
Over the past few weeks there has been quite a bit of discussion surrounding phasing and matching of autosomal DNA. I’ve had several questions about what phasing is, why it might be important, and how phasing affects matching. These topics go hand in hand.
Phasing
One of the terms used in genetic genealogy is phasing. Many people don’t understand what phasing is, why it’s important, and that there are really two kinds of phasing.
The goal of phasing originally was to determine which side of our family, Mom or Dad, a piece of our DNA, and therefore a particular match, came from. As the industry has developed, phasing has taken on a slightly different meaning. Today, it’s often used generally to imply that phasing would improve our matches and therefore “should be done.”
These are really two kinds of phasing, used for two different purposes. Originally phasing was used to mean parent phasing. A second type, which I’ll call academic phasing, has wider applications. But first, let’s talk about why we need phasing at all.
Why Do We Need Phasing?
Because there is no zipper in our DNA. It would be very useful….very…if our DNA came in nice straight columns, with Mom’s on one side and Dad’s on the other. But that’s not how it works.
We carry two nucleotides in each inherited position, one from Mom and one from Dad. I discussed this in detail in this article.
Our autosomal DNA, when read, does not and cannot separate Mom’s contribution from Dad’s (except for the X chromosome in some situations, which we are not going to discuss in this article.)

In this example, Mom contributed all As and Dad contributed all Cs.
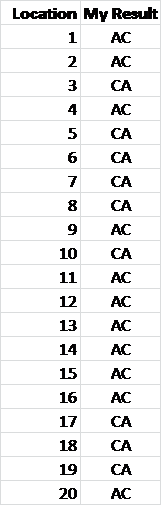
My results for these locations look like this – a mixture of Mom’s and Dad’s in no order. In other words, they are combined and I can’t tell the difference – at least not without either Mom or Dad’s data to compare against.

Ideally, if we could separate my values into Mom and Dad’s columns, like above, then we could match exactly against cousins from Mom’s side and from Dad’s side, because those cousins would also carry all As or all Cs in part or all of those locations, like in the example above.
In this case, I match both Mary and Myrtle, and Mary and Myrtle each match a respective parent.
This is the textbook case of IBD, or identical by descent.

But then, there’s Joe. I match Joe, because I carry both A and C at each of these locations. Joe, however, has alternating As and Cs. The acid test of whether I match Joe by descent (IBD) or by chance (IBS) is if Joe matches my parents.
In this case, as you can see, Joe does not match my parents. Because my matches to both Mary on my mother’s side and Myrtle on my father’s side are IBD, Joe also does NOT match Mary or Myrtle.
This is the underlying foundation of why we use triangulation and can say that if three people with a known ancestor all match each other, we can map that segment as IBD, identical by descent, from that known ancestor.
In fact, the definition of a proven ancestral “match” in genetic genealogy is when:
- Two or more people match you on a particular segment
- Those people also match each other on the same segment
This is true whether or not you’ve been able to identify the ancestor responsible for those shared segments.
Let’s look at how that works.
In the following example, you can see that Mary, Anne and Sue all match Mom, because they all have all As. They also match me, because I have an A and a C in each location, so they match my A, but they do not match Joe who has alternating As and Cs. So you can see that I am the only person in the group that Joe matches. This is how we know that Joe is an IBS by chance match and this particular matching segment for Joe can be eliminated as a valid match to me.

Let’s also say that I know that Anne, Sue and Mary descend from my mother’s Miller line and that Henry, Harold and Myrtle descend from my father’s Vannoy line. So, in this case, I have proven triangulation of myself, my parents and 3 other known individuals with the same genealogy lines. These segments are now considered proven to those particular ancestors or ancestral lines because there is no other way for all of us to share these segments other than sharing a common ancestor.
This is also the basis upon which we can infer that our parents carried a particular piece of DNA if we don’t have their DNA to compare – because that’s the ONLY way we could have acquired that DNA segment – through that parent.
So let’s look at this exact same situation if we don’t have either parent’s data to utilize. You can see that Mom and Dad are missing from this next example.

