The woman looks to be the same person as above and the part of the house looks to be the center section today, which Rex indicated was the log cabin portion.
Margaret was destined to outlive yet another husband.
John David Miller died on Feb. 10, 1902 of senile gangrene. He wrote his will in 1897, but in 1901, before his death, his son David B. Miller filed an injunction in court asking for a guardian to be provided for his father who, in his words, “had a substantial estate and could no longer manage his affairs.” I can only imagine what a ruckus this must have caused within the family. One knows that there had to be some event or situation arise to cause this level of concern. However, before the case was heard, John David died.
John David had a very controversial will that left everything to Margaret until her death, and then one third of John’s estate was to be divided between Margaret’s nephew and Margaret and John David’s three children, with the balance of two thirds of his estate to be divided among his children by his first wife.
Things don’t always work out as intended. By law, Margaret had the right to one third of his estate as her dower, in fee simple, meaning in full ownership. She elected to take her one third as indicated by the following widow’s election. The balance of John’s estate would them be divided according to the will.
Widow’s election recorded on page 111.
The undersigned widow of John D. Miller decd late of Elkhart County Indiana who died testate and whose last will and testament has been duly admitted to probate and record in the Elkhart Circuit Court hereby make election as such widow to hold and retain her right of dower in the personal estate of said decedent and to hold and retain her right to one third of the lands of which her husband died testate notwithstanding the terms of the said will, and she refuses to accept any devise or provision whatever made by said will in her favor, for, or in lieu of her said statutory right as widow in and to the personal property and real estate of said decedent.
Margaret (x her mark) E. Miller
Margaret was no push-over.
Recorded in Deed Book 108-422, Margaret then sells her dower to Eva Ferverdy, Ira and Miley Miller, Perry A. Miller and Edward E. Whitehead for $2241.66 which is 1/3rd of W ½ of NW ¼ and the N ½ of SE ¼ Section 5 Twp 35 Range 6e on Sept. 25, 1902. She probably desperately needed that money to live, in the days before social security and retirement benefits of any type.
Later, recorded in book 112-440, the same group who bought the land above sells the land to George and Alice G. Method for $5000.
Margaret died on July 4th, 1903, just 17 months after John David. I’m sure the stress level on the poor woman with the infighting between her children and his children must have been nearly intolerable. Several of the children lived within the community and it’s not like Margaret could ever get away from the situation. It would have followed her to church, which was likely the only place she ever went. I’m sure it was the talk of the community, and it didn’t end until after her death.
Cousin Rex indicated that Perry died at age 18, but he was still alive when his parents died. In fact, Perry died at age 44 on December 22, 1906 in Goshen.
John David’s estate was controversial, to say the least, and eventually the bank became the estate’s administrator. One of the children, Perry, and Margaret’s nephew, Edward Whitehead, had done a great deal in the years before John’s death to help the elderly couple and had never been reimbursed for their efforts or expenses. They submitted receipts to the estate and those charges were disputed by the older set of children by Mary Baker. There was obviously a great deal of resentment between the two sets of children. Finally, in the end, Washington Miller refused to contribute $10 of his portion of the estate (near $1000 in the settlement) for his father’s tombstone. Edward Whitehead, the nephew, paid Washington Miller’s share. That is surely the last, final insult one could inflict on a parent. Edward Whitehead obviously cared a great deal for his uncle by marriage, John David Miller.
The inventory for John David’s estate is as follows, and the widow took everything except the wheat, rye and corn against her 1/3 dower. Otherwise, she would have been left with, literally, an empty house to live in until she died. At that time, all of the estate was considered to be the property of the man, so the contents of their entire house were listed and valued.
| Number |
Items |
Appraised Value |
| 1 |
Jewell oak heating stove |
4.00 |
| 1 |
Eight day clock |
.25 |
| 1 |
Sewing machine |
.05 |
| 4 |
Rocking chairs |
1.50 |
| 1 |
Bedstead and spring |
1.25 |
| 1 |
Old rag carpet 25 yards |
.50 |
| 1 |
Bureau |
1.00 |
| 1 |
Stand |
.10 |
| 1 |
Bedstead |
.05 |
| 1 |
Bedspring and bedding |
2.00 |
| 1 |
Rag carpet 15 yards |
.50 |
| 1 |
Ingrain carpet 15 yards |
.50 |
| 12 |
Winsor chairs |
1.50 |
| 1 |
Dining table |
.25 |
| 1 |
Cupboard |
.50 |
| 1 |
Dough tray |
.25 |
| 1 |
Kitchen sinc |
.10 |
| 1 |
Hanging lamp |
.25 |
| 1 |
Pantry safe |
.50 |
| 1 |
Churn |
.05 |
| 1 |
Milch trough |
1.25 |
| 15 |
Milch crocks |
.45 |
| 1 |
Lounge |
.05 |
| 1 |
110 lb lard |
11.00 |
| 1 |
Cooking stove and furniture |
.50 |
| 1 |
Cross cut saw and brush cythe |
.05 |
| 1 |
Bucksaw |
.10 |
| 1 |
Log chain |
.05 |
| 1 |
Horse |
3.00 |
| 1 |
Cow |
30.00 |
| 1 |
Ladder and maul |
1.25 |
| 1 |
Wheelbarrow and ax |
.75 |
| 1 |
Spring seat |
.25 |
| 30 |
Chickens |
7.50 |
| 30 |
Acres growing wheat land lord ½ |
150.00 |
| 32 |
Acres rye landlords 2/5 |
40.00 |
| 66 |
Bushels corn |
38.34 |
| 1 |
Small looking glass |
.05 |
| A few |
Old dishes, spoons, knives and forks |
1.00 |
| 20 |
Bushels corn in crib |
9.00 |
|
Total |
309.69 |
This is as close as we’ll ever get to a peek into Margaret’s house. We know from this inventory that she sewed, on a machine, which was valued at 5 cents, the same as a bedstead and half of a kitchen sink. It was worth one fifth of a chicken which was worth a quarter.
Rag carpets were homemade. My mother still made them throughout her lifetime. Ingrain carpets, on the other hand, were commercially made, causing me to wonder about that in a Brethren household too.
I learned to sew on an old treadle sewing machine exactly like the one above, which was likely identical to Margaret’s machine. Electricity wasn’t available in farm country in the early 1900s, so a treadle machine which replaced hand sewing was a true luxury. I wonder how well this “convenience” was tolerated by the conservative Brethren who were very resistant to change.
Margaret Lentz Whitehead Miller died on July 4, 1903 and is buried beside John David Miller in Baintertown Cemetery. It’s sad that her last year and several months were spent tied up in a family conflict that I’m sure mentally consumed her waking hours. She made several trips to the courthouse in that time period and she clearly took care of her three Miller children’s interests relative to their father’s estate.

