Recently, as a comment to one of my blog postings, someone asked how the testing companies can reach so far back in time and tell you about your ancestors. Great question.
The tests that reliably reach the furthest back, of course, are the direct line Y-Line and mitochondrial DNA tests, but the commenter was really asking about the ethnicity predictions. Those tests are known as BGA, or biogeographical ancestry tests, but most people just think of them or refer to them as the ethnicity tests.
Currently, Family Tree DNA, 23andMe and Ancestry.com all provide this function as a part of their autosomal product along with the Genographic 2.0 test. In addition, third party tools available at www.gedmatch.com don’t provide testing, but allow you to expand what you can learn with their admixture tools if you upload your raw data files to their site. I wrote about how to use these ethnicity tools in “The Autosomal Me” series. I’ve also written about how accurate ethnicity predictions from testing companies are, or aren’t, here, here and here.
But today, I’d like to just briefly review the 3 steps in ethnicity prediction, and how those steps are accomplished. It’s simple, really, in concept, but like everything else, the devil is in the details.
There are three fundamental steps.
- Creation of the underlying population data base.
- Individual DNA extraction.
- Comparison to the underlying population data base.
Step 1: Creation of the underlying population data base.
Don’t we wish this was as simple as it sounds. It isn’t. In fact, this step is the underpinnings of the accuracy of the ethnicity predictions. The old GIGO (garbage in, garbage out) concept applies here.
How do researchers today obtain samples of what ancestral populations looked like, genetically? Of course, the evident answer is through burials, but burials are not only few and far between, the DNA often does not amplify, or isn’t obtainable at all, and when it is, we really don’t have any way to know if we have a representative sample of the indigenous population (at that point in time) or a group of travelers passing through. So, by and large, with few exceptions, ancient DNA isn’t a readily available option.
The second way to obtain this type of information is to sample current populations, preferably ones in isolated regions, not prone to in-movement, like small villages in mountain valleys, for example, that have been stable “forever.” This is the approach the National Geographic Society takes and a good part of what the Genograpic Geno 2.0 project funding does. Indigenous populations are in most cases our most reliable link to the past. These resources, combined with what we know about population movement and history are very telling. In fact, National Geographic included over 75,000 AIMs (Ancestrally Informative Markers) on the Geno 2.0 chip when it was released.
The third way to obtain this type of information is by inference. Both Ancestry.com and 23andMe do some of this. Ancestry released its V2 ethnicity updates this week, and as a part of that update, they included a white paper available to DNA participants. In that paper, Ancestry discusses their process for utilizing contributed pedigree charts and states that, aside from immigrant locations, such as the United States and Canada, a common location for 4 grandparents is sufficient information to include that individuals DNA as “native” to that location. Ancestry used 3000 samples in their new ethnicity predictions to cover 26 geographic locations. That’s only 115 samples, on average, per location to represent all of that population. That’s pretty slim pickins. Their most highly represented area is Eastern Europe with 432 samples and the least represented is Mali with 16. The regions they cover are shown below.

Survey Monkey, a widely utilized web survey company, in their FAQ about Survey Size For Accuracy provides guidelines for obtaining a representative sample. Take a look. No matter which calculations you use relative to acceptable Margin of Error and Confidence Level, Ancestry’s sample size is extremely light.
23andMe states in their FAQ that their ethnicity prediction, called Ancestry Composition covers 22 reference populations and that they utilize public reference datasets in addition to their clients’ with known ancestry.
23andMe asks geographic ancestry questions of their customers in the “where are you from” survey, then incorporates the results of individuals with all 4 grandparents from a particular country. One of the ways they utilize this data is to show you where on your chromosomes you match people whose 4 grandparents are from the same country. In their tutorial, they do caution that just because a grandparent was born in a particular location doesn’t necessarily mean that they were originally from that location. This is particularly true in the past few generations, since the industrial revolution. However, it may still be a useful tool, when taken with the requisite grain of salt.

