
 The questions I’ve received most often since the release of the new Family Finder Matrix from Family Tree DNA has to do with matches. Specifically, what the “In Common With” feature is telling you versus what the Family Finder “Matrix” is telling you and how to utilize all of this information together. At the bottom of this confusion is often a fundamental lack of understanding of how matching occurs and what it means in different contexts.
The questions I’ve received most often since the release of the new Family Finder Matrix from Family Tree DNA has to do with matches. Specifically, what the “In Common With” feature is telling you versus what the Family Finder “Matrix” is telling you and how to utilize all of this information together. At the bottom of this confusion is often a fundamental lack of understanding of how matching occurs and what it means in different contexts.
Let’s talk about this, step by step.
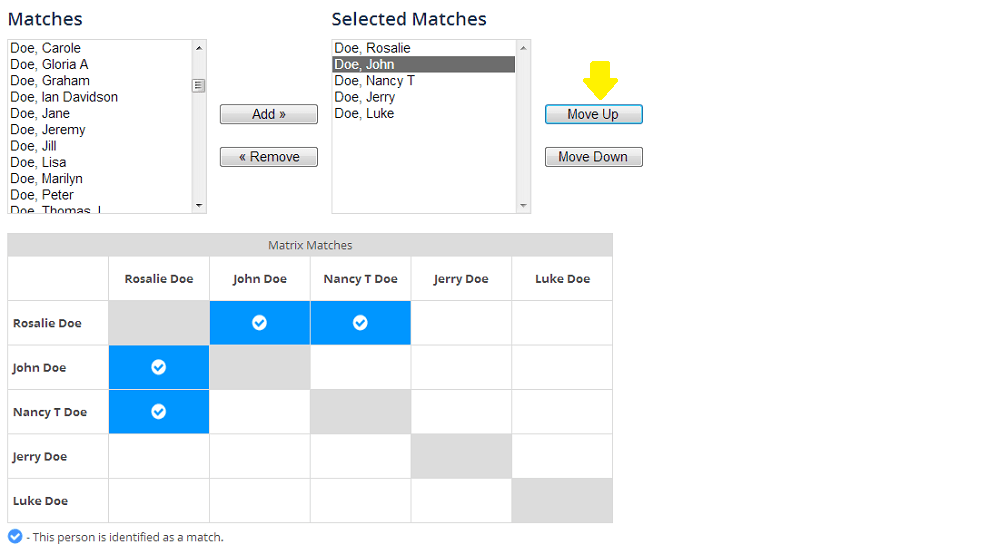
The “in common with” function (called triangulation for a few weeks, but now labeled “run common matches” ) shows you every person that you and one of your matches, match with in common. I’ll be running this option for my matches with cousin David, shown below.

Here’s an example of my matches in common with my cousin, David.

