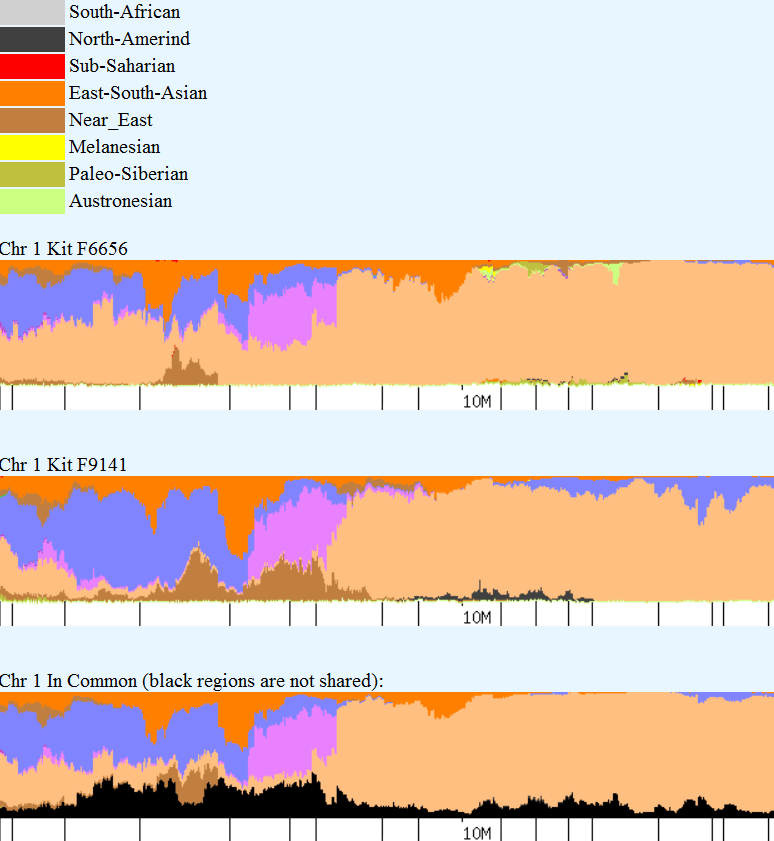
Sangreal – the Holy Grail. We are finally here, Part 9 and the final article in our series. The entire purpose of The Autosomal Me series has been to use our DNA and the clues it holds to identify minority admixture, in this case, Native American, and by identifying those Native segments, and building chromosomal clusters, to identify the family lines that contributed that Native admixture. Articles 1-8 in the series set the stage, explained the process and walked us through the preparatory steps. In this last article, we apply all of the ingredients, fasten the lid, shake and see what we come up with. Let’s take a minute and look at the steps that got us to this point.
Part 1 was “The Autosomal Me – Unraveling Minority Admixture” and Part 2 was “The Autosomal Me – The Ancestors Speak.” Part 1 discussed the technique we are going to use to unravel minority ancestry, and why it works. Part two gave an example of the power of fragmented chromosomal mapping and the beauty of the results.
Part 3, “The Autosomal Me – Who Am I?,” reviewed using our pedigree charts to gauge expected results and how autosomal results are put into population buckets.
Part 4, “The Autosomal Me – Testing Company Results,” shows what to expect from all of the major testing companies, past and present, along with Dr. Doug McDonald’s analysis.
In Part 5, “The Autosomal Me – Rooting Around in the Weeds Using Third Party Tools,” we looked at 5 different third party tools and what they can tell us about our minority admixture that is not reported by the major testing companies because the segments are too small and fragmented.
In Part 6, “The Autosomal Me – DNA Analysis – Splitting Up” we began the analysis part of the data we’ve been gathering. We looked at how to determine whether minority admixture on specific chromosomes came from which parent.
Part 7, “The Autosomal Me – Start, Stop, Go – Identifying Native Chromosomal Segments” took a deeper dive and focused on the two chromosomes with proven Native heritage and began by comparing those chromosome segments using the 4 GedMatch admixture tools.
Part 8, “The Autosomal Me – Extracting Data Segments and Clustering,” we extract all of the Native and Blended Asian segments in all 22 chromosomes, but only used chromosomes 1 and 2 for illustration purposes. We then clustered the resulting data to look for trends, grouping clusters by either the Strong Native criteria or the Blended Asian criteria.
In this final segment, Part 9, we will be applying the chromosomal information we’ve gathered to our matches and determine which of our lines are the most likely to have Native Ancestry. This, of course, has been the goal all along. So, drum roll…..here we go.
In Part 8, we ended by entering the start and stop locations of both Strong Native and Blended Asian clusters into a table to facilitate easy data entry into the chromosome match spreadsheet downloaded from either 23andMe or Family Tree DNA. If you downloaded it previously, you might want to download it again if you haven’t modified it, or download new matches since you last downloaded the spreadsheet and add them to the master copy.
My goal is to determine which matches and clusters indicate Native ancestry, and how to correlate those matches to lineage. In other words, which family lines in my family were Native or carry Native heritage someplace.
The good news is that my mother’s line has proven Native heritage, so we can use her line as proof of concept. My father’s family has so many unidentified wives, marginalized families and family secrets that the Native line could be almost any of them, or all of them! Let’s see how that tree shakes out.
Finding Matches
So let’s look at a quick example of how this would work. Let’s say I have a match, John, on chromosome 4 in an area where my mother has no Native admixture, but I do. Therefore, since John does not match my mother, then the match came from my father and if we can identify other people who also match both John and I in that same region on that chromosome, they too have Native ancestry. Let’s say that we all also share a common ancestor. It stands to reason at that point, that the common ancestor between us indicates the Native line, because we all match on the Native segment and have the same ancestor. Obviously, this would help immensely in identifying Native families and at least giving pointers in which direction to look. This is a “best case’ example. Some situations, especially where both parents contribute Native heritage to the same chromosome, won’t be this straightforward.