On one document located in John David’s estate packet, we find the signatures of Margaret plus her three Miller children. Margaret could not write, so she made her mark, a rather unsteady X.
Perry, Ira and Evaline bought their mother’s dower share of the estate and subsequently sold the land. Margaret did not have a will or an estate, so we don’t know what happened to that money, but I’m suspecting that she distributed it among her children before her death. Her children from her first marriage had already shared in their father’s estate and were already well established.

As it turns out, John David’s tombstone was Margaret’s as well, with a small marker on either side for each of his wives.

It has always been stated that Margaret’s middle name was Elizabeth, but given that her daughter’s name was Evaline, now I’m wondering…
Margaret’s Children
Recently, Indiana death certificates have become available through Ancestry. Previously, obtaining a death certificate for someone involved begging, then submitting 2 forms of ID, explaining why you wanted the death certificate, signing a form, swearing you were a direct descendant of that person, and more begging, waiting, and about $30 or so – with nu guarantee of results. Oh and all while patting the top of your head and rubbing your belly while standing on your head…in a corner…taking a selfie.
Now all you have to do is sign on and search, although the indexing leaves much to be desired. Death certificates provide us with a unique view of Margaret’s children, at least those who had the good judgement to die in Indiana. Death certificates begin about 1899 and detecting trends might alert us to a health condition that could be hereditary. Additionally, most death certificates provide a burial location.
1. Lucinda A. Whitehead, Margaret’s oldest daughter, was born on December 13, 1842 in Montgomery County, Ohio. She died on January 30, 1935 in Milford, Kosciusko County, Indiana, just over the border from Elkhart County at the age of 92 of a cerebral hemorrhage. She married Joseph B. Haney on October 7, 1860 in Elkhart County at the age of 17. He died in 1920.