If three cousins all share that same segment of DNA, it HAD to come from a common ancestor, and one or the other of our parents HAD to have carried it too.
You can see that while we don’t have the benefit of our parent’s DNA in the above example, that Joe still matches me. Anne, Sue and Mary still all match each other, as do Henry, Harold and Myrtle. But Joe does not match any of the known cousins. We can therefor determine that Joe’s DNA, on this particular segment, is IBS by chance, not IBD, so not inherited from a common ancestor. Therefore, we can discard Joe as a valid match on this segment. This does NOT infer that Joe might not be a valid match on other segments, just not on this segment.
So, there are two ways to determine IBS by chance segments.
- To compare your matches on that segment against both parents.
- To compare your matches on that segment against proven genealogical matches from both sides of your tree.
For specifics of how to do this, also refer to the Chromosome Browser War article and for the basics, to the Ancestor Mapping article.
Now, let’s remove Joe, who doesn’t match, and see what our segment match looks like.

All of these people match me, because I carry an A and a C, one from each parent. With my parents DNA included, I can tell immediately where the matches occur.
I’m fortunate that I have my mother’s autosomal DNA. That means that I can do “poor man’s phasing” by comparing my results against at least one parent. The people who don’t match me and my mother must match me and my father or they are IBS by chance.
But even without any parents, because I know that the green people share a common Miller ancestor and the blue people share a common Vannoy ancestor, we can clearly identify that these people match, and why – and we can infer that our parents had this same DNA because there is no other way for us to obtain it.
Now let’s look at one final situation where we have Nancy who doesn’t know how her genealogy connects. Let’s say she is an adoptee.

You can see very clearly where Nancy matches me and my mother’s proven cousins. She does not match my father’s proven cousins.
I’m sure I don’t need to tell you at this point that Nancy shares a common ancestor with our Miller line. We may not know who, at this point, but by studying the genealogy of these people and others who also match, we may be able to narrow it down quite substantially.
So, in a nutshell, phasing against a parent, or both parents, determines quite accurately which side of our family tree a match comes from.
We can do that same thing in essence by finding cousins who all match on the same DNA segment and share a common ancestor. This is why testing multiple cousins is so important. Once that segment of our DNA is mapped to an ancestor or ancestral line, we know that anyone else who also matches at least two other people with that same segment also share this same genealogical line at some level.
No Parent DNA
Phasing is fine and dandy if you have the DNA of one and preferably both of your parents, but probably more than 50% of the genealogists don’t have that luxury.
In the adoptee community, they not only don’t have their parents DNA to test, they don’t have a pedigree chart so they can’t even utilize triangulation techniques with cousins or people with a shared genealogy. This is why they attempt to piggyback off of our already triangulated data to a particular ancestral line – again, based on the proven concept that if you match a group of 3 other people who have triangulated – you too inherited that DNA from a common ancestor with those people.
In the example above, Anne, Sue, Mary and I match on that DNA segment and know that our common ancestral line is that of Johann Michael Miller. Since Nancy, an adoptee, matches us, she too is descended in some fashion from the Johann Michael Miller lineage (upstream or downstream – meaning possibly a wife’s line) as well.
What about all of the matches that we have that we can’t attribute to one side or the other, or those people like adoptees who don’t have any pedigree chart or parent’s data to work with?
Obviously, they can’t utilize phasing in the typical sense. Nor can companies figure out our genealogy and apply it to our DNA results – that’s up to us – with the possible exception of a parent match.
A second type of phasing is being used to attempt to reduce the number of IBS matches by both chance and population.
Academic Phasing
In academia, in order to study populations, computer programs were written to attempt to sort through data for likenesses and differences. The goal, for genetic genealogists is to find segments that are IBD, identical by descent and eliminate others that are either IBS by chance or IBS by population.
What academic phasing programs like Beagle attempt to do is to sort through populations and determine the most likely combinations of nucleotides found, and thereby extrapolate IBD vs IBS.
