In late 2013, a new Y DNA product called the Big Y was introduced by Family Tree DNA. The goal of this new test was to read virtually all of the Y chromosome that was useful for genealogical purposes.
I decided to wait and see how useful this tool actually was, and how to effectively use the information before delving into a family study, in part, because the individuals tests are quite expensive. We began our Estes Big Y family study in 2014 and I have now completed a report for family members. With their permission, I’m sharing this information with the hope that other groups will see the potential in combining STR and full sequence SNP testing for family groups.
The temptation, of course, especially in the case of the Estes lineage is to see if we could reach back further in time to see if we can connect with, confirm or dispel the persistent myth that the Estes line is descended from the d’Este family line of Italy. Of course, if there was a direct line male from that family that existed, or was willing to test, that would answer the question in a heartbeat but that’s not the case.
The belief that the Estes family was descended from the d’Este’s is an old one and not just limited to the American Estes family or the Estes family itself.
Long-time Estes researcher and archivist, David Powell, gathered several instances where various families in England used the d’Este name, at least one of which was suggested by King James himself.
King James I of England and Scotland (reigned from 1603 to 1625) was convinced that a gentleman in his service by the name of East was in fact a descendent of the d’Este family and suggested he change his name to Este. One did not gainsay a suggestion from the king in those days!
Even earlier, the English printer Thomas East (1540-1608) used the names East, Est, Este and Easte and hinted at a connection with the d’Este family, although his motivations were much more obvious – he made his fame publishing Italian music in England and suggesting a connection to the d’Este’s would certainly not have adversely affected his sales! Thomas’ son, Michael (1580-1680), who was a composer in his own right, also used the names East, Est, Este and Easte.
Somewhat more recent was the case of Sir Augustus d’Este (1794-1848), who despite the surname, was pure English. Augustus was son of the Duke of Sussex and the daughter of the Earl of Dunmore. The marriage of his parents was without the King’s consent and he (George III) subsequently annulled the marriage, thus making Augustus illegitimate *after* his birth. After the annulment, Augustus and his sister were given the name d’Este by their father, a name that was “anciently belonging to the House of Brunswick”. There were several other instances where English aristocrats named Este or East changed their name to d’Este, including one family in the 1800’s that changed their name from East and claimed the non-existent title “Baron d’Este.”
The Big Y test holds out the promise, or at least the possibility, of being able to connect the outside limits of the standard genealogy Y DNA STR tests and bridge the hundreds to a couple thousand year gap between STR testing and haplogroup definitions.
In our case, we needed to know where our ancestors were and what they were doing, genetically, between about 500BC and 1495AD when we both find them (coming forward in time) and lose them (going backward in time) in Deal, Kent, England.
Had they been in Kent forever, without a surname or with a surname, but not reflected in the available records, or had they truly been royalty on the continent and recently immigrated?
In the article, Nycholas Ewstas (c1495-1533) English Progenitor, I found and compiled the various list of Estes/d’Este ancestral stories. The most reasonable seems to be found in David Powell’s article, “Origins of the Estes/Eastes Family Name,” as follows:
“…Francesco of Este, who was the son of Marquis Leonello [1407-1450], left Ferrara [1471] to go and live in Burgundy, by the will of Duke Ercole [Francesco’s uncle, who succeeded Leonello] .. and, in order that he should go at once, he gave him horses and clothes and 500 ducats more; and this was done because His Excellency had some suspicions of him .. ‘Francesco .. went to Burgundy and afterward to England’. These were the words written on the back of the picture of Francesco found in a collection of paintings near Ferrara.”
Many of the details are similar to earlier stories. But why would Francesco flee Italy? In 1471 Francesco’s brother, Ericolo, led a revolt in an attempt to overthrow Duke Ercole. The attempt was unsuccessful and in typical royal tradition, Ericolo lost his head and Francesco exiled, if only because he was Ericolo’s brother. Did Francesco really travel to England? The only evidence for this is the writing in the back of the painting, the existence of which is unconfirmed. Essentially the same story is told by Charles Estes in his book:
“.. Francesco Esteuse (born c.1440), the illegitimate son of Leonnello d’Este. Francesco was living in Burgundy. In the time of Duke Borso he came to Ferrara, and at Borso’s death was declared rebellious by Ercole because of efforts made by his brother, Ericolo, to seize power. Francesco returned to Burgundy and was heard of no more from that time (1471). As the time coincided with that when Edward conquered [sic] England with the aid of Burgundy, it was possible that Francesco followed Edward and after Edward’s victory made England his home.”
I checked with the Metropolitan Museum of Art who indicated no such notation on the painting and provided additional information showing that it’s likely that Francesco died in Burgundy.
If Francesco was the progenitor of the Estes family of Kent, who were mariners, the family in one generation, in essence, in one fell swoop, went from royalty to peasantry in Kent. Nicholas was born in 1495 and two other Estes men, Richard and Thomas, found nearby, born about the same time. Extremely unlikely, but not impossible.
The d’Este family of Italy was said by Edward Gibbon in his “Decline and Fall of the Roman Empire” to originate from the Roman Attii family, which migrated from Rome to Este to defend Italy against Goths. However there is no evidence to support this hypothesis.
The names of the early members of the family indicate that a Frankish origin is much more likely. The first known member of the house was Margrave Adalbert of Mainz, known only as father of Oberto I, Count palatine of Italy, who died around 975. Oberto’s grandson Albert Azzo II, Margrave of Milan (996–1097) built a castle at Este, near Padua, below, and named himself after it.

