
One of the questions I receive rather regularly is about the difference between STRs and SNPs.
Generally, what people really want to understand is the difference between the products, and a basic answer is really all they want. I explain that an STR or Short Tandem Repeat is a different kind of a mutation than a SNP or a Single Nucleotide Polymorphism. STRs are useful genealogically, to determine to whom you match within a recent timeframe, of say, the past 500 years or so, and SNPs define haplogroups which reach much further back in time. Furthermore SNPs are considered “once in a lifetime,” or maybe better stated, “once in the lifetime of mankind” type of events, known as a UEP, Unique Event Polymorphism, where STRs happen “all the time,” in every haplogroup. In fact, this is why you can check for the same STR markers in every haplogroup – those markers we all know and love.

This was a pretty good explanation for a long time but as sequencing technology has improved and new tests have become available, such as the Full Y and Big Y tests, new mutations are being very rapidly discovered which blurs the line between the timeframes that had been used to separate these types of tests. In fact, now they are overlapping in time, so SNPs are, in some cases becoming genealogically useful. This also means that these newly discovered family SNPs are relatively new, meaning they only occurred between the current generation and 1000 years ago, so we should not expect to find huge numbers of these newly developed mutations in the population. For example, if the SNP that defined haplogroup R1b1a2, M269, occurred 15,000 years ago in one man, his descendants have had 15,000 years to procreate and pass his M269 on down the line(s), something they have done very successfully since about half of Europe is either M269 or a subclade.
Each subclade has a SNP all its own. In fact, each subclade is defined by a specific SNP that forms its own branch of the human Y haplotree.
So far, so good.
But what does a SNP or an STR really look like, I mean, in the raw data? How do you know that you’re seeing one or the other?
Like Baseball – 4 Bases
The smallest units of DNA are made up of 4 base nucleotides, DNA words, that are represented by the following letters:
A = Adenine
C = Cytosine
G = Guanine
T = Thymine
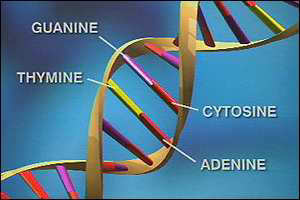
These nucleotides combine in pairs to form the ladder rungs of DNA, shown right that connect the helix backbones. T typically combines with A and C usually combines with G, reaching between the backbones of the double helix to connect with their companion protein in the center.
You don’t need to remember the words or even the letters, just remember that we are looking for pattern matches of segments of DNA.
Point Mutations
Your DNA when represented on paper looks like a string of beads where there are 4 kinds of beads, each representing one of the nucleotides above. One segment of your DNA might look like this:
![]()
If this is what the standard or reference sequence for your haplotype (your personal DNA results) or your family haplogroup (ancestral clan) looks like, then a mutation would be defined as any change, addition, or deletion. A change would be if the first A above were to change to T or G or C as in the example below:
![]()
A deletion would be noticed if the leading A were simply gone.
![]()
An addition of course would be if a new bead were inserted in the sequence at that location.
![]()
All of the above changes involve only one location. These are all known as Point Mutations, because they occur at one single point.
SNPs
A point mutation may or may not be a SNP. A SNP is defined by geneticists as a point mutation that is found in more than 1% of the population. This should tell you right away that when we say “we’ve discovered a new SNP,” we’re really mis-applying that term, because until we determine that the frequency which it is found in the population is over the 1% threshold, it really isn’t a SNP, but is still considered a point mutation or binary polymorphism.
Today, when SNPS, or point mutations are discovered, they are considered “private mutations” or “family mutations.” There has been consternation for some time about how to handle these types of situations. ISOGG has set forth their criteria on their website. They currently have the most comprehensive tree, but they certainly have their work cut out for them with the incoming tsunami of new SNPS that will be discovered utilizing these next generation tests, hundreds of which are currently in process.
STRs
A STR, or Short Tandem Repeat is analogous to a genetic stutter, or the copy machine getting stuck. In the same situation as above, utilizing the same base for comparison, we see a group of inserted nucleotides that are all duplicates of each other.
![]()
In this case, we have a short tandem repeat that is 4 segments in length meaning that CT is inserted 4 times. To translate, if this is marker DYS marker 390, you have a value of 5, meaning 5 repeats of CT.
