
The original goal of Blaine Bettinger’s Shared cM Project was to document the actual shared ranges of centiMorgans found in various relationships between testers in genetic genealogy. Previously, all we had were academically calculated models which didn’t accurately really reflect the data that genetic genealogists were seeing.
In June 2016, Blaine published the first version of the Shared cM Project information gathered collaboratively through crowd-sourcing. He continued to gather data, and has published a new 2017 version recently, along with an accompanying pdf download that explains the details. Today, more than 25,000 known relationships have been submitted by testers, along with their amount of shared DNA.
Blaine continues to accept submissions at this link, so please participate by submitting your data.
In the 2017 version, some of the numbers, especially the maximums in the more distant relationship categories changed rather dramatically. Some maximums actually doubled, meaning having more data to work with was a really good thing.
The 2017 project update refines the numbers with more accuracy, but also adds more uncertainly for people looking for nice, neat, tight relationship ranges. This project and resulting informational chart is a great tool, but you can’t now and never will be able to identify relationships with complete certainly without additional genealogical information to go along with the DNA results.
That’s the reason there is a column titled “Degree of Relationship.” Various different relationships between people can be expected to share about the same amount of DNA, so determining that relationship has to be done through a combination of DNA and other information.
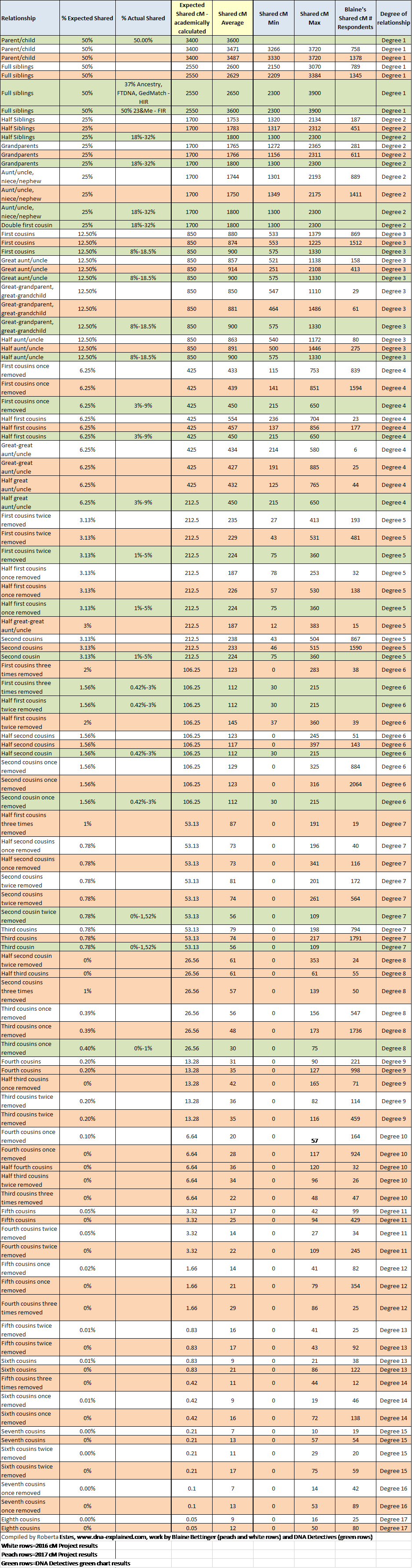
When the 2016 version was released, I completed a chart that showed the expected percentage of shared DNA in various relationship categories and contrasted the expected cM of DNA against what Blaine had provided. I published the chart as part of an article titled, Concepts – Relationship Predictions. This article is still a great resource and very valid, but the chart is now out of date with the new 2017 information.
What a great reason to create a new chart to update the old one.
Thanks to Blaine and all the genetic genealogists who contributed to this important crowd-sourced citizen science project!
2016 Compared to 2017
The first thing I wanted to know was how the numbers changed from the 2016 version of the project to 2017. I combined the two years’ worth of data into one file and color coded the results. Please note that you can click on any image to enlarge.

The legend is as follows:
- White rows = 2016 data
- Peach rows = 2017 data for the same categories as 2016
- Blue rows = new categories in 2017
- Red cells = information that changed surprisingly, discussed below
- Yellow cells = the most changed category since 2016
I was very pleased to see that Blaine was able to add data for several new relationship categories this year – meaning that there wasn’t enough information available in 2016. Those are easy to spot in the chart above, as they are blue.