According to her death certificate, she was buried in the Baintertown Cemetery, also known as the Rodibaugh Cemetery, where Margaret is buried as well.

Lucinda had 4 known children:
- Emma Rose Haney born in 1861.
- Allen Ottis Haney born Sept. 24, 1862 in Milford, Kosciusko County, Indiana and died May 8, 1953 in Florida.
- Harry Haney born in 1864.
- Cecil Marie Haney born Sept. 4, 1884 in VanBuren, Kosciusko County, Indiana, died February 9, 1977 in Rochester, Fulton County, Indiana and is buried in the Baintertown Cemetery. Cecil married Bert Eugene Dausman and had daughters:
Dorothy Loretta Dausman (1902-1987) who married Edward Poppenger or Pippinger and had one daughter
Helen Nadine Dausman (1905-1994) who married Joseph Osborn Perkins and had one daughter
Trella B. Dausman (1909-1983) who married Laddie Straka
2. Samuel Whitehead, Margaret’s oldest son, was born June 7, 1844 in Elkhart County, Indiana and died on April 26, 1923 in Goshen, Elkhart County of chronic bronchitis.

Sam was a carriagemaker with a shop in New Paris, Indiana. Eventually, he took a partner and operated under the name of Whitehead and Landgraver. He also owned a sawmill on the south end of New Paris.
Samuel is buried in the Baintertown Cemetery. He married Henrietta Dietz on November 18, 1865 in Elkhart, Indiana.

Samuel and Henrietta had:
- Lizzie Whitehead (1867-1937)
- Charlie Whitehead (1869-1939)
Samuel later remarried to Martha J. Vail on March 26, 1874 and they had the following children:
- Earl R. Whitehead (1875-1945)
- Mabel J. Whitehead (1883-1953)
- Ina Whitehead (1886-1971)
- Hazel Whitehead (1888-1958)
- Ross Whitehead (1889-1958)
- Boyd A. Whitehead (1894-1968)
- Carlisle Whitehead (1897-1967)
3. Jacob Franklin Whitehead, Margaret’s second son, was born October 10, 1846 in Elkhart County and died on April 1, 1932, in Adrian, Bates County, Missouri where his uncle, Adam Lentz had settled. He is buried in the Crescent Hill, Cemetery He married Eva Bowser (1847-1933) on May 21, 1865 in Elkhart County.

They had:
- John Bertus Whitehead (1879-1961)
- Charles Whitehead born 1872
- Maggie Whitehead born 1875
- Claudie Whitehead born 1883
4. Emmanual Whitehead, Margaret’s third son, was born January 15, 1849 in Elkhart County, died on April 10, 1924 in Kosciusko County, Indiana and is buried in the Salem Cemetery.

Emmanuel married Elizabeth Ullery, a school teacher on November 26, 1871 in Elkhart County, Indiana, and according to the Whitehead book:
Elizabeth’s brother, Levi, recorded in his diary, “Lizzie Ulery’ wedding day. She was married to Emanuel Whiehead by John H. Miller at 2 p.m., and a large crowd attended the wedding.
Of course, Margaret would have been at that wedding. It might even have been held at her house.
Emanuel worked for his brother, Sam, in the sawmill, couldn’t read or write, but could do mathematical calculations in his head. It was reported that he could look at a tree and calculate the number of board feet of lumber that could be cut from the trunk.
When not working or farming, he loved to fish as did many of his Ulery kinsmen.
They had two baby daughters that dies shortly after birth, and then:
- Argus Burtis Whitehead (1875-1962)
- Jessie Whitehead born (1877-1947)
- Clayton S. Whitehead born (1879-1949)
- Calvin E. Whitehead (1881-1971)

Emmanual Whitehead remarried on February 9, 1900 to Sarah Foster (1856-1940).
5. Mary Jane Whitehead, Margaret’s second daughter and last child by Valentine Whitehead, was born February 11, 1852. She died on Sept. 30, 1930 in Nappanee, Elkhart County, Indiana of angina pectoritis and was buried at the Union Center Brethren Church cemetery.