So I’ve been fat and happy with this now for years, well over a decade.
The Monkey Wrench
And then I saw this:
“The L69/L159 polymorphism is essentially a SNP/STR oxymoron.”
To the best of my knowledge, this is impossible – one type of mutation excludes the other. I googled about this topic and found nothing, nor did I find additional discussion of L69, other than this.

My first reaction to this was “that’s impossible,” followed by “Bloody Hell,” and my next reaction was to find someone who knew.
I reached out to Dr. David Mittelman, geneticist and Chief Scientific Officer at Gene by Gene, parent company of Family Tree DNA. I asked him about the SNP/STR oxymoron and he said:
“This is impossible. There is no such thing as a SNP/STR.”
Whew! I must say, I’m relieved. I thought there for a minute there I had lost my mind.
I asked him what is really going on in this sequence, and he replied that, “This would be a complex variant — when multiple things are happening at once.”
Now, that I understand. I have children, and grandchildren – I fully understand multiple things happening at once. Let’s break this example apart and take a look at what is really happening.
HUGO is a reference standard, so let’s start there as our basis for comparison.
![]()
In the L69 variant we have the following sequence.
![]()
We see two distinct things happening in this sequence. First, we have the deletion of two Gs, and secondly, we have the insertion of one additional TG. According to Dr. Mittelman, both of these events are STRs, multiple insertions or deletions, and neither are point mutations or SNPs, so neither of these should really have SNP names, they should have STR type of names.
Let’s look at the L159 variant.
![]()
In this case, we have the GG insertion and then we have a TG deletion.
In both cases, L69 and L159, the actual length of the DNA sequence remains the same as the reference, but the contents are different. Both had 2 nucleotides removed and 2 added.
The good news is, as a consumer, that you don’t really need to know this, not at this level. The even better news is that with the new discoveries forthcoming, whether they be STRs or SNPs, at the leafy end of the branch, they are often now overlapping with SNPs becoming much more genealogically useful. In the past, if you were looking at a genetics mutation timeline, you had STRs that covered current to 1000 years, then nothing, then beginning at 5,000 or 10,000 years, you have SNPs that were haplogroup defining.
That gap has been steadily shrinking, and today, there often is no gap, the chasm is gone, and we’re discovering freshly hatched recently-occurring SNPs on a daily basis.
The day is fast approaching when you’ll want the full Y sequence, not to further define your haplogroup, but to further delineate your genealogy lines. You’ll have two tools to do that, SNPs and STRs both, not just one.
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research
Share this:

Discover more from DNAeXplained - Genetic Genealogy
Subscribe to get the latest posts sent to your email.
No, you and Dr. Mittelman do not understand. Please re-read Thomas Krahn’s original explaination, which you neglected to cite. L69 is a single point mutation where a G changes to a T. (Compare the second and third rows the source diagram above. It happens frequently BECAUSE of the poly-G and poly-GT repeats trip up the molecular copy machinery just as in STRs. The same deal applies to L159 (compare the first and second rows), where a T changes to a G. Because the net length of the two poly-g and poly-GT regions does not usualy vary, it’s very unlikely that two insertion/deletion events occur. A single point mutation (but definitely not a “UEP”) is the simplest explanation!
Hi Vince, I very clearly didn’t understand, which is why I asked Dr. Mittelman about this. I find it really difficult to believe that he doesn’t understand. Perhaps you could contact him and have a discussion with him. He’s very approachable.
I think Roberta wrote this post to help clarify and explain terminology used to describe sequence variation. It is a great service to everyone that she did this because if we can’t use standard terminology then everyone gets confused. Phrases like “SNP/STR oxymoron” and “mutate back like a regular STR” are not scientific and are not clear. So Roberta tried to clarify.
Now to address your comment. You are confident that Roberta’s description of this complex variant is wrong because “the net length of the two poly-g and poly-GT regions does not usually vary” and therefore ” it’s very unlikely that two insertion/deletion events occur”. I don’t see how you could draw that conclusion with certainty. In fact its not unusual for two STRs to be positioned back to back and mutate in such a way that there is often no net change. Look, for example, at the well-known case of RUNX2 which contains a back to back poly-alanine and poly-glutamine repeat.