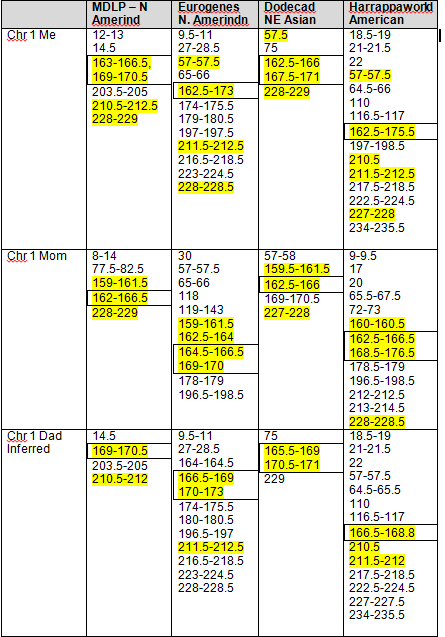
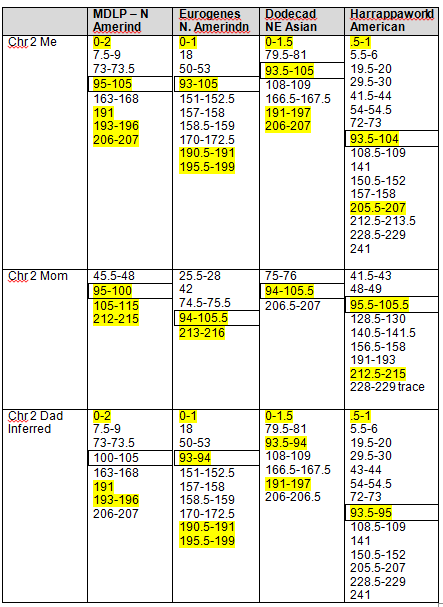
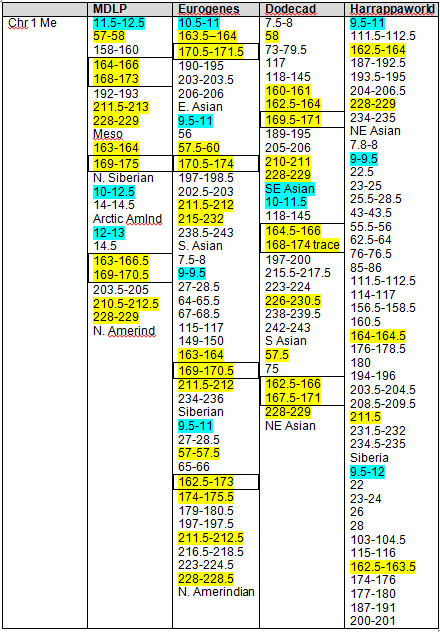
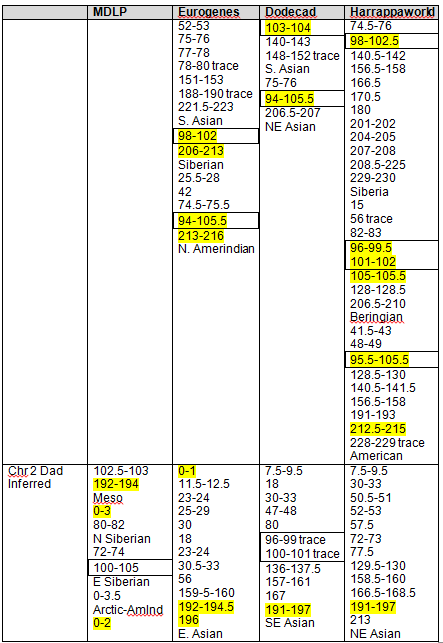
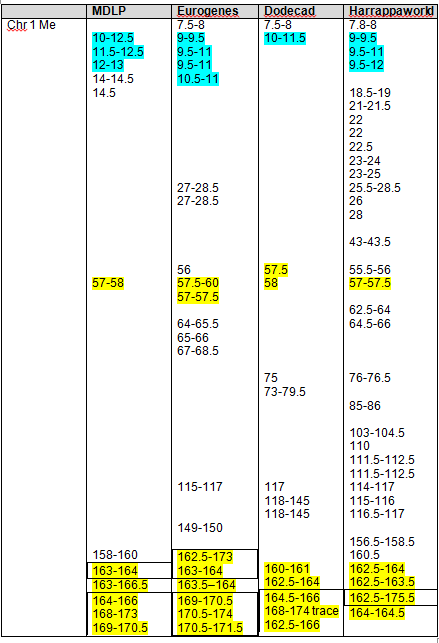
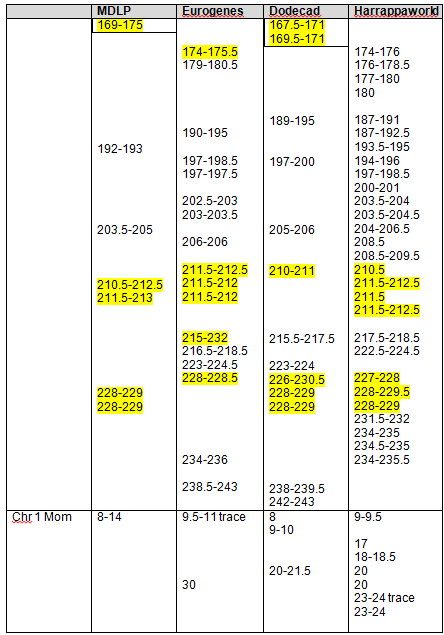
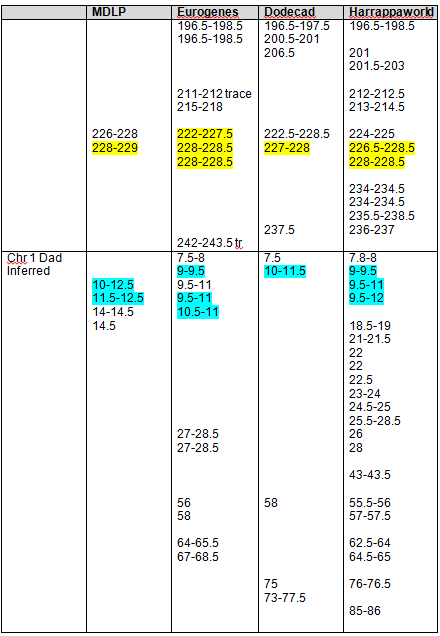
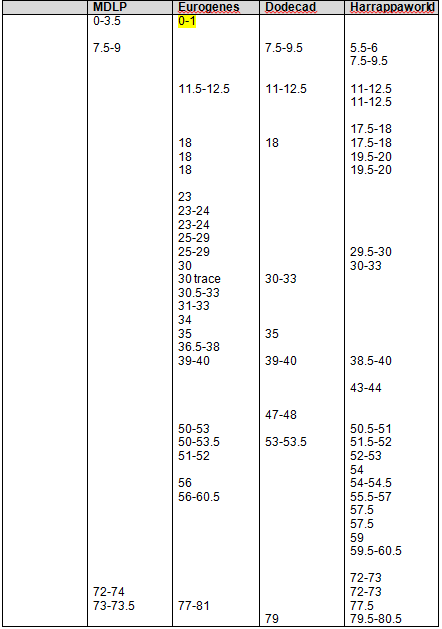
Based on our findings, the maximum range and minimum (least common denominator or “In Common” range is as follows for the strongest Native segments on chromosomes 1 and 2.