Mary Jane married John D. Ullery (1846-1928) on March 10, 1872 in Elkhart, Indiana.
They had:
- Edward W. Ulery (1872-1942)
- Margaret Elizabeth Ulery (1874-1959) and married Albert Mutschler on June 10, 1897 in Elkhart County, Indiana. They had one daughter:
Mary L. born July 1898
- David Leatherman, an adopted son, who died in 1903
It’s somehow ironic that my line of the family never heard the “shipwreck story” of Jacob and Fredericka Lentz, but buried in the John Ulery biography we find that same story, handed down for posterity – but somehow never making it to the current generation.
From the book, Pictorial and Biographical Memoirs of Elkhart and St. Joseph Counties, Indiana; Chicago, Goodspeed Brothers; 1893:
JOHN D. ULERY. During the forty-six years that have passed over the head of the gentleman whose name stands at the head of this sketch, he has witnessed a wonderful transformation in Elkhart county, and during all these years he has been an active observer of the trend of events. He has not been merely a “looker on in Venice,” but a citizen who has, through his enterprise, his integrity and his public ¬spirit, contributed his full share to the magnificent development of the section in which he resides. He comes of an honored ancestry, for the well-known old pioneer, Daniel Ulery, was his father, from whom he inherited many of his most worthy characteristics. He was the third of his children and first saw the light of day on the old home farm in Union township, February 3, 1846, and like the majority of farmer’s boys of that region, obtained his initiatory education in what was known far and near as the Ulery School. This he alternated with tilling the soil until he had almost attained man’s estate, when he quit school to devote his attention to agricultural pursuits, which calling occupied his time and attention until he was about twenty-seven years of age. He then, on March 10, 1872, united his fortunes with those of Mary J. Whitehead, who was the youngest child born to Valentine and Margaret (Lentz) Whitehead; the former was a son of Valentine and Elizabeth (Rodebaugh) Whitehead, who were of German descent and were early pioneers of Pennsylvania and Ohio. Valentine lost his wife, Elizabeth, in Ohio, after which he removed to the Hoosier State and died in Elkhart county in 1867, at which time he was a retired farmer and nearly ninety years of age. He was the father of eleven children, all of whom are dead, with the exception of three: Louis, Peter and David. Valentine, one of the children of the above mentioned family, was the father of Mrs. John Ulery. He removed to Indiana at an early day, having mar¬ried Margaret Lentz, in Ohio, and settled on a woodland farm of 160 acres in Jackson township, Elkhart county, which he did much to improve prior to his death, which occurred on July 24, 1851. He was a member of the German Baptist Church, a Democrat in early life and afterward became a Republican in political principle, although he but seldom exercised the privilege of suffrage. Five children were the result of his union: Lucinda, wife of Joseph B. Haney, was born December 13, 1842; Samuel, a carpenter of Goshen, was born in 1845; Jacob is a farmer of Bates county, Mo.; Emanuel, of Kosciusko county, Ind., is married to Elizabeth Ulery, by whom he has four children–Argus, Jesse, Clayton and Calvin; Mary J. is the wife of John D. Ulery. After the death of her husband, Mrs. Whitehead married John D. Miller, of New Paris, who was born near Dayton, Ohio, in 1812, a son of David Miller (a more complete sketch of this gentleman is found in the sketch of David B. Miller). He has resided for years in the vicinity of New Paris, where he is highly honored and esteemed. Mrs. Miller is now seventy-one years of age, but is still healthy and active. To her union with Mr. Miller three children were given: Evaline, Ira and Perry. Mr, and Mrs. Miller are residents of Jackson township, Elkhart county. Mrs. John D. Ulery was born in this county, February 11, 1852, and has presented her husband with two children : Edward W., born December 13, 1872, who has the principal charge of the home farm and is a steady, kindly and intelligent young man, and Lizzie, who was born November 28, 1874, and is an accomplished young lady. Mr. Ulery is classed among the foremost citizens of Union township, and is at the head of his business, owing to the energy and en¬terprise he has displayed. He owns an exceptionally fertile farm of 135 acres, on which are probably the best buildings of any farm in the township. He is a man of wealth and owns an interest in the Nappanee Furniture Company, as well as in other paying interests. He has followed in his father’s footsteps in regard to meeting with accidents, as well as in other respects, for on July 4, 1881, he was badly injured by a reaping machine and for about a year thereafter was an invalid. He is deservedly classed among the public-spirited and intelligent men of the county and is warm personal friends can be numbered by the score. Mrs. Ulery is a member of the German Baptist Church. Her maternal grandfather came to this country at an early day, having started from his native land a rich man. The voyage by water occupied nine months, and upon landing he found himself without means, owing to the tyranny and dishonesty of the captain of the vessel. On this voyage some three hundred souls died. Mr. and Mrs. Ulery took to rear as their own child, David A. Leatherman, who, at that time was six years of age, and the orphan son of John and Elizabeth Leatherman, gave him every advantage and provided means for him to graduate from the University at Valparaiso, Ind. He is a young man of much promise and at the present time is a traveling man. He remained with his foster parents until he was twenty years old and still holds them in grateful and honored remembrance, for they proved to him a friend in his need and were always as kind and thoughtful of his wants as though he were one of their own family. This is but one instance of the many kind and disinterested actions done by Mr. Ulery in his walk through life, and clearly indicated the true character of the man.
Margaret Lentz had 4 children with John David Miller, three of whom lived. We don’t know the name of the 4th child or when they were born, although I suspect 1861. John David’s obituary says that 4 children were born to Margaret and John David, 3 of whom survive, which is also confirmed by the 1900 census.
6. Evaline Louis Miller, Margaret’s first child with John David Miller was born March 29, 1857 in Elkhart County, Indiana and died on December 20, 1939 in Leesburg, Kosciusko County, Indiana of an inflammation of the heart (acute myocarditis) following a 3 month kidney infection (nephritis).