These programs have inherent problems, not the least of which is that they are not created to deal with an ever increasing data base size where hundreds (if not thousands) of new records are added daily. Ancestry, when faced with the problem of a rapidly increasing data base of over half a million DNA testers who were accumulating matches in the thousands, tried to address this. Ancestry’s problem is only growing, which is one of those wonderful business problems to have. In order to attempt to reduce the number of matches and improve those matches, they created their own technology relative to phasing, which they detailed in a white paper released with their new DNA Circles feature. The jury is still out on how well they succeeded.
Inherent to all of the academic phasing programs is the challenge that the vendor (or whomever) involved must decide where to draw the line between what they consider to be useful and not useful. Ancestry did not tell us their criteria for determining the cutoff that they used in their proprietary phasing program.
However, we can determine some things based on the graph they did provide to each of the attendees during DNA Day. They gave us a “before phasing” and “after phasing” picture of our own genomes as compared with our matches. We’ve talked before about the pileup areas that Ancestry discovered based on their phasing. Please note that I’ve used my own chart in this example, but based on the charts of others at the same meeting, each person’s was quite different – so the numbers here are provided only as examples utilizing my own information.

This is my genome compared to my matches before Ancestry reduced my matches after phasing.

This is my genome compared to my matches after my pileup reduction surgery.
In this second chart, you can see, that for me, they have drawn the line at about 25 common matches as being a relevant cutoff point, out of just under 13,000 prior matches. Please note that this cutoff of about 25 is my cutoff point. Yours might be quite different – but there is no way of knowing.
This looks like locations where I had more than 25 matches, out of 13,000, were determine to be “too matchy” and therefore a pileup area. Now, given that I descend from at least four endogamous populations, the Mennonite, Brethren, Acadians and Native Americans, I would suggest that I would expect to have more than 25 matches on some of the same segments within these populations groups – especially those closer in time and with many descendants. At Family Tree DNA, where I have 770 matches, I have matches with more than 25 people with Acadian ancestry. If you extrapolate only the 25/770 number at Family Tree DNA (which is low) to 13,000 matches, I would expect to have over 400 Acadian matches at Ancestry – which might explain why I lost all of my Acadian matches at Ancestry.

It appears in my first chart that the cutoff line is drawn at about the location of this arrow – if you drew a line straight across at that location from left to right. It appears from looking at this, that I didn’t lose that many matches, but I did. I went from 12,846 to 3,350 or a reduction of about 75%. I’m not bemoaning the loss of the number of matches, because as they were, they weren’t terribly useful.
However, I did lose all of my known Acadian matches. In other words, in some cases, the matches may have gotten pruned too far. Now truthfully, at Ancestry, since we don’t have analysis tools, this really doesn’t matter much to me.
I’m only using this example because it’s the only concrete example that we have today of academic phasing applied to a commercial data base and the effects of utilizing academic phasing and applying it commercially to prune our matches. In my case, I found it extremely interesting to see the large pileup area and I would just love to see where that maps to on my chromosome spreadsheet, and if there is anything remarkable about it. Is it my Acadian matches, or is it truly an amalgamation of miscellaneous matches from Europe (or someplace else) with no story to tell? I’m fine with either answer, but I can’t now and will never be able to know.
In any event, this type of phasing is used in essence to prune our trees universally by determining which matches are more legitimate and which are less so.
To date, Ancestry is the only vendor to implement this type of phasing.
Felix Immanuel discusses phased data, IBS and endogamous societies in his article, “Why phasing DNA is bad for valid and close matches.”
Phasing Summary
There are two types of phasing. The first, which is phasing to parents and known family data is achievable by genetic genealogists. We have been utilizing a form of “poor man’s” phasing for a long time now where we compare known matches to one or both of parents and selectively remove matches that match us but not either parent. Of course, you need both parents to do this reliably.