To gain insight into how the sequence biologically mutates we could look at lots of people and then perhaps compare the human sequence to primate genomes to see if we can infer the true mode of mutation. From the information Roberta provides, however, I find it perfect reasonable that this could be case of two STRs mutating nearby each other. Homopolymers are highly mutagenic and mutate at frequencies far greater than point mutations. This is a technical point, however, that most readers probably don’t take interest in.
The bigger issue is that we should strive, as a community, for simpler and more clear explanations; as well as proper use of terms. This post is a great step in that direction.
So at this stage of our knowledge, wouldn’t it be safer to say that this is unlikely to be a point mutation rather than say that this is not a point mutation. And then, as you did, provide the explanation.
Thanks Vince, I found your explanation very helpful. I did a screen shot of the two strands and blew the image up and it became very clear that what you suggest makes absolute sense. Just one change has occurred the fifth G to a T which then looks like two Gs are missing. Very clever. And then, of course, it looks like an extra TG has been added. Just shows how tricky reading these strands can be. Thanks for the discussion Roberta
Wow, this sounds so much like language! Including the disagreement about how to analyze what’s going on. The issues you’re talking about with these mutations particularly remind me of reduplication. So cool!
I’m not an expert and admittedly neither is Roberta, but we have to admit she has a very good point. Doesn’t it boil down to a need for refined definitions? Sorry to disagree when I don’t fully understand but I side with Roberta and Dr. Mittelman on this until someone redefines SNPs and STRs. I especially like Roberta’s way of pointing out how recent discoveries have narrowed the former 5,000 year SNP gap. Recent discoveries have indeed begun to make SNPs more relevant to the genealogist. I long for the day when I can proudly say we’ve discovered the SNP that defines my surname. Hopefully we’ll discover those with similar yDNA matches who also determine our geographic origin. A clear understanding of well-defined SNPs and STRs is essential to our family DNA project’s goals. Confusion is our enemy, not our friend.
Another tremendously helpful blog post. Much appreciated!
I’m curious when you wrote, “A change would be if the first A above were to change to T or G or C”. My question is, would one of these changes be more likely than the other two? In other words, what is most common, A to G, A to T, or A to C?
My understanding is that:
– A (a purine) normally bonds with T (a pyrimidine).
– G (a purine) normally bonds with C (a pyrimidine).
With this in mind, is it more common for a point mutation to involve:
(1) – A change in the purine on the measured strand, from A to G, so that the pyrimidine on the complementary strand goes from T to C simultaneously?
(2) – A simple “flip” of the two complementary bases between the measured strand and complementary strand, so that the particular purine and pyrimidine simply switch places with each other; for example, a change from A to T on one strand and simultaneously from T to A on the other strand at that location?
(3) – A combination of (1) and (2), switching from A to C; so that we’re not only switching to the other base pair, but also switching from purine to pyrimidine on the measured strand and from pyrimidine to purine on the complementary strand?
I’m also endlessly confused about mixed base readings in Y-DNA results. I understand autosomal results are expected to have both same (AA, GG, TT, CC) and mixed (AG, AT, AC, CT, CG, GT) base readings because there are two chromosomes, one from each parent, whereas any particular Y-DNA reading should always be the same base, since a man only has one Y chromosome. What about when you see CG for a Y-DNA result, for example, instead of CC or GG? Is this simply the genochip’s inability to detect whether that position on the measured Y chromosome strand is a C or a G? Could this happen if there is an unexpected A or a T at this position that the chip’s probe was not designed to handle? Is this the same as a “no-call” or is that something entirely different? Why are Y-DNA results reported in paired format in the first place, when there’s only one Y chromosome?
Thank you!