The third way of creating the underlying population data base is to utilize academically published information or information otherwise available. For example, the Human Genome Diversity Project (HGDP) information which represents 1050 individuals from 52 world populations is available for scrutiny. Ancestry, in their paper, states that they utilized the HGDP data in addition to their own customer database as well as the Sorenson data, which they recently purchased.
Academically published articles are available as well. Family Tree DNA utilizes 52 different populations in their reference data base. They utilize published academic papers and the specific list is provided in their FAQ.
As you can see, there are different approaches and tools. Depending on which of these tools are utilized, the underlying data base may look dramatically different, and the information held in the underlying data base will assuredly affect the results.
Step 2: Your Individual DNA Extraction
This is actually the easy part – where you send your swab or spit off to the lab and have it processed. All three of the main players utilize chip technology today. For example, 23andMe focuses on and therefore utilizes medical SNPs, where Family Tree DNA actively avoids anything that reports medical information, and does not utilize those SNPs.
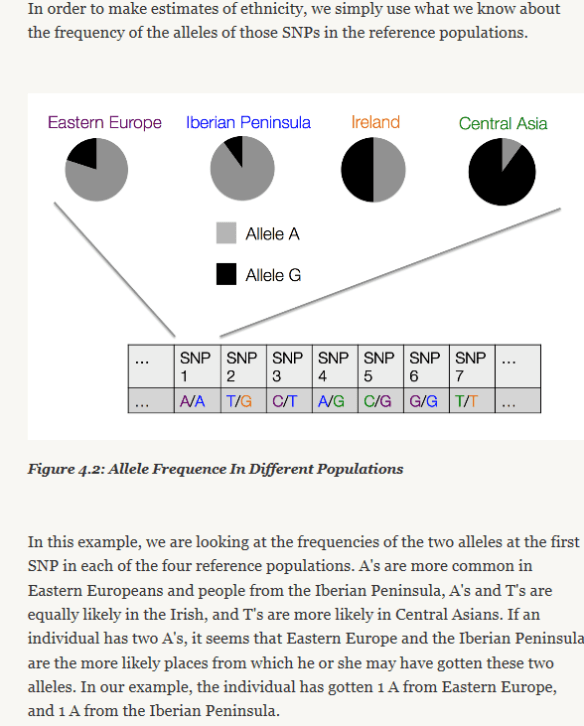
In Ancestry’s white paper, they provide an excellent graphic of how, at the molecular level, your DNA begins to provide information about the geographic location of your ancestors. At each DNA location, or address, you have two alleles, one from each parent. These alleles can have one of 4 values, or nucleotides, at each location, represented by the abbreviations T, A, C and G, short for Thymine, Adenine, Cytosine and Guanine. Based on their values, and how frequently those values are found in comparison populations, we begin to fine correlations in geography, which takes us to the next step.
Step 3: Comparison to Underlying Population Data Base
Now that we have the two individual components in our recipe for ethnicity, a population reference set and your DNA results, we need to combine them.
After DNA extraction, your individual results are compared to the underlying data base. Of course, the accuracy will depend on the quality, diversity, coverage and quantity of the underlying data base, and it will also depend on how many markers are being utilized or compared.
For example, Family Tree DNA utilizes about 295,000 out of 710,000 autosomal SNPs tested for ethnicity prediction. Ancestry’s V1 product utilized about 30,000, but that has increased now to about 300,000 in the 2.0 version.
When comparing your alleles to the underlying data set one by one, patterns emerge, and it’s the patterns that are important. To begin with, T, A, C and G are not absent entirely in any population, so looking at the results, it then becomes a statistics game. This means that, as Ancestry’s graphic, above, shows, it becomes a matter of relativity (pardon the pun), and a matter of percentages.
For example, if the A allele above is shown is high frequencies in Eastern Europe, but in lower frequencies elsewhere, that’s good data, but may not by itself be relevant. However if an entire segment of locations, like a street of DNA addresses, are found in high percentages in Eastern Europe, then that begins to be a pattern. If you have several streets in the city of You that are from Eastern Europe, then that suggests strongly that some of your ancestors were from that region.
To show this in more detailed format, I’m shifting to the third party tool, GedMatch and one of their admixture tools. I utilized this when writing the series, “The Autosomal Me” and in Part 2, “The Ancestor’s Speak,” I showed this example segment of DNA.
On the graph below, which is my chromosome painting of one a small part of one of my chromosomes on the top, and my mother’s showing the exact same segment on the bottom, the various types of ethnicity are colored, or painted.
The grid shows location, or address, 120 on the chromosome and each tick mark is another number, so 121, 122, etc. It’s numbered so we can keep track of where we are on the chromosome.
You can readily see that both of us have a primary ethnicity of North European, shown by the teal. This means that for this entire segment, the results are that our alleles are found in the highest frequencies in that region.

However, notice the South Asian, East Asian, Caucus, and North Amerindian. The important part to notice here, other than I didn’t inherit much of that segment at 123-127 from her, except for a small part of East Asian, is that these minority ethnicities tend to nest together. Of course, this makes sense if you think about it. Native Americans would carry Asian DNA, because that is where their ancestors lived. By the same token, so would Germans and Polish people, given the history of invasion by the Mongols. Well, now, that’s kind of a monkey-wrench isn’t it???
This illustrates why the results may sometimes be confusing as well as how difficult it is to “identify” an ethnicity. Furthermore, small segments such as this are often “not reported” by the testing companies because they fall under the “noise” threshold of between about 5 and 7cM, depending on the company, unless there are a lot of them and together they add up to be substantial.
In Summary
In an ideal world, we would have one resource that combines all of these tools. Of course, these companies are “for profit,” except for National Geographic, and they are not going to be sharing their resources anytime soon.
I think it’s clear that the underlying data bases need to be expanded substantially. The reliability of utilizing contributed pedigrees as representative of a population indigenous to an area is also questionable, especially pedigrees that only reach back two generations.
All of these tools are still in their infancy. Both Ancestry and Family Tree DNA’s ethnicity tools are labeled as Beta. There is useful information to be gleaned, but don’t take the results too seriously. Look at them more as establishing a pattern. If you want to take a deeper dive by utilizing your raw data and downloading it to GedMatch, you can certainly do so. The Autosomal Me series shows you how.
Just keep in mind that with ethnicity predictions, with all of the vendors, as is particularly evident when comparing results from multiple vendors, “your mileage may vary.” Now you know why!
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
Genealogy Services
Genealogy Research
Like this:
Like Loading...


 Delivery will be in 10-12 weeks and it will be accompanied by comparison tools.
Delivery will be in 10-12 weeks and it will be accompanied by comparison tools.