
The MyHeritage LIVE Oslo conference is but a fond memory now, and I would count it as a resounding success.
Perhaps one of the reasons I enjoyed it so much is the scientific aspect and because the content is very focused on a topic I enjoy without being the size and complexity of Rootstech. The smaller, more intimate venue also provides access to the “right” people as well as the ability to meet other attendees and not be overwhelmed by the sheer size.
Here are some stats:
- 401 registered guests
- 28 countries represented including distant places like Australia and South America
- More than 20 speakers plus the hands-on workshops where specialist teams worked with students
- 38 sessions and workshops, plus the party
- 60,000 livestream participants, in spite of the time differences around the world
I was blown away by the number of livestream attendees.
I don’t know what criteria Gilad Japhet will be using to determine “success” but I can’t imagine this conference being judged as anything but.
Let’s take a look at the second day. I spent part of the time talking to people and drifting in and out of the rear of several sessions for a few minutes. I meant to visit some of the workshops, but there was just too much good, distracting content elsewhere.
I began Sunday in Mike Mansfield’s presentation about SuperSearch. Yes, I really did attend a few sessions not about DNA, but my favorite was the session on Improved DNA Matching.
Improved DNA Matching
I’m sure it won’t surprise any of my readers that my favorite presentations were about the actual science of genetic genealogy.
Consumers don’t really need to understand the science behind autosomal results to reap the benefits, but the underlying science is part of what I love – and it’s important for me to understand the underpinnings to be able to unravel the fine points of what the resulting matches are and are not revealing. Misinterpretation of DNA results leading to faulty conclusions is a real issue in genetic genealogy today. Consequently, I feel that anyone working with other people’s results and providing advice really needs to understand how the science and technology together works.

Dr. Daphna Weissglas-Volkov, a population geneticist by training, although she clearly functions far beyond that scope today, gave a very interesting presentation about how MyHeritage handles (their greatly improved) DNA Matching. I’m hitting the high points here, but I would strongly encourage you to watch the video of this session when they are made available online.
In addition to Dr. Weissglas-Volkov’s slides, I’ve added some additional explanations and examples in various places. You can easily tell that the slides are hers and the graphics that aren’t MyHeritage slides are mine.

Dr. Weissglas-Volkov began the session by introducing the MyHeritage science team and then explaining terminology to set the stage.

A match is when two people match each other on a fairly long piece of DNA. Of course, “fairly long” is defined differently by each vendor.

Your genetic map (of your chromosomes) is comprised of the DNA you inherit from different ancestors by the process of recombination when DNA is transferred from the parents to the child. A centiMorgan is the relatively likelihood that a recombination will occur in a single generation. On average, 36 recombinations occur in each generation, meaning that the DNA is divided on any chromosome. However, women, for reasons unknown have about 1.5 times as many recombinations as men.
You can’t see that when looking at an example of a person compared to their parents, of course, because each individual is a full match to each parent, but you can see this visually when comparing a grandchild to their maternal grandmother and their paternal grandmother on a chromosome browser.

The above illustration is the same female grandchild compared to her maternal grandmother, at left, and her paternal grandmother at right. Therefore the number of crossovers at left is through a female child (her mother), and the number at right is through a male child (her father.)
| # of Crossovers | |
| Through female child – left | 57 |
| Through male child – right | 22 |
There are more segments at left, through the mother, and the segments are generally shorter, because they have been divided into more pieces.
At right, fewer and larger segments through the father.

Keep in mind that because you have a strand of DNA from each parent, with exactly the same “street addresses,” that what is produced by DNA sequencing are two columns of data – but your Mom’s and Dad’s DNA is intermixed.
The information in the two columns can’t be identified as Mom’s or Dad’s DNA or strand at this point.
That interspersed raw data is called a genotype. A haplotype is when Mom’s and Dad’s DNA can be reassembled into “sides” so you can attribute the two letters at each address to either Mom or Dad.
Here’s a quick example.

The goal, of course, is to figure out how to reassemble your DNA into Mom’s side and Dad’s side so that we know that someone matching you is actually matching on all As (Mom) or all Gs (Dad,) in this example, and not a false match that zigzags back and forth between Mom and Dad.

The best way to accomplish that goal of course is trio phasing, when the child and both parents are available, so by comparing the child’s DNA with the parents you can assign the two strands of the child’s DNA.

Unfortunately, few people have both or even one parent available in order to actual divide their DNA into “sides,” so the next best avenue is statistical phasing. I’ve called this academic phasing in the past, as compared to parental phasing which MyHeritage refers to as trio phasing.
There’s a huge amount of confusion about phasing, with few people understanding there are two distinct types.
Statistical phasing is a type of machine learning where a large number of reference populations are studied. Since we know that DNA travels together in blocks when inherited, statistical phasing learns which DNA travels with which buddy DNA – and creates probabilities. Your DNA is then compared to these models and your DNA is reshuffled in order to assemble your DNA into two groups – one representing your Mom’s DNA and one representing your Dad’s DNA, according to statistical probability.

Looking at your genotype, if we know that As group together at those 6 addresses in my example 95% of the time, then we know that the most likely scenario to create a haplotype is that all of the As came from one parent and all of the Gs from the other parent – although without additional information, there is no way to yet assign the maternal and paternal identifier. At this point, we only know parent 1 and parent 2.

In order to train the computers (machine learning) to properly statistically phase testers’ results, MyHeritage uses known relationships of people to teach the machines. In other words, their reference panels of proven haplotypes grows all of the time as parent/child trios test.

Dr. Weissglas-Volkev then moved on to imputation.

When sequencing DNA, not every location reads accurately, so the missing values can be imputed, or “put back” using imputation.