Pingback: How to find what Y SNPs are tested at 23andme | Kitty Cooper's Blog
Pingback: Big Y Release | DNAeXplained – Genetic Genealogy
Pingback: Haplogroup Comparisons Between Family Tree DNA and 23andMe | DNAeXplained – Genetic Genealogy
Pingback: Big Y Chrome Extension | DNAeXplained – Genetic Genealogy
Pingback: 2014 Y Tree Released by Family Tree DNA | DNAeXplained – Genetic Genealogy
I have been scouring the internet trying to find a simple yes or no answer to the simple question: Is there a way to compare the SNP data from 23 and me’s male DNA download to Family Tree DNA’s STR markers and values. Family Tree DNA says that one can clikc on a button and see the SNPs for their Y-dna data, but when I do so, I see a list of SNPs that has no resemblance to the SNP data downloaded from the 23 and me site. It seems like we have an apples and oranges way of looking at male DNA and there is no way to compare the two. Is that right?
First of all, you can’t compare SNPs and STRs. They are two different things. Second, 23andMe and Family Tree DNA utilize different versions of the Y tree. ISOGG uses yet a third version. So, in essence, the answer is that you really can’t utilizing haplogroup names, like R1b1a2, for example. If you utilize the actual SNP tested, like M269, that will be the same between vendors.
I thought I understood the first three sentences – they sounded like a “no you cant'”. Bu then you said, “If you utilize the actual SNP tested like M 269, that will be the same between vendors.” So now I’m confused. So let me ask the question in another way. 23 and Me reports: rsid position and genotype for example: For George Hargrave:
rs11575897 Y 2649494 T
rs2534636 Y 2657176 G
i3000043 Y 2658271 C
rs13303755 23612197 G->T
There is a table at:
http://isogg.org/tree/ISOGG_YDNA_SNP_Index.html
that identified rs11675897 as M176 and rs2534636 as R1a1
and rs35284970 as M130
and rs3895 as M4
and rs13447361 as M324
and rs13303755 as L48
In Family Tree DNA,
Warren Hargrave, is identified as R-L48
and
Glen Hargrave as M172
in the isogg table
M172 rs2032604 14969634 T->G
L48 rs13303755 23612197 G->T
George Hargrave has the L48 rs# in his huge table downloaded from 23 and me.
but does not have the M172 rs# in his huge table.
Warren Hargrave is identified as R-L48, but Glen Hargrave is identified as M172.
In Warren’s snp chart above R-L48, there is Z381
IN the ISOGG table there is
Z381 R1b1a2a1a1c S263 rs34001725 7246726 C->T
IN George Hargrave’s huge table there is:
no entry for rs34001725
In Warrne’s snp chart above Z381, there is U106 which in the Isogg table is rs16981293 which does not appear in George’s huge table from 23 and me.
IN warren’s snp chart L48 branches to
Z28 (no rs values in Isogg table, but identified as R1b1a2a1a1c2b2)
L47 (rs34283263) and ( RS 34283263 does not appear in George’s huge table.)
L200 (no rs values in Isogg table, but identified as R1b1a2a1a1c2b3 ).
RS 34283263 does not appear in George’s huge table.
I don’t know what any of this means.
But does any of this help me conclude that George and Warren are kin, but Glen is not.
Richard
Hi Richard. The problem is that men who aren’t related in thousands of years share haplogroups. So the real answer to what you are asking is that no, even if you could easily compare haplogroups, they won’t tell you if your Hargraves men are related in a genealogically relevant timeframe. You need to test them at Family Tree DNA for STR markers to do that. Now, if they are entirely in different base haplogroups, like R and G, for example, then the STR markers aren’t going to match either. But you don’t need to download the raw data to tell that – you can just look at the haplogroup listed at 23andMe. Let me say this another way – even if they do match at the lowest level haplogroup, and even if you were able to figure it out – it would NOT mean they are from the same line genealogically. That’s what STR markers are for.
OK , now we’re getting somewhere. Warren Hargrave is identified as J-M172 and Glen Hargrave is identified as R-L48. Now George Hargrave is identified on 23 and Me as J2A1. Can I now conclude that George and Glen are not related and that Warren and George are related, but we can’t tell if they are related recent history.