| Chromosome 1 | Chromosome 2 | |
| Largest Range | 162,500,000 – 180,000,000 | 79,000,000 – 105,000,000 |
| Smallest Range | 165,658,091 – 171,000,000 | 90,000,000 – 103,145,425 |
At GedMatch
At GedMatch, I used a comparison tool to see who matched me on chromosome 1. Only 2 people outside of immediate family members matched, and both from Family Tree DNA. Both matched me on the critical Native segments between about 165-180mg. I was excited. I went to Family Tree DNA and checked to see if these two people also matched my mother, which would confirm the Native connection, but neither did, indicating of course that these two people matched me on my father’s side. That too is valuable information, but it didn’t help identify any common Native heritage with my mother on chromosome 1. It did, however, eliminate them as possibilities which is valuable information as well.
DNAGedcom
I used a new tool, DNAGedcom, compliments of Rob Warthen who has created a website, DNA Tools, at www.dnagedcom.com. This wonderful tool allows you to download all of your autosomal matches at Family Tree DNA and 23andMe along with their chromosomal segment matches. Since my mother’s DNA has only been tested at Family Tree DNA, I’m limiting the download to those results for now, because what I need is to find the people who match both she and I on the critical segments of chromosome 1 or 2.
Working with the Download Spreadsheet
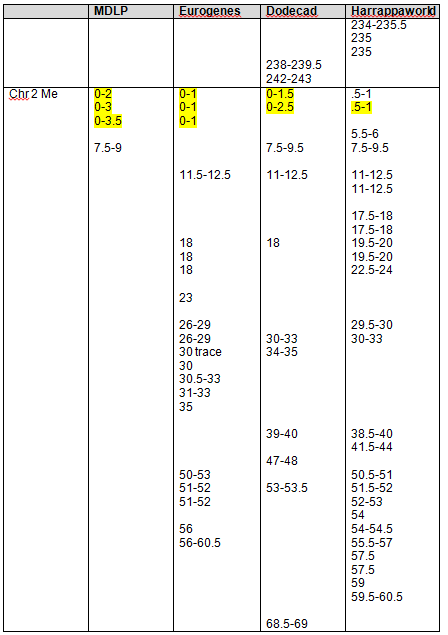
It was disappointing to discover that my mother and I had no common matches that fell into this range on chromosome 1, but chromosome 2 was another matter. Please note that I have redacted match surnames for privacy.

The spreadsheet above shows the comparison of my matches (pink) and Mother’s (white). The Native segment of chromosome 2 where I match Mother is shaded mustard. I shaded the chromosome segments that fell into the “common match” range in green. Of those matches, there is only one person who matches both Mother and I, Emma. The next step, of course, is to contact Emma and see if we can discover our common ancestor, because whoever it is, that is the Native line. As you might imagine, I am chomping at the bit.
There are no segments of chromosome 2 that are unquestionably isolated to my father’s line.
Kicking it up a Notch
Are you wondering about now how something that started out looking so simple got so complex? Well, I am too, you’re not alone. But we’ve come this far, so let’s go that final leg in this journey. My mom always used to say there was no point in doing something at all if you weren’t going to do it right. Sigh….OK Mom.
The easiest way to facilitate a chromosome by chromosome comparison with all of your matches and your Strong Native and Blended Asian segments is to enter all of these segment groups into the match spreadsheet. If you’re groaning and your eyes glaze over right after you do one big ole eye roll, I understand.
But let’s take a look at how this helps us.
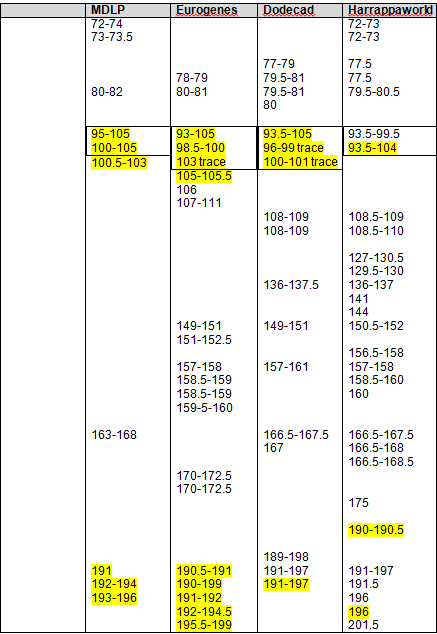
On the excerpt from my spreadsheet below, for a segment of chromosome 5, I have labeled the people and how they match to me. The ones labeled “Mom” in the last column are labeled that way because these people match both Mom and I. The ones labeled “Dad” are labeled that way because I know that person is related on my father’s side.
Using the information from the tables created in Step 8, I entered the beginning and end of all matching segment clusters into my spreadsheet. You can see these entries on lines 7, 8, 22, 23 and 24. You then proceed to colorize your matches based on the entry for either Mom or Dad – in other words the blue row or the purple row, line 7, 22 or 24. In this example, actually, line 5 Rex, based on the coloration, should have been half blue and half purple, but we’ll discuss his case in a minute.
