
The answer is, because inherited DNA segments do not always follow the 50% rule. I guess maybe no one told them???
Many times, when we receive our autosomal DNA results, we wonder why predicted relationships, particularly distant ones, aren’t accurate. Sometimes people estimated to be 3rd cousins, or maybe 2nd to 4th cousins, turn out to be 6th cousins, for example. This happens because genetic predictions must use math models and averages, but our actual DNA doesn’t follow those rules.
Dr. Steve Mount is an Associate Professor of Cell Biology and Molecular Genetics at the University of Maryland. In February 2011, he wrote an article about his experience submitting his DNA to 23andMe and his experiences matching his cousins. More specifically, he became interested in one particular segment of DNA trackable to a specific ancestor.
He shares these insights.
- Distant relatives (4th cousins and beyond) often share no genetic material at all.
- It is possible to share a segment with very distant relatives.
- Sometimes, more distant relationships are more likely.
- Most of your relatives may be descended from a small fraction of your ancestors.
In genetic genealogy, people who deal with autosomal DNA spend a lot of time trying to figure out which segments are IBD vs IBS – Identical by Descent versus Identical by State. In laymen’s terms, identical by descent means that you do in fact share a common ancestor in a timeframe in which you might be able to identify them. Identical by state really implies, technically, that you just happen to have the same DNA due to spontaneous mutations, not because you share a common ancestor. In reality, it’s taken to mean that you descend from a common population – in other words, you do share a common ancestor but the segment is so small that it implies that the ancestor is so far back in time that you can’t possibly identify them. Some people call these matches “false positives” which really isn’t accurate.
Far from being useless, these small segments are very useful in identifying different ethnic populations found in your ancestral tree and can, often in conjunction with larger segments also be useful in identifying ancestral lines. Discounting small segments, especially if you share a common ancestor, is akin to throwing away pennies because they aren’t as useful and are more difficult to manage than quarters or dollars. Furthermore, small segments may be our only way of identifying ancestors that are many generations back in our tree. After all, we inherited all of our DNA from some ancestor, no matter how small the segments are today.
Because we have no better rule of thumb (or statistical model), we utilize the theory that one inherits about 50% of the DNA of each ancestor in each generation. We know this is absolutely true between Mom and Dad, but you don’t receive exactly 25% of each of your grandparents’ DNA. However, the mixture of what and how much of your grandparents’ DNA you do inherit is approximately 25% and appears to be random, like a card shuffle. If it’s not random, we don’t know what the rules of inheritance are.
In the past few years, as we’ve come to work more closely with autosomal results, we have learned that while the rules of thumb about how much DNA you inherit from specific ancestors are useful, they are not absolute. In other words, it’s certainly possible to inherit a very large chunk of DNA from a very specific distant ancestor when the rules of probability and the rule of thumb of 50% would indicate that you should not.
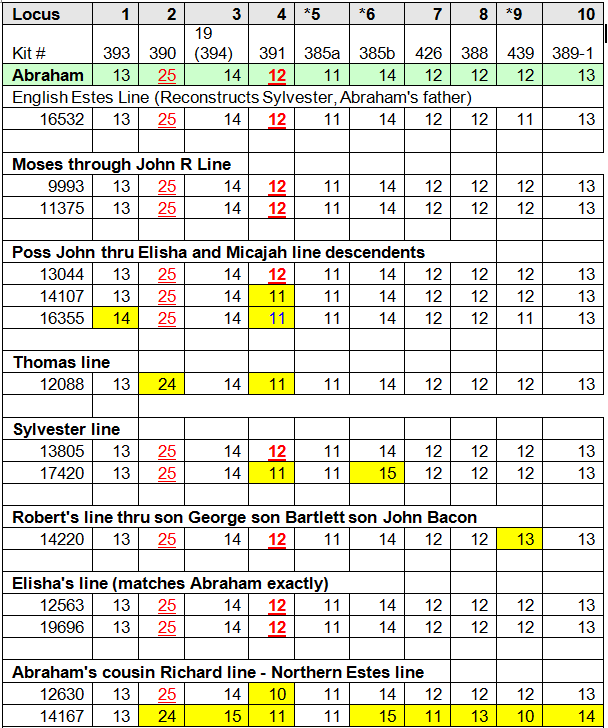
This is shown clearly in the Vannoy project where 5 cousins who descend from Elijah Vannoy born in 1786 (5 generations removed) share a very significant portion of chromosome 15. These people are all 5 generations or more distantly related from the common ancestor, (approximate 4th cousins) and should share less than 1% of their DNA in total, and certainly no large, unbroken segments. As you can see, below, that’s not the case. We don’t know why or how some DNA clumps together like this and is transmitted in complete (or nearly complete) segments, but they obviously are. We often call these “sticky segments” for lack of a better term.