Initially imputation was a hot mess. Not just for MyHeritage, but for all vendors, imputation having been forced upon them (and therefore us) by Illumina’s change to the GSA chip.
However, machine learning means that imputation models improve constantly, and matching using imputation is greatly improved at MyHeritage today.

Imputation can do more than just fill in blanks left by sequencing read errors.
The benefit of imputation to the genetic genealogy community is that vendors using disparate chips has forced vendors that want to allow uploads to utilize imputation to create a global template that incorporates all of the locations from each vendor, then impute the values they don’t actually test for themselves to complete the full template for each person.
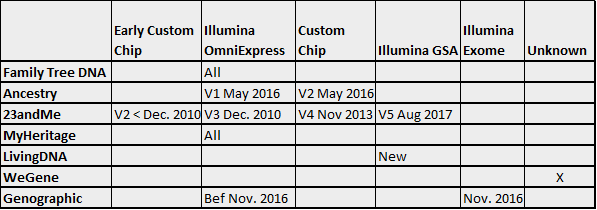
In the example below, you can see that no vendor tests all available locations, but when imputation extends the sequences of all testers to the full 1-500 locations, the results can easily be compared to every other tester because every tester now has values in locations 1-500, regardless of which vendor/chip was utilized in their actual testing.

Therefore, using imputation, MyHeritage is able to match between quite disparate chips, such as the traditional Illumina chips (OmniExpress), the custom Ancestry chip and the new GSA chip utilized by 23andMe and LivingDNA.

So, how are matches determined?
Matching
First your DNA and that of another person are scanned for nearly identical seed sequences.

A minimum segment length of 6cM must be identified for further match processing to occur. Anything below 6cM is discarded at this point.

The match is then further evaluated to see if the seed match is of a high enough quality that it should be perfected and should count as a match. Other segments continue to be evaluated as well. If the total matching segment(s) is 8 total cM or greater, it’s considered a valid match. MyHeritage has taken the position that they would rather give you a few accidental false matches than to miss good matches. I appreciate that position.

Window cleaning is how they refer to the process of removing pileup regions known to occur in the human genome. This is NOT the same as Ancestry’s routine that removes areas they determine to be “too matchy” for you individually.
The difference is that in humans, for example, there is a segment of chromosome 6 where, for some reason, almost all humans match. Matching across that segment is not informative for genetic genealogy, so that region along with several others similar in nature are removed. At Ancestry, those genome-wide pileup segments are removed, along with other regions where Ancestry decides that you personally have too many matches. The problem is that for me, these “too matchy” segments are many of my Acadian matches. Acadians are endogamous, so lots of them match each other because as a small intermarried population, they share a great deal of the same DNA. However, to me, because I have one great-grandfather that’s Acadian, that “too matchy” information IS valuable although I understand that it wouldn’t be for someone that is 100% Acadian or Jewish.
In situations such as Ashkenazi Jewish matching, which is highly endogamous, MyHeritage uses a higher matching threshold. Otherwise every Ashkenazi person would match every other Ashkenazi person because they all descend from a small founder population, and for genealogy, that’s not useful.

The last step in processing matches is to establish the confidence level that the match is accurately predicted at the correct level – meaning the relationship range based on the amount of matching DNA and other criteria.

For example, does this match cluster with other proven matches of the same known relationship level?

From several confidence ascertainment steps, a confidence score is assigned to the predicted relationship.

Of course, you as a customer see none of this background processing, just the fact that you do match, the size of the match and the confidence score. That’s what genealogists need!
Matching Versus Triangulation Thresholds
Confusion exists about matching thresholds versus triangulation thresholds.
While any single segment must be over 6 cM in length for the matching process to begin, the actual match threshold at MyHeritage is a total of 8 cM.
I took a look at my lowest match at MyHeritage.

I have two segments, one 6.1 cM segment, and one 6 cM segment that match. It would appear that if I only had one 6 cM segment, it would not show as a match because I didn’t have the minimum 8 cM total.
Triangulation Threshold
However, after you pass that matching criteria and move on to triangulation with a matching individual, you have the option of selecting the triangulation threshold, which is not the same thing as the match threshold. The match threshold does not change, but you can change the triangulation threshold from 2 cM to 8 cM and selections in-between.
In the example below, I’m comparing myself against two known relatives.

You won’t be shown any matches below the 6 cM individual segment threshold, BUT you can view triangulated segments of different sizes. This is because matching segments often don’t line up exactly and the triangulated overlap between several individuals may be very small, but may still be useful information.
Flying your mouse over the location in the bubble, which is the triangulated segment, tells you the size of the triangulated portion. If you selected the 2 cM triangulation, you would see smaller triangulated portions of matches.
Closing Session
The conference was closed by Aaron Godfrey, a super-nice MyHeritage employee from the UK. The closing session is worth watching on the recorded livestream when it becomes available, in part because there are feel good moments.
However, the piece of information I was looking for was whether there will be a MyHeritage LIVE conference in 2019, and if so, where.
I asked Gilad afterwards and he said that they will be evaluating the feedback from attendees and others when making that decision.
So, if you attended or joined the livestream sessions and found value, please let MyHeritage know so that they can factor your feedback onto their decision. If there are topics you’d like to see as sessions, I’m sure they’d love to hear about that too. Me, I’m always voting for more DNA😊
I hope to hear about MyHeritage LIVE 2019, and I’m voting for any of the following locations:
- Australia
- New Zealand
- Israel
- Germany
- Switzerland
What do you think?
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research




















































 ay that the
ay that the 























{kind=link}
{kind=link}
{kind=link}
{kind=link}