The you can then sort either by match name or by chromosome to view data in both ways. Let’s look at an example of how this works.
Legend:
- White Rows: Mother’s matches. When Mother and I both match an individual, you’ll see the same matches for me in pink. This double match indicates that the match is to Mother’s side and not Father’s side.
- Pink Rows: My matches.
- Purple “Mom” labels in last column: The individual matches both me and Mom. This is a genetic match.
- Teal “Dad” labels in last column: Genealogically proven to be from my father’s side. This is a genealogical, not a genetic label, since I don’t have Dad’s DNA and can only infer these genetically when they don’t also match Mother.
- Dark Pink Rows labeled “Me Amerind Only” are Strong Native or Blended Asian segments from Chromosome Table that I have entered. My segments must come from one of my parents, so I’ve either colored them purple, if the match is someone who matches Mother and I both, or teal, if they don’t match both Mom and I, so by inference they come from my father’s line.
- Dark Purple Rows labeled “Mom Amerind Only” are Mom’s segments from the Chromosome Table.
- Dark Teal Rows labeled “Dad Amerind Only” are inferred segments belonging to my father based on the fact that Mother and I don’t share them.
Inferred Relationships
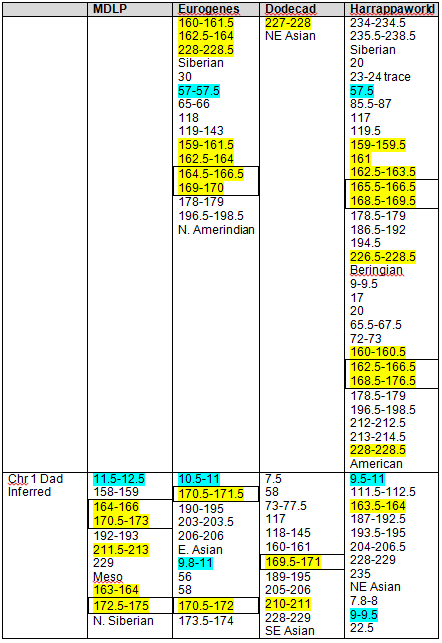
This is a good place to talk for just a minute about inferred relationships in this context. Inference gets somewhat tenuous or weak. The inferred matches on my father’s side began with the Native segments in the admix tools. Some inferences are very strong, where Mother has no Native at all in that region. For example, Mom has European and I have Native American. No question, this had to come from my father. But other cases are much less straightforward.
In many cases, categorization may be the issue. Mom has West Asian for example and I have Siberian or Beringian. Is this a categorization issue or is this a real genetic difference, meaning that my Siberian/Beringian is actually Native and came from my father’s side?
Other cases of confusion arise from segment misreads, etc. I’ve actually intentionally included a situation like this below, so we can discuss it. Like all things, some amount of common sense has to enter the picture, and known relationships will also weigh heavily in the equation. How known family members match on other chromosome segments is important too. Do you see a pattern or is this match a one-time occurrence? Patterns are important.
Keep in mind that these entries only reflect STRONG Asian or Native signals, not all signals. So even if Mother doesn’t have a strong signal, it doesn’t mean that she doesn’t have ANY signal in that region. In some cases, start and stop segments for Mom and Dad overlapped due to very long segments on some matches. In this case, we have to rely on the fact that we do have Mother’s actual DNA and assume that if they aren’t also a match to Mother, that what we are seeing is actually Dad’s lines, although this may not in actuality always be true. Why? Because we are dealing with segments below the matching threshold limit at both Family Tree DNA and 23andMe, and both of my parents carry Native heritage. We can also have crossed a transitional boundary where the DNA that is being matched switches from Mom’s side to Dad’s side.
Ugh, you say, now that’s getting messy. Yes, it is, and it has complicated this process immensely.
The Nitty-Gritty Data Itself

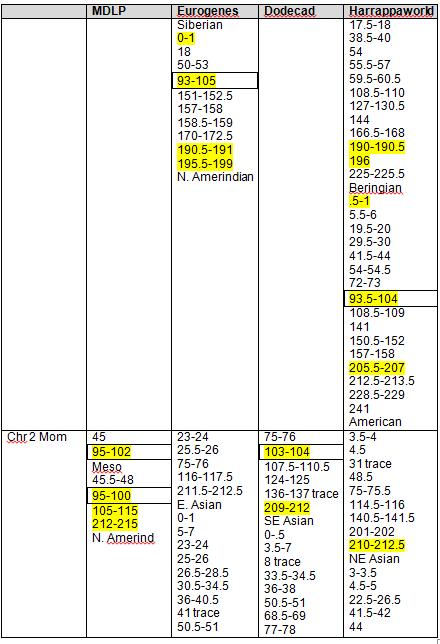
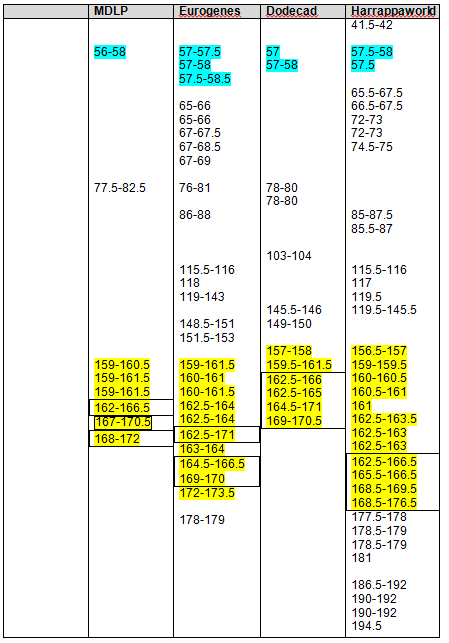
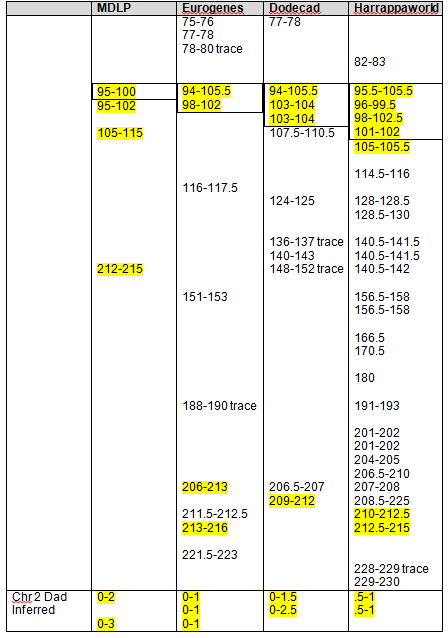
Taking a look at this portion of chromosome 5, we have lots going on in this cluster. Most segments will just be boring pink and white (meaning no Native), but this segment is very busy. Mom and I match on a small segment from 52,000,000 to 53,000,000. Indeed, this is a very short segment when compared to the entire chromosome, but it is strongly Native. We both also match Rex, our known cousin. I’ve noted him with yellow in the table. Please note that Mom’s white matches are never shaded. I am focused on determining where my own segments originate, so coloring Mother’s too was only confusing. Yes, I did try it.