I downloaded this information into a spreadsheet where I can sort it by chromosome. Below you can see the segments on chromosome 15 where these cousins match me. Note that Buster is also a cousin from a second ancestor.

Given these incidental discoveries and the very large amount of DNA I share with these cousins on chromosome 15, I was quite interested in Dr. Mount’s following commentary:
“The probability that fourth cousins share at least one IBD [identical by descent] segment is 77%, and the expected length of this segment is 10 cM.” Now consider the next step. There is a 50% chance that that one shared segment will not be transmitted at all, but a 90% chance that if it is transmitted it will be just as big as it was (the same 10 cM.). What this means for genealogy on 23andMe is that for two people sharing one segment identical by descent there is no way to reliably estimate how far back the common ancestor was. Furthermore, no improvement in software can possibly change that, because the limitation is imposed by the genetics itself.”
Well, there goes the 50% rule – flying right out the window. The 50% rule of thumb says that in any given transmission, there is a 50% chance that it will be transmitted (so good so far) and that if it is transmitted, roughly half of it would be transmitted, or approximately 5 cM.. That’s obviously not what is happening.
Dr. Mount goes on to say that, “No matter how far back you go, every nucleotide of one’s genome is derived from some ancestor, and even going back 20 generations, the chance that the bit which has been inherited is part of a block 5 cM. or greater is still appreciable. In fact, even for 19th cousins, there is a real chance (13%) that any segment of DNA they have inherited in common will be 5 cM. or greater. Of course, as mentioned above, there is very little chance that two 19th cousins will share any IBD segments at all, but this is offset if one has many 19th cousins, which is often the case.”
5cM is the line-in-the-sand cutoff number many genetic genealogists use to determine whether DNA segments are IBD or IBS.
What this really means is that the more distant, or 19th, cousins that you have, the greater the chance that one or more of them will test and will indeed share a piece of DNA large enough to be identified by the testing companies as relevant. The software companies will then apply their relationship estimating software to the size of the match and number of SNPs. The results are often inaccurate, as Dr. Mount says. Not inaccurate in that the match is incorrect, but the estimated relationship is incorrect because the DNA did not divide in half as the mathematical model says it should. The “problem” is not in the software, but in the DNA itself.
“23andMe reports a “predicted relationship” (e.g. “4th cousin”) and a “relationship range” (e.g. “3rd to 7th cousin”). However, these ranges are likely to be wildly inaccurate, because the likely distance to a common ancestor, given only the information that two people share a single IBD segment, can vary enormously, based largely on how many relatives one has.”
And I will add, it will also vary by how and how much the DNA has or has not divided in every generation.
Dr. Mount goes on to provide the math and probability formulas for these various calculations, and explains what they mean, in English, then he summarizes by saying, “
“Thus, if you have many more distant cousins, as would be expected if your ancestors had large families, then someone who shares a single IBD segment is more likely to be a distant cousin, because you have so many more distant cousins. The point where the increase in the number of cousins outweighs the loss of shared segments is five children per family. This is not extremely uncommon.”
This actually makes a lot of sense when I look at my results. One of my ancestors, Abraham Estes (1647-1720) had at least 12 children of which 11 reproduced and had very large families. This line was extremely prolific. Many of my autosomal matches include Estes descendants. Some of my other lines where my ancestor was one of just a few children have far fewer matches, likely because there are far fewer people out there descended from them.
Dr. Mount confirms this by saying that, “If one family among [your] 32 [great-great-great-grandparents] had five children and their descendants did as well, while others in the family reproduced at replacement rates (two children per family), then your more prolific ancestors (the parents of just one of your 31 great-great-grandparents) would account for over 3/4 of your fourth cousins.”
So what is the take away message to us from all of this?
- The autosomal testing companies are doing the best they can predicting your cousin-level relationships with what they have to work with.
- Real life genetic transmission does not follow the 50% rule of thumb beyond the first generation (parent-child).
- The predictions get more uncertain and therefore unreliable the more distant they are.
- Based on the unmeasureable randomness of the genetic transmission involved, there is no way for the testing companies to improve their predictions.
- Expect more matches to your more prolific lines, and less to lines who had fewer children.
- Beyond about the first or second cousin level, understand that predictions are only suggestions based on math. Given that you understand why and how reality can vary, you can then utilize this information when analyzing your matches.
- Drawing an arbitrary cM line for IBS vs IBD and utilizing only the segments above that threshold may eliminate the small segments you need to identify ancestors many generations removed.
- Endogamous populations throw a monkey wrench into estimates and calculations, because population members are likely related many times over in unknown ways. This makes the estimate of relatedness of two people appear closer than it is genealogically. At least one of the testing companies, Family Tree DNA, attempts to correct for this mathematically when they are aware of the situation, such as in Jewish families.
You can read Dr. Mount’s article including his mathematical proofs, here.
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research


















































{kind=link}