She is buried in the Salem Brethren Church cemetery.

Evaline married to Hiram B. Ferverda on March 10, 1876 in Goshen, Indiana.

The photo above is Eva Miller Ferverda with her husband Hiram and their entire family, including my grandfather John Ferverda, 2nd from right in the rear. Hiram died in 1925, and their youngest child was born in 1902, so I’d estimate that this photo was taken close to 1920, or perhaps slightly earlier, based on the WWI stars in the window and a son in uniform.
Evaline Louise Miller Ferverda had 11 children:
- Ira Otta Ferverda (1877-1950) who married Ada Pearl Frederickson.
- Edith Estella Ferverda (1879-1955) who married Tom Dye. They had the following daughter:
Ruth Dye
- Irvin Guy Ferverda (1881-1933) who married Jessie Hartman.
- John Whitney Ferverda (1882-1962) who married Edith Barbara Lore.
- Elizabeth Gertrude Ferverda (1884-1966) who married Louis Hartman and had the following daughters.
Louisa Hartman married Ora Tenney
Helen Tenney married Norman Nine
Lisa Nine
Roberta Hartman married Rulo Frush
Carol Frush married William Slaymaker
Nadine Slaymaker
Nancy Slaymaker
- Chloe Evaline Ferverda (1886-1984) and married Rolland Robinson and had one daughter:
Charlotte Robinson married Bruce Howard
Susan Howard married Richard Higg
Mary Carol Howard married David Bryan
Kerrie Bryan
Julie Bryan
Sally Howard
- Ray Edward Ferverda (1891-1975) who married Grace Driver.
- Roscoe H. Ferverda (1893-1978) who married Effie Ringo and Ruby Mae Teeter.
- George Miller Ferverda (1885-1970) who married Lois Glant.
- Donald D. Ferverda (1899-1937) who married Agnes Ruple.
- Margaret Ferverda (1902-1984) who married Chester Glant and had the following daughters:
Mary Glant married Varrill Wigner.
Kari Anne Wigner
Joyce Ann Glant married Delferd Zimmerman
Nancy Zimmerman
Beth Zimmerman
7. Ira J. Miller, Margaret’s 2nd child with John David Miller was born July 26, 1859 in Elkhart County and died on December 17, 1948 in Elkhart County of coronary breast disease.

Ira is buried in the Baintertown Cemetery.