You can see that Mother actually shares all or any part of her segment with only me and Rex. This simplifies matters, actually. However, also note that I carry a larger segment in this region than does Mother, so either we have a categorization issue, a misread, or my father also contributed. So, a conundrum. This very probably implies that my father also carried Native DNA in this region.
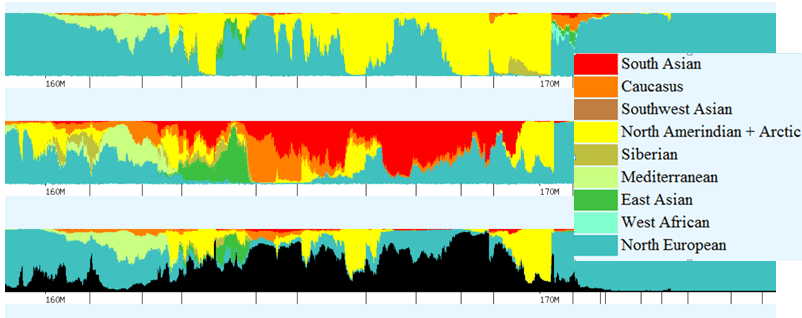
Let’s see what Rex’s DNA looks like on this same segment of chromosome 5, from 52-53 using Eurogenes. In the graph below, my chromosome is the top bar, Rex’s the middle and the bottom bar shows common DNA with the black nonmatching. Yellow is Native American, red is South Asian, putty is Siberian, lime green is Mediterranean, teal is North Europe, orange is Caucus.

This same comparison is shown to Mother’s DNA (top row) below.

It’s interesting that while Mother doesn’t have a lot of yellow (Native), she does have it throughout the same segment where Rex’s occurs, from about 52 through 53.5.
Does this actually point to a Native ancestor in the common line between Rex, Mom and I, which is the Swiss/German Johann Michael Miller line which does include an unidentified wife stateside, or does this simply indicate a common ancient population long ago in Asia? It’s hard to say and is deserving of more research. I feel that it is most likely Native because of the actual yellow, Native segment. If this was an Asian/European artifact, it would be much less likely to carry the actual yellow segment.
Is Rex also genealogically related to my father? As I’ve worked through this process with all of my chromosomes and matches, I’ve really come to question if one of my father’s dead ends is also an ancestral line of my mother’s.
The key to making sense of these results is clusters.
Clusters vs Singleton Outliers
The work we’ve already done, especially in Step 8, clusters the actual DNA matching segments. We’ve now entered that information into the spreadsheet and colored the segments of those who match. What’s next?
The key is to look for people with clusters. Many matches will have one segment, of say, 10 that match, colored. Unless this is part of a large chromosome cluster, it’s probably simply an outlier. Part of a large chromosome cluster would be like the large Strong Native segments on chromosome 1 or 2, for example. How do we tell if this is a valid match or just an outlier?
Sort the spreadsheet by match name. Take a look at all of the segments.
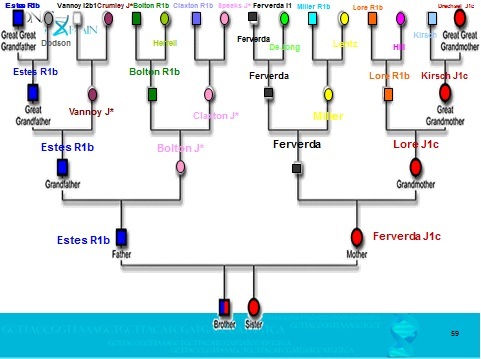
The example we’ll use is that of my cousin, Rex. If you recall, he matches both me and Mother, is a known first cousin twice removed to me, (genetically equal to a second cousin), and is descended from the Miller line.
In this example, I also colored Mother’s segments because I wanted to see which segments that I did not receive from her were also Native. You can see that there are many segments where we all match and several of those are Native. These also match to other Miller descendants as well, so are strongly indicative of a Native connection someplace in our common line.
If we were only to see one Native segment, we would simply disregard this as an outlier situation. But that’s not the case. We see a cluster of matches on various segments, we match other cousins from the same line on these segments, and reverting back to the original comparison admixture tools verifies these matches are Native for Rex, Mom and me.

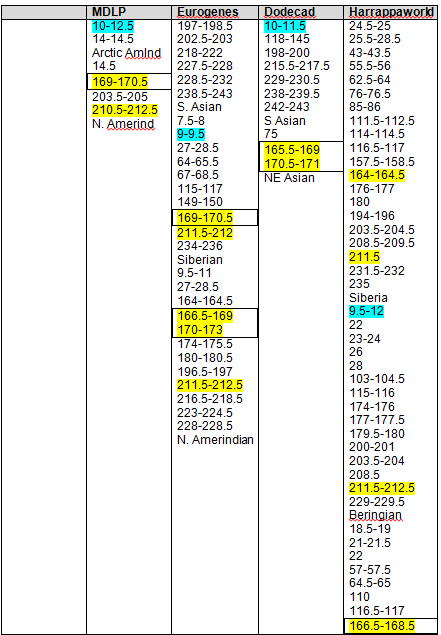
Hmmmm…..what is Dad’s blue segment color doing in there? Remember I said that we are only dealing with strong match segments? Well, Mom didn’t have a strong segment at that location and so we inferred that Dad did. But we know positively that this match does come from Mother’s side. I also mentioned that I’ve come to wonder if my Mom and Dad share a common line. It’s the Miller line that’s in question. One of Johann Michael Miller’s children, Lodowick, moved from Pennsylvania to Augusta County, Virginia in the 1700s and his line became Appalachian, winding up in many of the same counties as my father’s family. I’m going to treat this as simply an anomaly for now, but it actually could be, in this case, an small indication that these lines might be related. It also might be a weak “Mom” match, or irrelevant. I see other “double entries” like this in other Miller cousins as well.