The second type of phasing, academic phasing, is still more of an unknown in terms of how it truly affects the accuracy of our genealogy matches. Ancestry has created a proprietary form of phasing optimized for large data bases and while we have seen the first generation of phased data, the jury is still out as to the success of this tool, in part, because we don’t have any tools like chromosome browsers and matrix matching tools to confirm the that the matches we have or lost were and are both genetic and genealogical matches.
Now that we understand how phasing works relative to matching, let’s talk about what an IBD and IBS match are, and why that’s important.
IBD vs IBS
When two people have a match on a autosomal DNA segment, it can either be identical by descent, IBD, or identical by state, IBS, although IBS really should be broken into multiple categories. In some cases, IBS can become IBD, but in the situation where the IBS match is actually false, it is simply not a valid match. Let’s talk about how to tell the difference.
Matches between any two people on a particular segment can be due to any of the following situations.
- A valid IBD, meaning identical by descent, match where the segment has been passed from one specific ancestor to all of the people who match. That matching segment can be labeled and utilized as such. In these cases, we know, for example, that the segment is passed to the descendants of a specific ancestor or ancestral couple.
- An IBS match, meaning identical by state, which is called that because we can’t yet identify the common ancestor, but there is one. So this is actually IBD but we can’t yet identify it as such by connecting it with an ancestral line. So this really isn’t IBS. With more matches, we may well be able to identify it with its contributing ancestor. As more people test and larger data bases and more sophisticated software become available, these matches will fall into place. Some people refer to any match they can’t identify as IBD as IBS.
- An IBS match that is population based. These are often difficult to determine, because this is a segment that is found widely or within in a specific population. It is passed from your ancestors, but this segment may be found in a large part of the population they descend from. The key to determining these pileup areas is that you may find this same segment matching different proven lineages. I’ve found a couple of areas where I appear to have matches from my mother’s side of the family from different ancestors – so these areas are potentially IBS on a population level. That does not, however, make them completely irrelevant. In fact, this article speaks to how one genealogist noticed and worked with a group of 22 matches that appear to be IBS by population which are quite relevant to her genealogy.
- An IBS match that is a false match, meaning the DNA segments that we receive from our father and mother just happen to align in a way that matches another person. Generally these are relatively easy to determine because the people you match won’t match each other. You also won’t tend to match other people with the same ancestral line, so they will tend to look like lone outliers on your match spreadsheets, but not always. I refer to these as IBS by chance, to distinguish them from IBS by population.
So, actually, there are three kinds of IBD and only one kind of IBS, which is by chance. This is because you do inherit DNA referred to as IBS because you don’t know which ancestor it is inherited from, and you do inherit IBS by population DNA from your ancestors, by descent. The only IBS that is actually inherited by state is a false match or IBS by chance. So, word to the wise – when someone tells you a match is IBS, ask what they mean and how they know.
Regarding IBS by chance, Felix Immanuel Chandrakumar (formerly Felix Chandrakumar) has been analyzing the probability of IBS matching. His interest was spurred because contrary to what had been expected, there are matches among living people to some of the ancient DNA results and at levels that, if interpreted today, would suggest a relationship in a genealogical timeframe. This means that these segments must be either IBS by population, meaning passed down within a population through a specific ancestor (and parent) to the living person, or they are IBS by chance and not relevant, although many of these matches have been phased against parents.
Felix’s article, “The true IBS noise range” discusses his findings that a true noise or false IBS segment cannot occur above the threshold of 150 SNPs at the 1MB threshold.
In addition, he generated a “noise file” which would allow people to see just how often they actually would match any segments down to 1cM and 100 SNPs just by chance. It is kit F999901 and surprisingly, not one person in the GedMatch data base matches at any segment.
The challenge of course is differentiating between these types of matches and then using that information to tell us something about our ancestry, either genealogically, meaning a specific ancestor, or ethnically, meaning that a segment of our DNA descends from a particular group of ancestors, like Acadians or Native Americans or Finns.
To do this, we need to map our chromosome segments to ancestors, but there are very few people actually mapping their chromosomes to ancestors. Why? Because it’s tedious and it certainly is not the “quick answer” many of us would like. Hopefully, the IBS and IBD guidelines below will help people better understand and categorize matches.