The Family Finder Matrix takes this information a bit further and shows you whether or not the people involved with this match, match each other as well.
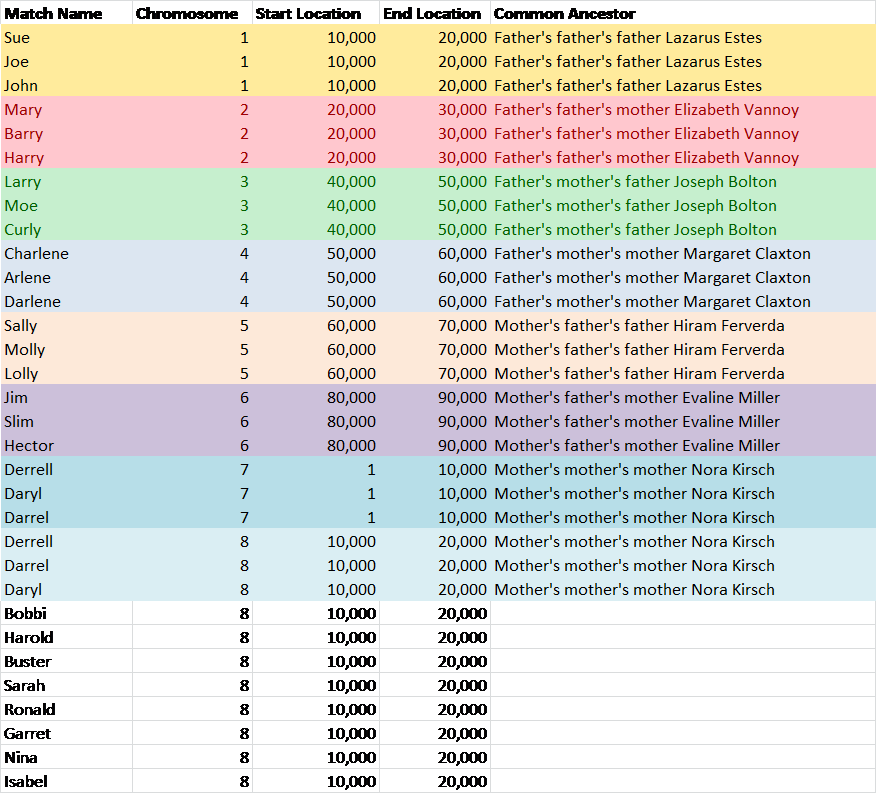
In this case, I happen to know that my cousins Harold, Carl and Dean will match each other on my father’s side, as will my cousin David. Warren doesn’t have firm genealogy, but from this, we can tell that he is indeed connected to this family group because he matches me, David, Harold and Carl, but not Dean and not Nova. We have no idea how Nova connects to this line, if she does. Notice that Nova does not match any of the other people in this group in the matrix below. That means that my and David’s common ancestor with her is likely not from this same ancestral line shared by Harold, Carl and Dean.

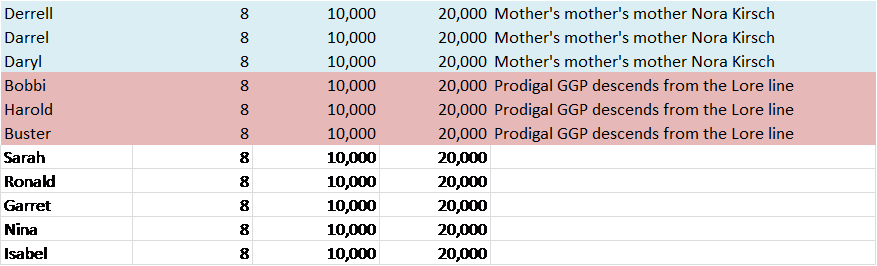
From this point forward, I would drop back to my trusty downloaded full match spreadsheet that I maintain to see if indeed any of these people match me and my known cousins on the same segments. If so, that confirms a family/ancestor relationship. On the snipped from my spreadsheet below, you can see that Warren indeed matches both Buster and David and I, but not on the same segments. Nova didn’t match any grouping on the same segments. However, Buster and David both match me on the same portion of chromosome 19, so this confirms that we do share a common ancestor. In this case, we also know, from our genealogy that the common ancestor is Lazarus Estes and wife, Elizabeth Vannoy. Based on our multiple cousin matches, we can say that Warren is somehow connected to this line, but we can’t say how.

I’ve had comments like “I have everything I need on my spreadsheet – I can see where all of my matches match me.” And indeed, you can, but it’s not everything you need. Here’s why.
Without additional information, you can’t tell, by just looking at your spreadsheet whether two people who match you on the same segment are matching on your Mom or Dad’s side. For example, above, I know that both David and Buster are from my Dad’s line, but if I didn’t know that, one of them could be from Mom’s line and one could be from Dad’s, and while they are both related to me, on the same chromosome, they would, in that case, not be related to each other. So, my spreadsheet of matches tells me clearly THAT people match me, and where, but it doesn’t tell me HOW or on which side. For that, I need additional tools like ICW, the Matrix and plain old genealogy research.
This is the fundamental concept of matching and in a nutshell, why it’s so difficult.
Every Chromosome Has Two Sides
There are two sides to every chromosome, Mom’s side and Dad’s side. Except nature has played a cruel trick on us and not installed a zipper. There are no Mom and Dad labels. There is no dividing that DNA or those matches in half magically, except by determing who they match, and how they do or don’t match each other.
When we match ourselves against our parents, for example, we then know immediately which half of our DNA came from which parent, but if you don’t have any parents available to match against, then you have to use genealogy or cousin matches to figure that out.
I talk about that in the Chromosome Mapping aka Ancestor Mapping article.
I’m going to use spreadsheets as examples here. It think they are easier to see and understand, plus, I can manipulate them easily to reflect different situations.
Example 1 – The Very Basics of Matching
At each DNA location, or address, you have two alleles, one from each parent. These alleles can have one of 4 values, or nucleotides, at each location, represented by the abbreviations T, A, C and G, short for Thymine, Adenine, Cytosine and Guanine. That’s it, you’re done with all the science words now, so keep reading:)
On any given chromosome, from locations 1-20, you have the following DNA, in our example.
From Mom, you received all As and from Dad, all Cs. You know that because I’m telling you, but remember, the matching software doesn’t know that because there is no zipper in your DNA. All the software sees are that you have both an A and an C in location 1 and either an A or C is considered a match.