What is the pink row on chromosome 12? When I grouped the Strong Native and Asian Clusters, sometimes I had a strong grouping, and Mom had some. The way I determined Dad’s inferred share was to subtract what Mom had in those segments from mine. In a few cases, Mom didn’t have enough segments to be considered a cluster but she had enough to prevent Dad from being considered a cluster either, so those are simply pink, me with no segment coloring for Mom or Dad.
Let’s say I carry Strong Native/Mixed Asian at the following 8 locations:
10, 12, 14, 16, 18, 20, 22, 24
This meets the criteria for 8 of 15 ethno-geographic locations (in the admix tools) within a 2.5 cM distance of each other, so this cluster would be included in the Mixed Asian for me. It could also be a Strong Native cluster if it was found in 3 of 4 individual tools. Regardless of how, it has been included.
Let’s now say that Mom carries Native/Mixed Asian at 10, 12 and 14, but not elsewhere in this cluster.
Mom’s 3 does not qualify her for the 8/15 and it only leaves Dad with 5 inferred segments, which disqualifies him too. So in this case, my cluster would be listed, but not attributable directly to either parent.
What this really says is that both of my parents carry some Native/Blended Asian on this segment and we have to use other tools to extrapolate anything further. The logic steps are the same as for Dad’s blue segment. We’re going to treat that as an outlier. If I really need to know, I can go back to the actual admixture tools and see whether Mom or Dad really match me strongly on which segments and how we compare to Rex as well. In this case, it’s obvious that this is a match to my Mother’s side, so I’m leaving well enough alone.
Let’s see what the matches reveal.
Matches
Referring back to the Nitty Gritty Data spreadsheet, Mom’s match to Phyllis on row 15 confirms an Acadian line. This is the known line of Mother’s Native ancestry. This makes sense and they match on Native segments on several other chromosomes as well. In fact, many of my and Mother’s matches have Acadian ancestry.
My match to row 19, Joy, is a known cousin on my father’s side with common Campbell ancestry. This line is short however, because our common ancestor, believed to be Charles Campbell died before 1825 in Hawkins County, TN. He was probably born before 1750, given that his sons were born about 1770 and 1772. Joy and I descend from those 2 sons. Charles wife and parents are unknown, as is his wife.
My match to row 20, inferred through my father’s side, is to a Sizemore, a line with genetically proven Native ancestry. Of course, this needs more research, but it may be a large hint. I also match with several other people who carry Sizemore ancestors. This line appears to have originated near the NC/VA border.
I wanted to mention rows 4 and 17. Using our rules for the spreadsheet, if I match someone and they don’t also match Mother on this segment, I have inferred them to be through my father. These are two instances that this is probably incorrect. I do match these people through Mother, but Mother didn’t carry a strong signal on this segment, so it automatically became inferred to Dad. Remember, I’m only recording the Strong Native or the Blended Asian segments, not all segments. However, I left the inferred teal so that you can see what kinds of judgment calls you’ll have to make. This also illustrates that while Mom’s genetic matches are solid, Dad’s inferred matches are less so and sometimes require interpretation. The proper thing to do in this instance would be to refer back to the original admixture tools themselves for clarification.
Let’s see what that shows.

Using HarrappaWorld, the most pronounced segment is at about 52. Teal is American. You can see that Mother has only a very small trace between 53 and 54, almost negligible. Mother’s admixture at location 52 is two segments of purple, brown and cinnamon which translate to Southwest Asian (lt purple), Mediterranean (dk purple), Caucasian (brown) and Balock (cinnamon), from Pakistan.
Checking Dodecad shows pretty much the same thing, except Mother’s background there is South Asian, which could be the same thing as Caucus and Pakistan, just different categorizations.
In this case, it looks like the admixture is not a categorization issue, but likely did come from my father. Each segment will really be a case by case call, with only the strongest segments across all tools being the most reliable.
It’s times like this that we have to remember that we have two halves of each chromosome and they carry vastly different information from each of our parents. Determining which is which is not always easy. If in doubt, disregard that segment.
Raw Numbers
So, what, really did I figure out after all of this?
First, let’s look at some numbers.
I was working with a total of 292 people who had at least one chromosomal segment that matched me with a Strong Native or Blended Asian segment. Of those, 59 also matched Mom’s DNA. Of those, 18 had segments that matched only Mom. This means that some of them had segments that also matched my father. Keep in mind, again, that we are only using “strong matches” which involves inferring Dad’s segments and that referring back to the original tools can always clarify the situation. There seems to be some specific areas that are hotspots for Native ancestry where it appears that both of my parents passed Native ancestry to me.
Many of my and my mother’s 59 matches have Acadian ancestry which is not surprising as the Acadians intermarried heavily with the Native population as well as within their own ethnic group.
Several also have Miller Ancestry. My Miller ancestor is Johann Michael Miller (1692-1771) who immigrated in the colonial period and settled on the Pennsylvania frontier. His son, Philip Jacob Miller’s (1726-1799) wife was a woman named Magdalena whose last name has been rumored for years to be Rochette, but no trace of a Rochette family has ever been found in the county where they lived, region or Brethren church history…and it’s not for lack of looking. Several matches point to Native Ancestry in this line. This also begs the question of whether this is really Native or whether it is really the Asian heritage of the German people. Further analysis, referring back to the admixture tools, suggests that this is actually Native. It’s also interesting that absolutely none of Mother’s other German or Dutch lines show this type of ancestry.
There is no suggestion of Native ancestry in any of her other lines. Mother’s results are relatively clean. Dad’s are anything but.