Guidelines for Determining IBS vs IBD
As mentioned previously, there are really 4 kinds of DNA segments. I’ve developed some guidelines for how to identify each type of match and attempted to quantify them below.
| Segment Type | Characteristics – Definition | How to Identify |
| IBD – Identical by Descent | Can determine a common ancestor. Let’s say that we know that Mary, in our example, shares the ancestor Johann Michael Miller on my mother’s line. I label this segment IBD on my spreadsheet with the name of our common ancestor. | For genealogy matching of previously unknown cousins, at least three people match with a common segment and a common ancestor. In closer family, such as parents, grandparents, sibling and known close cousins, this three match criteria is not needed. Larger segments are much more likely to be IBD. |
| IBS that will be IBD | The segment is really IBD, but since we don’t know which ancestor contributed the segment, yet, it sometimes gets labeled it IBS. Let’s say this is Myrtle, and she matches us and others on the same segments, but we don’t know which ancestors contributed that segment. More genealogy work and/or more testers who know their pedigree charts will make determining the common ancestor more likely to occur. | Matches parents and/or multiple (sometimes close) known family members on the same segments. Sometimes the steps to identifying the common ancestor is to first identify a common surname or geography and pursue from that point, although multiple common surnames can occur that are not necessarily relevant. I have some people that I am genealogically related to on two different lines, but any one segment can only be contributed by one ancestral line. |
| IBS by population | These segments truly are IBD, but since they exist in a large population, you may see matches on these segments from multiple ancestors. Typically these are small because they have been passed within a population for a very long time, although based on the Anzick ancient DNA matches, they are not always small. Often, in population genetics, these would or could be called AIMS or Ancestry Informative Markers, meaning that they show up in a particular population at higher levels than elsewhere. Are these useful to genealogy? It depends on what you are looking for and the frequency at which they are found in any given population. They wouldn’t be terribly useful in terms of European genealogy, if you’re primarily European, but if you have minority admixture, finding one of these IBS by population segments would be extremely informative. | Indicated by areas where you find matches from multiple family lines on the same side of your family, on the same segment. These would be pileup areas. Alternatively, they can be segment areas where you notice a specific trend, like matches are primarily Acadian, or Finnish, etc. I label these segments, but I don’t discard them. IBS by population matches are generally, but not always, found in smaller segments, as shown by the ancient DNA matches. |
| IBS by chance | The example I used with Joe. False matches that match only by the luck of the draw in how the 2 strands of DNA was distributed in the two people who match. | When matching against both parents, IBS by chance can be discerned when a match matches you, but does not match either of your parents on that segment. If these segments are “larger,” 5 or 7 cM or with more than 500 or 700 SNPs, this could be due to a data read error or “no calls” in the parent’s file. You may want to check the original data file before disregarding the segment. If you don’t have both parents, but you do have triangulated cousins on both sides of your family on this same segment, you can still triangulate by determining if a match matches you and either set of cousins. If not, then the match is IBS by chance. Generally, I simply label these “IBS by chance” and leave them in the spreadsheet so I don’t confuse myself by coming across them again, but they could be discarded. The smaller the segment, the more likely it will be IBS by chance but all smaller segments are not IBS by chance. |
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research
Share this:

Discover more from DNAeXplained - Genetic Genealogy
Subscribe to get the latest posts sent to your email.
Reading any/all of your posts is exactly like taking a class – so much relevant detail, so well explained. Whew! I enjoy it so much even though the information is definitely a challenge for me to get my head around. Thanks so much for your wonderful posts on DNA and genealogy.
Okay, my eyes kind of glazed over at the title, but then as I started to read, I thought, this pretty soon will be something I need to understand. So I read and glad I did. Phasing makes sense and I have new knowledge to apply to my own DNA data. Thanks for taking the time to explain phasing. El–
Roger that, Celia Lewis and El Jones! I personally won’t recall a word of this article. It seemed WAY over my head but, Roberta, you explain things in such a way as to make it understandable. Your articles are so well indexed I don’t have to remember them. I only need to know where to find them. Albert Einstein once said that he never memorized anything he could look up. Your articles are like an Encyclopedia of DNA Research for the layman.