The city of Mainz is the capital of the state of Rhineland-Palatinate in Germany. It was the capital of the Electorate of Mainz at the time of the Holy Roman Empire which began in 962. In antiquity Mainz was a Roman fort city which commanded the west bank of the Rhine and formed part of the northernmost frontier of the Roman Empire; it was founded as a military post by the Romans in the late 1st century BC and became the provincial capital of Germania Superior.

The city is located on the river Rhine at its confluence with the Main opposite Wiesbaden, in the western part of the Frankfurt Rhine-Main. The painting above shows Mainz looking toward the Rhine, across the old part of the city, in 1890.
There is absolutely no question that the Romans occupied Mainz as the remnants of architectural structures such as Roman City gates from the 4th century and Roman aqueducts (below) permeate the landscape yet today.

The town of Frankfurt was adjacent Mainz and the name of Frankfurt on Main is derived from the Franconofurd of the Germanic tribe of the Franks plus Furt, meaning ford, where the river was shallow enough to be crossed by wading. The Alemanni and Franks lived there and by 794 Charlemagne presided over an imperial assembly and church synod, at which Franconofurd (-furt -vurd) was first mentioned.
The Franks and the Alemanni were both Germanic tribes. The Alemanni were found in what is today German Swabis and Baden, French Alsace, German-speaking Switzerland and Austrian Voralberg. Their name means “all men” as they were a Germanic confederation tribe. One historian, Walafrid Strabo, a monk of the Abbey of St Gall wrote in the 9th century that only foreigners called the Alemanni by that name, that they called themselves the Suebi.
This map shows the approximate location of the original Frankish tribes in the third century.

“Carte des peuples francs (IIIe siècle)” by Odejea – Own work, d’après : Patrick Peron, Laurence Charlotte Feiffer, Les Francs (tome 1 – A la conquête de la Gaule), Armand Collon Editeur, Paris, 1987, isbn 2-200-37070-6. Licensed under CC BY-SA 3.0 via Wikimedia Commons
The Franks, who eventually conquered the Alemanni, were found predominately in northeastern Europe in what is now Belgium and the Netherlands along the lower and middle Rhine, extending into what is now France.
Another source claims that the Italian d’Este family roots were found as the Marquis of Sicily, affiliated with Lombardy, which was ruled by the Lombards. If this is true, the Lombards were also descendants of the Suebi, having originated in Scandinavia, and the Franks defeated the Lombards as well, so either way, the DNA would appear in the same locale.

“Lombard Migration” by Castagna – Own elaboration from Image: Europe satellite orthographic.jpg. Licensed under Public Domain via Wikimedia Commons –
Relative to the Estes family of Kent, if they do descend from the d’Este family of Italy, based on this information, their Y DNA should look like and correlate with that of either Italians or Germanic tribes such as the Franks and the Suebi.
Aside from answering this origins question that has burned for years, what other types of information might we learn from Big Y testing?
- Does the Estes family have any mutations that are unique? In other words, specific SNP mutations have evolved in the Estes family and would, in combination with other SNPs and STRs, identify us uniquely. Someday, in hundreds of years, as we have many descendants, these individual SNPs found only in our family line will define our own haplogroup.
- What other families are the closest to the Estes family?
- When and where did we “split” with those other families? Does their family history help define or identify ours?
- Can SNP mutations in combination with STR mutations help identify specific lineages within the Estes family? This is particularly important for people who don’t know which ancestral line they descend from.
These same questions would be relevant for any family interested in doing a Big Y DNA study.
The Estes family is fortunate that we have several people who are interested in the deep history of the family, and were willing to pay for the Big Y test, along with the full 111 marker Y STR tests to facilitate our research and understanding.
The Estes family is first found in Kent, England in 1495 with Nicholas whose name was spelled variably, as were all names at that time. Estes is spelled in many ways such as Ewstas, Eustace, Estes, Eastes, Estice and more. I am using Estes for consistency.
I have created a pedigree chart of sorts to show the descent of the Estes Big Y testers.