Ira married Rebecca Rodibaugh on November 23, 1882 in Elkhart and they had the following child:

The above photo is Ira J. Miller with his wife, Rebecca. The photo below includes Ira Miller and his sister, Evaline Louise Miller Ferverda.

Last row, rear left to right, Rebecca Rodibaugh Miller, Ira Miller, one of Eva Miller Ferverda’s children,
Middle row, Eva Miller’s child, Eva Miller Ferverda
Front row, Mame Smoker Miller and Everett Miller (son of Ira.)
8. Perry Miller, Margaret’s final surviving child was born on June 25, 1862 in Elkhart County and died on December 22, 1906 in Goshen, Indiana of a bowel obstruction.

Perry buried in the Violett Cemetery in Goshen.

Perry married Mary Jane Lauer on October 2, 1881 in Elkhart, Indiana and they had the following children:
- Maud Miller born 1882-1902, buried with her parents
- Purl Miller born 1885-1960, a painter, buried in the Violett Cemetery
- Otto M. (Ottie) Miller born 1889-1976, a railroad engineer
DNA – Mitochondrial and Autosomal
You’d think with all of the people who descend from Margaret, someone who descends through all females would have taken a mitochondrial DNA test, but apparently not. If anyone has, please let me know.
If you haven’t and you descend from Margaret through all females to the current generation, where males can test too, I have a DNA testing scholarship for you!
The individuals bolded in the section above descend through Margaret Lentz Whitehead Miller through all females. These individuals or their descendants through all females from Margaret carry Margaret’s mitochondrial DNA and are eligible to test.
Testing for Margaret’s mitochondrial DNA will tell us about her deep ancestry and help us learn the path our ancestors took to and through Europe.
Margaret still has more secrets to reveal about herself.
Identifying Lentz DNA vs Miller DNA
One of the challenges we have in genetic genealogy is that when we autosomally test descendants of couples, like Margaret Lentz and John David Miller, we can’t tell which DNA comes from which parent.
However, because Margaret had children with a different husband, Valentine Whitehead, if some of the descendants of Margaret’s children with Valentine were to take an autosomal DNA test and they match the DNA of the descendants of Margaret through John David Miller – then we’ll know that the matching DNA comes from the Margaret’s Lentz line and not the Miller line.
Anyone descended from Jacob Lentz and Fredericka Reuhle Lentz through children other than Margaret who have DNA tested and match the descendants of Margaret and John David Miller – that DNA is also Lentz DNA as distinguished from Miller DNA.
Let’s do a little experiment to see if we can isolate snippets of Margaret Lentz’s DNA.
I have 4 people who have tested that are descendants of Margaret Lentz Miller, all through her children with John David Miller. I have two Lentz males who have tested that descend from different sons of Jacob Lentz and Fredericka Reuhle. People in the bottom row are all testers.

Benjamin, Margaret and George Lentz are siblings. The relationship of the people in the pink box to the descendants of Benjamin and George in the next generation are 1st cousins. Within the pink box, the relationship is different. Evaline and Ira are siblings, but Evaline and Ira are 1st cousins to both Whitney and Ira (son of George) as are Ira (son of George) and Whitney to each other.
Let’s see if any of the two Lentz males match the DNA of the 4 descendants of Margaret Lentz Miller. If so, those matching segments would have been inherited from Margaret Lentz by her children.
In order to do this easily, we’re going to run the chromosome browser at Family Tree DNA for each of the Lentz men, William and C., individually, against all 4 of the people who descend from Margaret Lentz.
Ironically, the two Lentz males, William and C. Lentz, don’t match each other above the vendor’s testing threshold, but do match each of the other 4 individuals.
William and C. Lentz do, however, match each other on 3 segments above 6cM at GedMatch where you can adjust the matching thresholds.
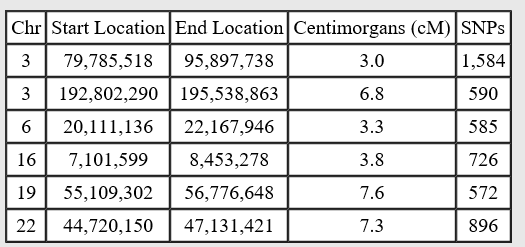
After selecting the four pink descendants of Margaret and comparing on the chromosome browser to each of the Lentz men, we’re going to download their matching segments to each of the Lentz men and drop those results into a common spreadsheet.
In this example, I’m using William Lentz as the background person we’re comparing against, and the 4 pink testers who descend from Margaret Lentz Miller are the 4 people being compared to William. On William’s chromosome displayed below:
- Rex=orange
- Barbara=blue
- Cheryl=green
- Don=bright pink