Thank you Ron!!! Yes, the search button is everyone’s friend. Mine too.
I tried kit# F999901 but GEDmatch results say “no kit found”.
Bravo! Roberta.
Thanks for a great article on phasing!
I still think AncestryDNA (knowingly or unwittingly) has waved their scientific/marketing wand and implied a lot more value to across-the-boards population phasing than exists.
Other than generally duping customers, like you say, it really doesn’t mean much. We can only see their data through GEDmatch – and then it is put through exactly the same algorithm filter as the FTDNA and 23andMe data. We won’t really know much until a lot of the Ancestry data is mapped and/or we can link some Ancestry results to GEDmatch kits (not an easy task).
Thanks again for a great lesson.
Jim – Sent from my iPhone – FaceTime!
>
Good explanation for this learning genetic genealogist.
Thanks. I’ve saved this for future reference.
I have a question I hope you can help with. Regarding the ancestry pruning, do we know if close relatives are excluded from the 25? Let’s say we have an enthusiastic hobbyist that tests multiple family members. Or someone who gifts cousins kits for Christmas. Or adoptees that sponsor multiple tests as they zero in on a prime suspect. Do these get distorted match counts and therefore start losing folks disproportionately to the general public that is one and done?
I can’t answer your question exactly. Ancestry did say that they take closely related people into account when creating circles, but they weren’t specific beyond that. From what I saw, the 25 was my personal threshold. Other peoples would be different depending on their results, so I think everyone’s threshold is probably somewhat unique and based on where Ancestry feels your matches turn from real into population or identical by chance.
AncestryDNA admits it’s phasing effort is experimental and that it’s Circles feature is in “beta.” AncestryDNA is exploiting people who are dumb enough to pay $49 a year for something that gives them fewer matches (correctly or incorrectly) and without showing us the proof provided by a chromosome browser. I just wish FTDNA would allow those of us who have a living parent or parents to do “true phasing” with Family Finder. If Gedmatch can do this, why not FTDNA?
I found this article very informative but I’m not sure how to apply it in working with my FTNA results and in particular the Chromosome Browser. How do the letter codes you used in your example relate to what you see when you compare people to yourself there? I usually get more out of pictures than lists of data so I generally work with the chromosome diagram. Does the table form of the results make more sense in this kind of analysis?
Here’s an example of something I’m trying to make sense of. I have a match with someone named Nanci. In corresponding we decided that it as an X connection and indeed when I map her, her mother and her uncle onto my chromosomes all three of them align almost perfectly with me in several places. Interestingly, her brother does not match as well although he does match. Is there something to be gleaned here? Their relationships are known. Their relationship to me is unknown. Does what I’m seeing clearly indicate an IBD relationship between us? What else should I be looking at? I can supply a screen shot of the browser result if that would help make sense of what I’m saying.
In the article, Chromosome Browser War, I reviewed how to utilize the various tools at both 23andMe and at FTDNA. From what you’ve said it certainly sounds like you have an IBD match because you have three known people matching plus a 4th unknown. In this case, you’re the unknown. Utilize both of your X trees to at least eliminate some of the branches hat can’t be the common source. Look at who else matches too and see if any of these share a common ancestor.
I am curious about IBS/IBD small segment matches. I have results for my mother, two siblings and myself on gedmatch. I have noticed that two, three or all four of us may match someone in the exact same spot, albeit a small match, say 3.5 cM. If all of us match, even though it is small, is it more likely to be an IBD match rather than IBS?
I would certainly say that it is. I have an article about that coming out shortly.
My Alperovich family descends from a married couple born about 1670. This couple moved to Kurenets, Belarus in about 1700, and had 8 children. Today, ~25 of the descendants of this couple have done the FF test, and we are all on GedMatch. I am unsure if our shared segments that are <5 cM are all false-positives.