Yep, you’ve got it, assuming J2a1 is his Y DNA haplogroup and not his mtDNA:)
Roberta;
Reading the of the beginning;
“This was a pretty good explanation for a long time but as sequencing technology has improved and new tests have become available, such as the Full Y and Big Y tests, new mutations are being very rapidly discovered which blurs the line between the timeframes that had been used to separate these types of tests. In fact, now they are overlapping in time, so SNPs are, in some cases becoming genealogically useful. This also means that these newly discovered family SNPs are relatively new, meaning they only occurred between the current generation and 1000 years ago, so we should not expect to find huge numbers of these newly developed mutations in the population. For example, if the SNP that defined haplogroup R1b1a2, M269, occurred 15,000 years ago in one man, his descendants have had 15,000 years to procreate and pass his M269 on down the line(s), something they have done very successfully since about half of Europe is either M269 or a subclade.”
My DNA in R1b1a2a1a2c – [R-L21], M269, my test was Western Europe, accounted to the Viking & Invader YDNA project, they found I was a Viking from Ireland [Dublin], from there we came here in 1600, to Canada / North America.
So?
Pingback: Big Y Matching | DNAeXplained – Genetic Genealogy
Pingback: Haplogroup Projects | DNAeXplained – Genetic Genealogy
Using Autosomal DNA why can’t we convert 23andme RAW data to the 13 base CODIS locis?? Since 23andme is the RAW data of our DNA right?
CODIS markers are autosomal STRs, which are untestable using the SNP bead probes used by 23andMe. They would need to be tested by Sanger sequencing using PCR primers targeted specifically to those regions, or possibly “NextGen” whole genome sequencing.
http://www.cstl.nist.gov/strbase/fbicore.htm
Pingback: Finding Your American Indian Tribe Using DNA | DNAeXplained – Genetic Genealogy
Pingback: Finding Your American Indian Tribe Using DNA | Native Heritage Project
Pingback: DNAeXplain Archives – Introductory DNA | DNAeXplained – Genetic Genealogy
Pingback: Concepts – Y DNA Matching and Connecting with your Paternal Ancestor | DNAeXplained – Genetic Genealogy
Pingback: New Family Tree DNA Holiday Coupons – And Why the Big Y | DNAeXplained – Genetic Genealogy
Pingback: Concepts – The Faces of Endogamy | DNAeXplained – Genetic Genealogy
Pingback: Which DNA Test is Best? | DNAeXplained – Genetic Genealogy
Pingback: Working with Y DNA – Your Dad’s Story | DNAeXplained – Genetic Genealogy
Pingback: James Lee Claxton/Clarkson (c1775-1815), Died at Fort Decatur, Alabama, 52 Ancestors #166 | DNAeXplained – Genetic Genealogy
Pingback: Durham DNA – 10 Things I Learned Despite No Y DNA Matches, 52 Ancestors #167 | DNAeXplained – Genetic Genealogy
So, an FTDNA – Big Y (Male Version) and mtFullSequence (Men and Women) tested an SNP’s mutation?
I never heared an STR’s Testing version for a Mitochondrial DNA.
Pingback: Big Changes for Big Y Test at Family Tree DNA | DNAeXplained – Genetic Genealogy
Hello,
I am new to the subject of genealogy. I am interested in conducting a test for my family including my son, wife and myself for matching, health and ancestry. I just wanted to know the difference between SNPs and STRs in terms of testing and I am very confused now, more that I was. The article mentions that SNPs are not useful for genealogy but STRs are! So, that being said, why do testing companies test atDNA by examining SNPs? Why not STRs to be more precise, accurate and useful? Maybe this is a silly question but I really would like to receive an answer to this before I proceed with an FTDNA purchase.
That’s a good question. This article was focused on Y DNA. Even in Y, SNPs are used as many more have since been discovered, but generally in Y DNA SNPs reach further back in time.
How many Short tandem repeats does an individual human have? How many STR do we all share?
As the Y chromosome continues to be investigated, more continue to be discovered.
Pingback: Whole Genome Sequencing – Is It Ready for Prime Time? | DNAeXplained – Genetic Genealogy
Pingback: Big Y-500 STR Matching | DNAeXplained – Genetic Genealogy
what if you get heterogeneous call on snp mutation does this mean one parent passed mutation and other didnt
my question is
does haplogroup B has the same snps as haplogroup A plus more snps specific to B haplogroup and how these snps will be used for migration map
Pingback: Y DNA: Step-by-Step Big Y Analysis | DNAeXplained – Genetic Genealogy
Pingback: Y DNA Resources and Repository | DNAeXplained – Genetic Genealogy