At the top of the chromosome browser you’ll see a selection on the left side next to the Chromosome Browser Tutorial that says “download to Excel (CSV format).” That selection will only download matching segments of the people you’re comparing, so I made that selection.

I repeated the process for C. Lentz as compared to these same 4 pink people, and combined the results into one spreadsheet where I color coded the results of the two Lentz men differently and deleted the segments below 3cM. C. Lentz is blue and William Lentz is apricot.

This chart took my breath away. We are literally looking at segments of Margaret Lentz’s DNA inherited by her descendants (assuming there no other family connection between these individuals.)
Let’s sort this in segment and chromosome order and see what we come up with.
Each of these rows is able to “stand alone” since we already know how these individuals are related. They are closely related, 3rd cousins, and we’re trying to see which of their DNA is from a common source – meaning the Lentz DNA from Jacob Lentz and Fredericka Reuhl.
However, even though these individual matches work, due to the close known relationships, triangulation groups are always preferable. But first, let’s look at matching groups.

In the chart above, I colored the 5 columns beginning with chromosome green when there is more than one match that includes any part of the same segment. Remember, we can’t see triangulation on this spreadsheet, because we only looking at matches to William and C. Lentz individually. These are just match groups at this point.
I added the column “Match Set” so that you can easily see the different matching groups. Because the green color used to indicate matching groups butts up against neighboring groups, it’s difficult to tell where one group ends and the next begins, so I’ve indicated that in the “Match Set” column by labeling each matching set of DNA.
The yellow match sets aren’t to siblings and may well triangulate. The match sets colored green in the Match Set column are to both Don and Cheryl, who are siblings, and you can’t count matches to siblings in triangulation groups.
- A match is when any two people match – like Barbara and William Lentz.
- A match set is when any two pairs match on the same segment.
- Triangulation occurs when any three people match on any portion of the same segment of DNA AND share a known common ancestor. Without the known ancestor or ancestral line, it’s just a match set.
Match set 1 doesn’t count as triangulation because William matches Don and Cheryl both who are siblings. Triangulation needs to occur between more distant matches.
Match set 2, which is yellow, could triangulate. To verify triangulation, we need to verify that Barbara matches Don on this part of the same segment.
I went back to Barbara’s chromosome browser and indeed, she does match Don on part of this same segment. This segment does triangulate, as shown below – because all three people match each other on a portion of this same segment.