I've done two major triangulation projects of these 25 Alp cousins of mine. The first includes all those 5 cM. These Alps of mine lived in Kurenets for ~200 years, and married each other all the time.
My question is: Can I assume that the 3-5 cM segments are positives, especially when they triangulate with >5 cM segment?
ANDI ALPERT ZIEGELMAN
I would say that they probably are, but always keep in mind that they could also be IBS by population.
In my earlier post today, there is an error. Somehow my comment about the second project that I did is not in the post. The second major triangulation project that I carried out on GedMatch, using the kits of my 25 Alp cousins, included also segments that are 3-5 cM.
Is it not correct that once you have identified Anne, Mary and Sue as being on your mother’s side with all those As, you would know your father to be all Cs even without any input at all from Henry, Harold or Myrtle?
If you have A and C, and the known people on your mother’s side are all A, and the people on your father’s side are all C and don’t match the A’s then they have to be from your father’s side and one of his values has to be C. Or I’m missing the question?
Pingback: Friday Finds – 01/09/15
Pingback: Just One Cousin | DNAeXplained – Genetic Genealogy
Pingback: Demystifying Autosomal DNA Matching | DNAeXplained – Genetic Genealogy
Pingback: A Study Utilizing Small Segment Matching | DNAeXplained – Genetic Genealogy
This has been bothering me for a while…. If one has both parents available (and willing) to undergo DNA testing, what is the advantage of phasing at all? Or, indeed, any sort of DNA testing on the child, if the purpose of the investigation is “up” (i.e., ancestors of the child)?
You’re right Steve. In my case, I’m the one that was originally interested, so I tested first. Then I added my Mom when I realized there would be a benefit. I’d have added Dad too if I could. So in many cases, I think it’s a matter of who is originally interested in the testing.
Pingback: Parent-Child Non-Matching Autosomal DNA Segments | DNAeXplained – Genetic Genealogy
Pingback: What is a Population Bottleneck? | DNAeXplained – Genetic Genealogy
Pingback: 4 Generation Inheritance Study | DNAeXplained – Genetic Genealogy
Roberta
In the fourth table above you introduce Joe for the first time
And you state he does not match your parents
At Chromosome 5, Joe and your mom and Mary are all A
Why isn’t that a maternal match?
Mike
To match my Mom, he would have to have all As, so he matches her on every other locatio. He is zigzagging back and forth between matching my Mom and Dad.
Thanks Roberta
In your example table, matching at all locations is the standard you have set for this visualization example.
In a “live data” comparison, Joe could match your mother at one chromosome only,
and this might still be an IBD match. If I am starting to grasp the concept anyway.
Mike
He could match my mother anyplace else. This only speaks to this example area. Think of these rows as houses on a street. The problem is that Mom’s house and Dad’s house, albeit two separate houses on the same lot, have the same address. So someone has to match Mom at all of Mom’s addresses on the street to be considered a match. The street in this example is a segment and the chromosome is made up of many segments.
Pingback: Autosomal DNA Matching Confidence Spectrum | DNAeXplained – Genetic Genealogy
Pingback: DNAeXplain Archives – Intermediate DNA Articles | DNAeXplained – Genetic Genealogy
Pingback: Ancestry’s New “Amount of Shared DNA” – What Does It Really Mean? | DNAeXplained – Genetic Genealogy
Pingback: The Best and Worst of 2015 – Genetic Genealogy Year in Review | DNAeXplained – Genetic Genealogy
Pingback: We Match…But Are We Related? | DNAeXplained – Genetic Genealogy
Pingback: Ethnicity Testing – A Conundrum | DNAeXplained – Genetic Genealogy
In the examples, you are AC, but everyone else only has a single “letter”. How does the fact that all subjects actually have two “letters” (just like you) affect matters?
Those are the relevant markers that person carries – meaning relevant to you. In other words, if you inherited an A from your Mom, only the A is relevant to you. It doesn’t matter is her other nucleotide was a T.