In fact, this is what the software sees. Be aware that in this case, AC=CA.

Easy so far, right?
Example Two – Mom’s Known Cousin and Dad’s Known Cousin
Now you have two cousins, Mary and Myrtle. You know, from having known them all of your life and sharing lots of Thanksgiving turkey that they are your family and you know clearly which side of your family they descend from. Both of your cousins, Mary and Myrtle match you at the same locations on this chromosome, from 5-15.
But Mary is your mother’s cousin, and Myrtle is your Dad’s cousin. So even though they both match you on the same exact chromosome and the same location, they do not match each other. Well, let’s put it this way, if they also match each other, then you have an entirely different family genetic genealogy problem, called endogamy, and yes, you might be your own grandpa…but I digress. But we’re going to assume for this discussion that your mother and father are not related to each other and do not share common ancestors.

Still easy, right?
Example Three – An Unknown Cousin
Next, we have Martha. You don’t know Martha, and you don’t know how she is related, but she obviously is. Martha matches you, but she does not match Myrtle at all, and she doesn’t match Mary on enough overlapping chromosomes to be considered a match to her. You can see their common match here between Mary and Martha in location 5. In this case, as it turns out, Martha IS a cousin to Mary on Mom’s side, but we can’t tell that from this information because they don’t match in enough common locations to be above the matching threshold. With this information, you can’t draw any conclusions. You will have to wait to see who else Martha matches and look on your spreadsheet to see if Martha matches any of your known cousins and you on common segments which would confirm a common ancestor. Your download spreadsheet will contain much more detailed information because once you match on any segment above the match threshold of about 7.7cM (plus a few other factors,) all matching segments of 1cM or above are downloaded – so you have a lot of information to work with.
But using both the ICW and matrix tools, Mary might cluster with other cousins on Mom’s side which would provide us with clues as to her relationship. In fact, the first thing I’d do is to run an ICW with Mary and then utilize the Matrix tool to further define those relationships.

Still not difficult.
Example Four – A “False Match”
Next we have Jeremy who is also a match to you.

If you look at how Jeremy matches, you can see that he is actually matching on both sides, Mom’s and Dad’s side, but randomly. Technically, he is a match to you, because he does match one or the other of your nucleotides at each location, A or C, but without a zipper, we have no idea HOW that DNA is divided in you between Mom and Dad. In other words, the software doesn’t know that Mom was all A and Dad was all C, unless we’ve phased the data against your parents AND the software knows how to utilize that information.
However, if your parents are one of your matches, you can immediately see which side the match falls on, if either. In this case, Jeremy doesn’t fall on either side because he is simply a circumstantial match, also known as a match my convergence or a false match. This is also called IBS, or identical by state, as opposed to IBD, identical by descent. The smaller the segment you show as a match, especially if there is no clustering, the more likely the match is to be IBS instead of the genealogically desirable IBD.
When people ask how someone can match a child but not a parent, this is the answer. He matches you on 11 segments, circumstantially, but he only matches your parents on 5 and 6 segments, respectively, which often (but not always) puts him under the matching threshold. Jeremy may also match Mary, depending on the thresholds.
This is also how someone can match in the “in common with” tool, but not be a match to anyone on the match list in the Matrix. In fact, this is the power of these multiple tools.
This also doesn’t mean this match is entirely useless, because you DO match. It may simply not be relevant genealogically. In “The Autosomal Me” series, I’ve utilized very small match segments that in fact very probably ARE reflective of a common population and not of recent ancestry. In my Native American research, this is exactly what I was looking for. You may not be able to utilize this information today, but don’t entirely discount it either. Just set it aside and move on to a more productive match.
Example Five – Common Matches, Different Ancestors
This situation provides clues, but no proof.
Mary and Joyce both match me on Mom’s segments, but they do not match each other. They don’t match me on the same segments, so this indicates that they are probably from different ancestors in my Mother’s lines. As more matches appear, the clusters of people and their genealogy will make this more apparent.
In order to determine which ancestors, I’ll need to work on the genealogy of both Mary and Joyce and see who else they also match on the same segments. Sometimes the secret of the genealogy match is in the genealogy research or descent of your matches.