Unexpected Minimum and Maximum Changes
As I looked at these results, I realized that some of the minimums increased. At first glance, this doesn’t make sense, because a minimum can get lower as the range expands, but a minimum can’t increase with the same data being used.
Had Blaine eliminated some of the data?
I thought I understood that the 2017 project simply added to the 2016 data, but if the same minimum data was included in both 2016 and 2017, why was the minimum larger in 2017? This occurred in 6 different categories.
By the same token, and applying the same logic, there are 5 categories where the maximum got smaller. That, logically, can’t happen either using the same data. The maximum could increase, but not decrease.
I know that Blaine worked with a statistician in 2016 and used a statistical algorithm to attempt to eliminate the outliers in order to, hopefully, eliminate errors in data entry, misunderstandings about the proper terms for relationships and relationships that were misunderstood either through genealogy or perhaps an unknown genetic link. Of course, issues like endogamy will affect these calculations too.
A couple good examples would be half siblings who thought they were full siblings, or half first cousins instead of just first cousins. The terminology “once removed” confuses people too.
You can read about the proper terminology for relationships between people in the article, Quick Tip – Calculating Cousin Relationships Easily.
In other words, Blaine had to take all of these qualifiers that relate to data quality into consideration.
Blaine’s Explanation
I asked Blaine about the unusual changes. He has given me permission to quote his response, below:
The maximum and minimum aren’t the largest and smallest numbers people have submitted, they’re the submissions statistically identified by the entire dataset as being either the 95th percentile maximum and minimum, or the 99th percentile maximum and minimum. As a result, the max or min can move in either direction. Think of it in terms of the histograms; if the peak of the histogram moves to the right or left due to a lot more data, then the shoulders (5 & 95% or the 1 and 99%) of the histogram will move as well, either to the right or left.
So, for example, substantially more data for 1C2R revealed that the previously minimum was too low, and has corrected it. There are still 1C2R submissions down there below the minimum of 43, and there are submissions above the maximum of 531, but the entire dataset for 1C2R has statistically identified those submissions as being outliers
The histogram for 1C2R supports that as well, showing that there are submissions above 531, but they are clearly outliers:

People submit “bad” numbers for relationships, either due to data entry errors, incorrect genealogies, unknown pedigree collapse, or other reasons. Unless I did this statistical analysis, the project would be useless because every relationship would have an exorbitant range. The 95th and 99th percentiles help keep the ranges in check by identifying the reasonable upper and lower boundaries.
Adding Additional Information
The reason I created this chart was not initially to share, but because I use the information all the time and wanted it in one easily accessible location.
I appreciate the work that Blaine has done to eliminate outliers, but in some cases, those outliers, although in the statistical 1%, will be accurate. In other cases, they clearly won’t, or they will be accurate but not relevant due to endogamy and pedigree collapse. How do you know? You don’t.
In the pdf that Blaine provides, he does us the additional service by breaking the results down by testing vendors: 23andMe, Ancestry and Family Tree DNA, and comparison service, GedMatch. He also provides endogamous and non-endogamous results, when known.
The vendor where an individual tests does have an impact on both the testing, the matching and the reporting. For example, Family Tree DNA includes all matches to the 1cM level in total cM, Ancestry strips out DNA they think is “too matchy” with their Timber algorithm, so their total cM will be much smaller than Family Tree DNA, and 23andMe is the only one of the vendors to report fully identical regions by adding that number into the total shared cM a second time. This isn’t a matter of right or wrong, but a matter of different approaches.
Blaine’s vendor specific charts go a long way in accounting for those differences in the Parent/Child and Sibling charts shown below.

A Combined Chart
In order to give myself the best change of actually correctly locating not just the best fit for a relationship as predicted by total matching cM, but all possible fits, I decided to add a third data source into the chart.
The DNA Detectives Facebook Group that specializes in adoption searches has compiled their own chart based on their experiences in reconstructing families through testing. This chart is often referred to simply as “the green chart” and therefore, I have added that information as well, rows colored green (of course), and combined it into the chart.
I modified the headings for this combined chart, slightly, and added a column for actual shared percent since the DNA Detectives chart provides that information.
I have also changed the coloring on the blue rows, which were new in 2017, to be the same as the rest of Blaine’s 2017 peach colored rows.