The actual overlapping segment between all three individuals is from 121,679, 417 through 128,527,507 for probably about 6cM.
Of course, now if I could just find a Lenz descendant from upstream of Jacob, or a Reuhl upstream of Fredericka that matches some of these folks, I could determine if Margaret’s DNA is Lenz (Lentz) or Reuhl.
If you’re thinking this could go on forever, you’re right – except that the further out in time, the less likely to find a match, let alone on a common segment. It’s a genetic genealogical end of line instead of a more traditional one. What a fun challenge though. And hey, there’s always hope that someone from Germany or another line that immigrated will test and match. That’s the beauty of DNA. You can learn from autosomal matches, Y DNA matches and mitochondrial as well, so you have three genetic educational opportunities for each ancestor.
Summary
Margaret’s early life is shrouded in a bit of mystery, other than we know she was born in Pennsylvania and was raised Brethren. Her first entrance on her own is when she married on her 18th birthday. Celebration or rebellion, or both? We’ll never know, but marrying ON her 18th birthday does cause the question to be asked.
Margaret’s life seemed to be typical in every way, which for women of that timeframe means we find them in census records and not much else. However, that would change in July of 1851 when her husband, Valentine Whitehead, suddenly died.
Margaret was just two months pregnant at that time with her 5th child, a daughter that would never meet her father. Margaret probably farmed for the next 5 years as best she could, in addition to being a mother to her children. Yes, she had the resources of the Brethren community, but the fact that she did not hurriedly remarry suggests she might have been far more independent that most women of her time. She also didn’t sell out and go back home, to Ohio, to her parents. That must have been a temptation for a young widow under 30 with 5 children. Was she simply that iron-willed, resilient and determined?
Five years later, Margaret remarried to John David Miller. They combined their 12 children into a blended family and added 3 more of their own, for a total of 15 altogether. If the photo of John David and Margaret indeed is in front of the cabin portion of their home, they did not add on during their lifetime and lived in just the cabin portion – a small house for such a large family.
John David’s obituary tells us that Margaret had 4 children after their marriage, but only 3 survived. There was a span of 3 years between Ira and Perry, so the child who died was likely born in 1861. There are no candidate children buried either at Baintertown or in the Whitehead Cemetery, but many graves don’t have markers. It appears that Mary Baker Miller didn’t have a marker until John David Miller died, more than 50 years later.
However, looking at the births of Margaret’s children, she may have had one more. Her first child wasn’t born for 2 years after she was married – something almost unheard of at that time. She could well have had a first child that died and Lucinda, born two weeks shy of Margaret’s 20th birthday could have been her second child. The 1900 census doesn’t reflect that in the number of birthed vs living children, but the census has been known to be incorrect.
Margaret may have buried her first child in the Happy Corners cemetery where her parents would later rest. If so, that grave too is unmarked.
Margaret bore her last child when she was just 6 months shy of her 40th birthday.
By the sunset years of Margaret’s life, her 8 children who survived childhood gave her 38 known grandchildren, at least one and likely seven whose funerals she attended. Multiple grandchildren are noted once in the census, and then no more. There were likely additional grandchildren born who didn’t live long enough for a census to be taken. Unfortunately, losing multiple children was a way of life and expected before the era of modern medicine, in particular, antibiotics.
Margaret and John David Miller both lived to be quite elderly. He apparently became senile before he died, just shy of his 90th birthday and Margaret died not long afterwards of progressive heart disease.
Unfortunately, the blended family that seemed to work so well, from outward appearances anyway, came unraveled before John’s death. His children from his first marriage petitioned the court for guardianship, which appears to have driven a significant wedge between the two sets of children. That rift never healed, and in fact, became worse after John David’s death, pushing Margaret to the point where she withdrew her dower rights from John’s estate, deeding that third to her Miller children. John’s children from his first marriage would have been far better to let the will stand uncontested, but they didn’t.
It’s through this contested will that we discover that while Margaret’s children can read and write, she cannot – or at least she can’t at 80 years of age. We don’t know if she could have signed her name when she was younger.
Margaret was no pushover – and if those 7 Miller children thought they could push their elderly step-mother around, they were wrong. I bet both John David’s and Margaret’s funerals were “interesting,” to say the least, given the division within the family. John David’s funeral was at the house, not the church, so I’d wager that Margaret’s funeral took place at home too. I have to wonder what she might have thought, watching from above. Was she chuckling to herself, or was she angry?
Even at her advanced age and in ill health, it appears that Margaret was still something of a spit-fire. She didn’t let her Brethren religion keep her from going to the courthouse and taking care of business several times in her last year.
Margaret died of hydro pericardium, an accumulation of fluid in the membrane that surrounds the heart. She also had mitral incompetency which means the mitral valve of the heart does not close properly, eventually causing congestive heart failure.

This ailment would not have manifested itself suddenly. It’s likely that as she cared for her aging husband, she was short of breath herself. As the stressful situation following his death unfolded, her health was worsening as well.
Margaret passed away on the 4th of July. Independence Day indeed! Margaret’s death leaves me wondering once again if this was her way of making a triumphant exit statement, much as her marriage on her 18th birthday was her grand entrance.
I suspect that Margaret was part rebel, in spite of her Brethren upbringing. In any case, she appeared to be a lot more independent than was acceptable for Brethren girls or women – and it showed from time to time!
Perhaps I came by that trait honestly and it’s carried from generation to generation in some of those DNA segments!
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
Genealogy Services
Genealogy Research










































































































































































































{kind=link}