Example Six – Clusters of Cousins
In this example, no one matches Dad, so he’s just out for now. Susie and Mary match mom on the same segment, which proves that the three of these people share a common ancestor. Mom and Joyce match each other too, but Joyce doesn’t match Mary and Susie, so they won’t cluster together on the matrix. However, on the ICW tool, all three women, Joyce, Mary and Susie will match me and Mom.
Using the ICW tool if I were to ICW with Mom, you would see this list:
- Joyce
- Mary
- Susie
The question then becomes, are Joyce, Mary and Susie related to each other, or not. If so, and to me and Mom, then that indicates a common ancestor within the match group, like me, Joyce and Mom. The second group doesn’t match the first group – me, Mary, Mom and Susie. Using these tools together, these people clearly fall into two match groups, the green and blue on the spreadsheet below. But remember, the match routine doesn’t know which side your As and Cs came from. All it knows is that you match these people. But based on these groups and my download spreadsheet common segment matches, I can tell that I’m working with two ancestral lines.

My matrix for these people would look like this:

My master matching spreadsheet would now look like this.

When we started, all I would have been able to see is that all of these people matched Mom and Dad and I on the same segments. By utilizing the various tools, I was able to sort into groups and eventually, subgroups.
In fact, you can see below that within Mom’s pink group, there is also the smaller cluster of Mary, Susie, me and Mom.

For Jeremy and Martha, we can’t do any more right now, so I’ve recorded what we do know and set them aside.
Here, you can see the matches sorted by chromosome, start and end segment.

It looks a lot different than where we started, shown below, when all we had was a list of people who matched each other with no additional information. We’ve added a lot!

In Summary – Creating the Zipper
So, where are we with this?
By utilizing all of the tools at your disposal, including the ICW tool, the Family Finder Matrix, your matching spreadsheet and your genealogical information, you’re in essence creating that zipper that divides half of your DNA into Mom’s side and Dad’s side. Then into grandma’s and grandpa’s side, and on up the pedigree chart.
Each of these tools can tell you something unique and important.
The ICW tool tells you who matches you and another person, in common. It doesn’t tell you if they also match each other. This tool can provide extremely important clustering information. For example, if I see unknown cousin Martha clustered with a whole group of known Estes descendants, then that’s a pretty good clue about how I’m related to Martha. If, on the other hand, I find Martha clustered with people from both sides of my family, well, my Mom and Dad just might be related to each other or their ancestors went to or came from the same places.
By utilizing the Matrix tool, I can tell which of my matches are actually matching each other too, so that puts Martha in a much smaller group, or maybe eliminates her from certain groups.
By then utilizing my downloaded match spreadsheet, on which I record every known tidbit of genealogy information, even generalities like, “family from NC” if that’s the best I can get, I can then see where Martha matches me and others on the same segments, and based on the information in the ICW and the Matrix and my genealogy info, I may be able to slot Martha into a family group. On a great day – I’ll be able to be more specific and tell her which family group – like we were able to do with my newly found cousin, Loujean.
So, I hope you’ve enjoyed learning how to install a chromosome zipper. Now you can happily go about unzipping all of that genealogy information held in your DNA, that piece by piece, we’re slowing revealing.

______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research


























































{kind=link}