Dad’s Messy Matches
My father’s side of the family, however, is another story.
I have 233 matches that don’t also match my mother. There can be some technical issues related to no-calls and such, but by and large, those would not represent many. So we need to accept that most of my matches are from my Father’s side originating in colonial America. This line is much “messier” than my mother’s, genealogically speaking.
Of those 233 matches, only 25 can be definitely assigned to my father. By definitely assigned, I mean the people are my cousins or there is an absolutely solid genealogical match, not a distant match. Why am I not counting distant matches in this total? We all know by virtue of the AncestryDNA saga that just because we match family lines and DNA does NOT mean that the DNA match is the genealogical line we think it is. If you would like to read all about this, please refer to the details in CeCe Moore’s blog where she discussed this phenomenon. The relevant discussion begins just after the third photo in this article where she shows that 3 of 10 matches at Ancestry where they “identify” the common DNA ancestor are incorrect. Of course, they never SAY that the common ancestor is the DNA match, but it’s surely inferred by the DNA match and the “leaf” connecting these 2 people to a common ancestor. It’s only evident to someone who has tested at least one parent and is savvy enough to realize that the individual whose ancestor on Mom’s side that they have highlighted, isn’t a match to Mom too. Oops. Mega-oops!!!
However, because we are dealing in our project, on Dad’s side, with inferences, we’re treading on some of the same ground. Also, because we are dealing with only “strong clustered” segments, not all Native or Asian segments and because it appears that my parents both have Native ancestry. To make matters worse, they may both have Algonquian, Iroquoian or both.
I have also discovered during this process that several of my matches are actually related to both of my parents. I told you this got complex.
Of the people who don’t match Mother, 32 of them have chromosomal matches only to my father, so those would be considered reliable matches, as would the closest ones of the 25 that can be identified genealogically as matching Dad. Many of these 25 are cousins I specifically asked to test, and those people’s results have been indispensable in this process.
In fact, it’s through my close circle of cousins that we have been able to eliminate several lines as having Native ancestry, because it doesn’t’ show as strong and they don’t have it either.
Many of these lines group together when looking at a specific chromosome. There is line after line and cousin after cousin with highlighted data.
Dad’s Native Ancestors
So what has this told me? This information strongly suggests that the following lines on my father’s side carry Native heritage. Note the word “carry.” All we can say at this point is that it’s in the soup – and we can utilize current matches at our testing company and at GedMatch, genealogy research and future matches to further narrow the branches of the tree. Many of these families are intermarried and I have tried to group them by marriage group. Obviously, eventually, their descendants all intermarried because they are all my ancestors on my father’s side. But multiple matches to other people who carry the Native markers but aren’t related to my other lines are what define these as lines carrying Native heritage someplace.
- Campbell – Hawkins County, Tn around 1800, missing wife and parents, married into the Dodson family
- Dodson – Hawkins County, Tn, Virginia – written record of Lazarus Dodson camping with the Cherokee – missing wife, married into the Campbell and Estes family
- Claxton/Clarkson – Russell Co., Va, Claiborne and Hancock Co., Tn – In NC associated with the known Native Hatcher family. Possibly a son-in-law. Missing family entirely.
- Cook – Russell Co., Va. – daughter married Claxton/Clarkson – missing wives
- Harrold, Harrell, Herrell – Hancock Co., Tn., Wilkes Co., NC – missing wives
- McDowell – Hancock Co. Tn, Wilkes Co., NC, Augusta Co., Va – married into the Harrell family, missing wife
- McNeil, McNiel – Wilkes Co., NC – missing wives, married into the Vannoy family
- Vannoy – Wilkes County – some wives unaccounted for pre-1800
- Crumley – Greene County, Tn., Lee Co., Va. – oral history of Native wife, married into the Vannoy family
- Brown – Greene County, Tn, Montgomery Co., Va – married into the Crumley family, missing wives
While this looks like a long list, the list of families that don’t have any Native ancestry represented is much longer and effectively serves to eliminate all of those lines. While I don’t have “THE” answer, I certainly know where to focus my research. Maybe there isn’t the one answer. Maybe there are multiple answers, in multiple lines.
The Take Away
Is this complex? Yes! Is it a lot of work? You bet it is! Is everything cast in concrete? Never! You can see that by the differences we’ve found in data interpretation, not to mention issues like no-calls (areas that for some reason in the test don’t read) and cross overs where your inheritance switches from your mom’s side to your dad’s side. Is there any other way to do this? No, not if your minority admixture is down in that weedy area around 1%.
Is it worth it? You’ll have to decide. It guess it depends on how desperately you want to know.
Part of the reason this is difficult is because we are missing tools in critical locations. It’s an intensively laborious manual process. In essence, using various tools, one has to figure out the locations of the Native and Asian chromosome segments and then use that information to infer Native matches by a double match (genetic match at DNA company plus match with Strong Native/Blended Asian segment) with the right parent. It becomes even more complex if neither parent is available for testing, but it is doable although I would think the reliability could drop dramatically.
Tidbits and Trivia
I’ve picked up a number of little interesting tidbits during this process. These may or may not be helpful to you. Just kind of file them away until needed:)
- Matches at testing companies come and go….and sometimes just go. At Family Tree DNA, I have some matches that must be trembling on the threshold that come and go periodically. Now you see them, now you don’t. I lost matches moving from the Affy chip to the Illumina chip and lost additional matches between Build 36 and 37. Some reappeared, some haven’t.
- The start and stop boundaries changed for some matches between build 36 and build 37. I did not go back and readjust, as most of these, in the larger scheme of things, were minor. Just understand that you are looking for patterns here that indicate Native heritage, not exact measurements. This process is a tool, and unfortunately, not a magic wand:)
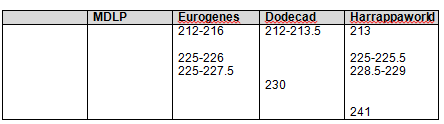
- The centromere locations change between builds. If you have matches near or crossing the middle of the chromosome, called the centromere, there may be breaks in that region. I enter the centromere start and stop locations in my spreadsheet so that if I notice something odd going on in that region, the centromere addresses are right there to alert me that I’m dealing with that “odd” region. You can find the centromere addresses in the FAQ at Family Tree DNA for their current build.