I hope you find this combined chart as useful as I do. Feel free to share, but please include the link to this article and credit appropriately, for my work compiling the chart as well as Blaine’s work on the 2016 and 2017 cM Projects and DNA Detective’s work producing their “green chart.”
______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research
Share this:

Discover more from DNAeXplained - Genetic Genealogy
Subscribe to get the latest posts sent to your email.
Thank you so much for investing your time into making this chart! I appreciate having all the relevant info at my fingertips like this.
Wow, love this combined chart! Thanks for all the hard work. Would love to print it out but despite numerous methods tried, I can only get the first page of the chart to print. Any ideas?
Save it as an image to your system and then print.
Thanks for the reply. Unfortunately, that doesn’t work either, still only prints the first page. As a last resort, I can print the article and use an actual cut and paste with paper. If you have any other thoughts, I would be happy to try before resorting to paper! 🙂
I experimented a bit here and the biggest problem is the width of the chart. I created a pdf but it’s still too wide for one page when printing. I guess you can tell I don’t print much anymore.
Turn the graphic into a pdf file. That worked for someone else.
Great chart, thanks for pulling it together. Hope the folks that do the Relationship Estimator tool will update it with this data too.
Hi, I might be willing to do this I just had Living DNA done, I went to the Blaine submission page and I have no idea what he is asking for with the 1st 3 boxes. Went & opened the PDF and well for me just more random #’s that make no sense to a layman. Should I just send this guy my email add. and password and let him look at what he could use? It seems as I’ve been looking around at other sites there are a lot of others that are like what does any of this mean and what am I suppose to do with this stuff, it’s getting really confusing, most of even your stuff is going over my head.
PS. On another note so I ordered L.-DNA’s book also, total rip-off, nothing but a high glossy reprint of the terrible lame website with high school text on anthropological BS, I could have C&P the 6 relevant pages from the site for not even 50 cents, but to their credit I told them what I thought of their book and they did refund the $69 bucks. So my mom is English/Irish, dad Italian and they told me I’m 97% European woopdie freak’en doo like I didn’t know that already who cares anyway, they touted the part about your African line which is really all I was interested and they failed that info with lame generalities. I went to 1 site and they had a list of something like 40 companies, who knows if these people are legit or not or just plain rip-offs and tell you whatever, maybe the government has to step in with some regulations and oversight. I’m starting to see how a ordinary person can be taken advantage of with this.
Well anyway sorry, I’m just disappointed with these people, I did the Nat. Geo. one back in 05 and just should have stuck with that, but thinking that the tech must have gotten much better since then i would find out more but no, …………….Marc
Living DNA doesn’t show you matches, so you can’t enter anything from Living DNA in Blaine’s project. You need matches to other known relatives to do that. I suggest you might want to read the article on Which DNA Test is Best…it’s always better to stay with known quantities. This articles shows you what you get with each major vendor and provides important information about each one. If the vendor isn’t on the list, I’d stay away. https://dna-explained.com/which-dna-test-is-best/
Awesome charts! Thanks for the hard work. It shows just how far autosomal analysis has come in the last five years.
It sure has!!!
I don’t know if I should be insulted or not! One of those “outlier” points that was not used is one of mine. The minimum amount for amount shared between first cousins is between me and my first cousin. And he is definitely my first cousin! I have my dad and two of his siblings tested (the first cousin in question is the son of my deceased uncle, so not able to test.) The three siblings are all in the range of aunt/uncle from the chart, though my dad’s is on the lower end. And then I got about 1/3 of what the common DNA that my dad has with my cousin. So me and my 1C share only 533 cM. (According to 23andMe where we both tested.) My sister and the same 1C share a little more at 727 cM.
I want to be counted!
I would suggest contacting Blaine.
Love this update. I refer to the Bettinger data often and it’s good to see it updated. I appreciate your work in compiling a readable chart, too – will reference both sources in any sharing. This is great information. Thank you.
What would it mean if in the third to fourth cousin range if: I had one match of a 30 cM segment all on one chromosome, versus another match of 3 segments of about 10 cM each on three different chromosomes? (Assuming both matches ignored any matches less than 5 cM in length and both matches used the same testing company).