- At 23andMe, when you reach the magic 1000 matches threshold, you start losing matches and the matching criteria is elevated so that you can stay under 1000 matches. For people with colonial American or Jewish heritage, in other words those with high numbers of matches, this is a problem.
- Watch for matches that are related to both sides of your family. If your family lived in colonial America, you’re going to have a lot of matches and many are probably related to each other in ways you aren’t aware of.
- If your parents are related to each other, this process might simply be too complex and intertwined to provide enough granular data to be useful.
- Endogamous groups are impossible to sort through as to where, meaning which ancestor, the DNA came from. This is because the original group founders’ DNA is just getting passed around and around, with little or no new DNA being introduced. The effect of this on downstream generations relative to genetic genealogy is that matches appear to be more closely related than they are because of the amount of matching DNA they carry. For my Brethren and my Acadian groups of people, I just list them by the group name, since, as the saying goes, “if you’re related to one Acadian, you’re related to all Acadians.”
- If you’re going to follow this procedure, save one spreadsheet copy with the Strong Native only and then a second one with both the Strong Native and Blended Asian. I’m undecided truthfully whether the Mixed Asian adds enough resolution for the extra work it generates.
- When in question, refer back to the original tools. The answer will always be found there.
- Unfortunately, tools change. You may want to take screen shots. During this process, FTDNA went from build 36 to 37, match thresholds changed, 23andMe introduced a new user interface (which I find much less intuitive) and GedMatch has made significant changes. The net-net of this is when you decide to undertake this project, commit to it and do it, start to finish. Doing this little by little makes you vulnerable to changes that may make your data incompatible midstream – and you may not even realize it.
- This entire process is intensively manual. My spreadsheet is over 5500 rows long. I won’t be doing it again…although I will update my spreadsheet with new matches from time to time. The hard work is already done.
- This same technique applies to any minority ancestry, not just Native, although that’s what I’ve been hunting for and one of the most common inquiries I receive.
- I am hopeful that in the not too distant future many of these steps and processes will be automated by the group of bright developers that contribute to GedMatch or via other tools like DNAGedcom. HINT – HINT!!!
I would like to follow this same process to identify the source of my African heritage, but I’m thinking I’ll wait for the tools to become automated. The great irony is that it’s very likely in the same lines as my Native ancestors.
If You Want to Test
What does it take to do this for yourself using the tools we have today, as discussed?
If your parents are living, the best gift you can give yourself is to test them, now, while you still can. My mother has been gone for several years, but her DNA archived at Family Tree DNA was still viable. This is not always the case. I was fortunate. Her DNA is one of the best gifts she gave me. Not just by inheritance, but by having hers tested. I thank her every single day, for both! I could not have written this article without her DNA results. The gift that keeps on giving.
If you don’t have a parent to test, you can test several other family members who will provide some information, but clearly won’t carry the same amounts of common DNA with you as your parents. These would include your aunts and uncles, your parents’ siblings and what I’ve referred to as your close cousin circle. Attempt to test at least someone from each line. Yes, it gets expensive, but as one of my cousins said, as she took her third or 4th DNA test. “It’s only money. This is about family.”
You can also test your own siblings as well to obtain more information that you can use to match up to your family lines. Remember, you only receive half of your parents DNA, and your siblings will received some DNA from your parents that you didn’t.
I don’t have any other siblings to test, but I have tested cousins from several lines which have proven invaluable when trying to discern the sources of certain segments. For example, one of these Native segments fell on a common segment with my cousin Joy. Therefore, I know it’s from the Campbell line, and because I have the Campbell paternal Y-DNA which is European, I know immediately the Native admixture would have had to be from a wife.
Much of this puzzle is deductive, but we now have the tools, albeit manual, to do this type of work that was previously impossible. I am somewhat disappointed that I can’t pinpoint the exact family lines, yet, but hopefully as more people test and more matches provide genealogical information, this will improve.
If you want to play in this arena, you need to test at either Family Tree DNA, 23andMe, or both. Right now, the most cost effective way to achieve this is to purchase a $99 kit from 23andMe, test there, then download your results from 23andMe and upload them to Family Tree DNA for $99. That way, you are fishing in both pools. Be aware that less than half of the people who test at either company download results to GedMatch, so your primary match locations are with the testing companies. GedMatch is auxiliary, but critical for this analysis. And the newest tool, DNAGedcom is a Godsend.
Also note that transferring your result to Family Tree DNA is NOT the same thing as actually testing there. Why does this matter? If you want a future test at Family Tree DNA, who is the premiere genetic genealogy testing company, offering the most variety and “deepest” commercial tests, they archive your DNA for 25 years, but if you transfer results, they don’t have your DNA to archive, so no future products can be ordered. All I can say is thank Heavens Mom’s DNA was there.
Ancestry.com doesn’t provide any tools such as the chromosome browser or even the basic information of matching segments. All you get is a little leaf that says you’re related, but the questions of which segment or how are not answerable today at Ancestry and as CeCe’s experience proved, its unreliable. It’s possible that you share the same surnames and ancestor, but your genetic connection is not through that family line. Without tools, there is no way to tell. Ancestry released raw data files a few weeks ago and very recently, GedMatch has implemented the ability to upload them so that Ancestry participants can now utilize the additional tools at GedMatch.
Although this has been an extraordinarily long and detailed process, I can’t tell you how happy I am to have developed this new technique to add to my toolbox. My Native and African ancestors have been most elusive. There are no records, they didn’t write and probably didn’t even speak English, certainly not initially. The only clues to their existence, prior to DNA, were scant references and family lore. The only prayer of actually identifying them is though these small segments of our DNA – yep – down in the weeds. Are there false starts perhaps, and challenges and maybe a few snakes down there? Yes, for sure, but so is the DNA of your ancestors.
Happy gardening and rooting around in the weeds. Just think of it as searching for the very best buried treasure! It’s down there, just waiting to be found. Keep digging!
I hope you’ve enjoyed this series and that it leads you to your own personal genealogical treasure trove!

______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research