Also, what does it mean by saying Ancestry’s Timber algorithm strips out DNA that are “too matchy”? I have noticed Ancestry usually has the lowest total number reported for matching DNA cM on any given match. (Includes Ancestry, FTDNA, 23 & Me, and GedMatch test results)
We don’t yet the likelihood of one segment being more recent that smaller segments being more distant. That research just hasn’t been done yet. I wrote about Ancestry removing segments in this article, with examples that make it easier to understand: https://dna-explained.com/2014/11/19/ancestrys-better-mousetrap-dna-circles/
Thank you so very much for all the information, you have been given.
Sent from Mail for Windows 10
how does blake factor in pedigree collapse? that might explain why his third cousin row doesn’t have 425 cm as a max
Endogamy is part of the charts in the PDF file.
Another fantastic explanation (with visuals!) for us mortals to cogitate upon–the last chart worth it’s weight in gold. Absolute love of your calling is evident…thank you is not enough!
Thank you for the kind and encouraging words.
Roberta,
Thanks to you and Blaine for your wonderful charts and your wonderful brains. So glad you two chose to do the work you do.
Thank you. We both love what we do.
(1) A number of the rows have zero as the value for the expected % shared. I believe that they are not correct.
(2) Based on the the explanation, is it better to call the min and max as 5 percentile and 95 percentile? Since the data are self-reported, there is no way to determine their accuracy. Removal of outliers to determine min and max is at best a difficult task especially the amount of data is not high. Simply call it 5 and 95 percentile or unadjusted self reported data is probably better.
(3) FIR and HIR only affect sibling and endogamous situations. Many companies did not implement calculation to do FIR which seems to me inappropriate.
(4) Some companies include X chromosome in the calculation of matched segment length which makes comparisons difficult. X chromosome can change the value. On the other hand, match segment in X chromosome is as good as any other chromosome in telling us that two person are relative.
Even with these reservations, I do thank you for publishing something that are valuable for all of us that are interested in genetic genealogy!
The zero is accurate because many people in those ranges do not match, at all.
I know that many of my matches are in the outlier range. However, I know it was very important for Blaine to make sure the project utilized accepted scientific methodology. Likewise, I know why companies don’t show me some matches which are found to be too small by their algorithms, or “special sauce,” to be significant. I do wish I could see more smaller matches (and also more shared matches) from the companies. I’m noticing I’m not seeing descendants of a “mystery ancestor” who aren’t also descendants of other ancestors! Obviously, there’s endogamy going on. But on occasion, one of these “mystery” matches breaks through for me: I will happily use this magical chart for figuring out possible degrees of relationship: thank you again!
Pingback: First Cousin Match Simulations | DNAeXplained – Genetic Genealogy
Thank you for this blog 🙂 It’s made me want to contribute to the Shared cM Project … but the “endogamy” question in the submission form has floored me. It asks if there are any known cousin marriages “that could impact the amount of shared DNA”. Is there any guide to how many cousin marriages add up to endogamy and how far back in time these marriages need to have occurred? My half-second-cousin and I share 3xgtgrandparents who were second-cousins-once-removed, and our 4xgtgrandparents were first cousins. I’m not sure whether inter-marriages that far back count as endogamy, especially as our shared cMs are almost exactly at the ISOGG average for our relationship! I’m hoping you can point me towards something that will help un-confuse me ….
I have forwarded your question to Blaine.
Much appreciated – thank you! 🙂
Hi Fern! Unfortunately there is no guide. We don’t really have a good handle on what level of endogamy or pedigree collapse could impact genetic relationships; although the Shared cM Project might be the closest thing to a guide.
In the cases you listed, I wouldn’t expect those to have a huge impact on your current genetic relationships. They’re both far back in time, and the relationships weren’t very close. If you ever have a question, you can always enter this kind of information in the notes field when making submissions to the project. Thank you so much!
Thanks, Blaine 🙂 Hopefully this will also help others who have a similar question about cousin marriages … I’m sure I’m not the only one! So thanks again, to both you and Roberta 🙂
Pingback: MyHeritage’s New Theory of Family Relativity | DNAeXplained – Genetic Genealogy
Pingback: Full or Half Siblings? | DNAeXplained – Genetic Genealogy
Pingback: Identifying Unknown Parents and Individuals Using DNA Matching | DNAeXplained – Genetic Genealogy
Pingback: Caution: Invisible Fathers and Autosomal Matching – Who’s Hiding in Your DNA? | DNAeXplained – Genetic Genealogy
Pingback: Shared cM Project 2020 Analysis, Comparison & Handy Reference Charts | DNAeXplained – Genetic Genealogy