Robert Estes and Anne Woodward had two sons, Silvester and Robert, who have descendants Big Y testing today.
Silvester had two sons, Richard and Abraham who have descendants who have Y DNA tested, but only Abraham’s descendants have taken the Big Y test. Robert had son Matthew whose descendant also took the Big Y test. Note that Abraham and Matthew are shown in green which indicates that they immigrated to America. Richard, in blue, between Abraham and Matthew did not immigrate and his descendants did not take the Big Y test.
Of Abraham’s sons, we have Y DNA tested descendants from 7 sons, but only descendants of 5 sons are participating in the Big Y project. We are uncertain of the direct lineage of kit 199378 as noted by the ? with Elisha’s name in his ancestry. We know positively from his DNA results that he is biologically an Estes, but he could be descended from a different son.
We are also very fortunate that we have been able through several volunteers and professional genealogists to document the Estes line reliably both back in time into Kent and forward in time to current through several lines.
The Estes DNA project is somewhat unique in the fact that we have 10, 11 and 12 generations to work with in each line. Our closest participants are 7th cousins and our furthest, 10th cousins once removed. We have a total of 65 separate DNA transmission events that have occurred, counting each birth in each line as one transmission event, introducing the possibility of either STR mutations or new SNPS in each new generation.
STR mutations show up in the traditional 12, 25, 37, 67 and 111 marker panels. SNP mutations show up in the Big Y report as either SNPs or Novel Variants which is a newly discovered SNP that has not yet been assigned an official SNP name, assuming is isn’t just a family occurrence.
Let’s look at the STR markers first.
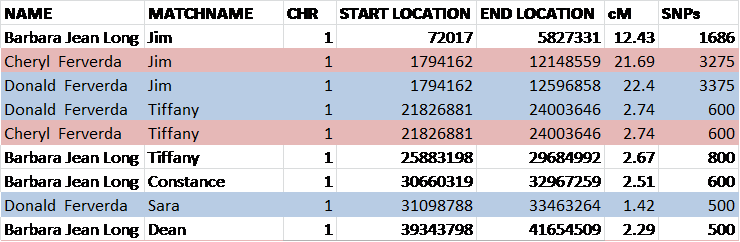
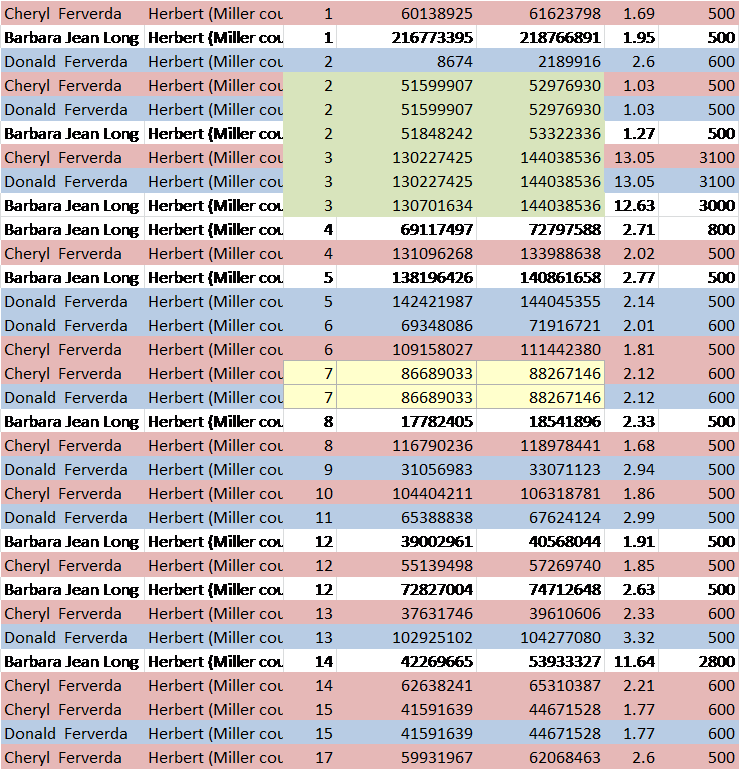
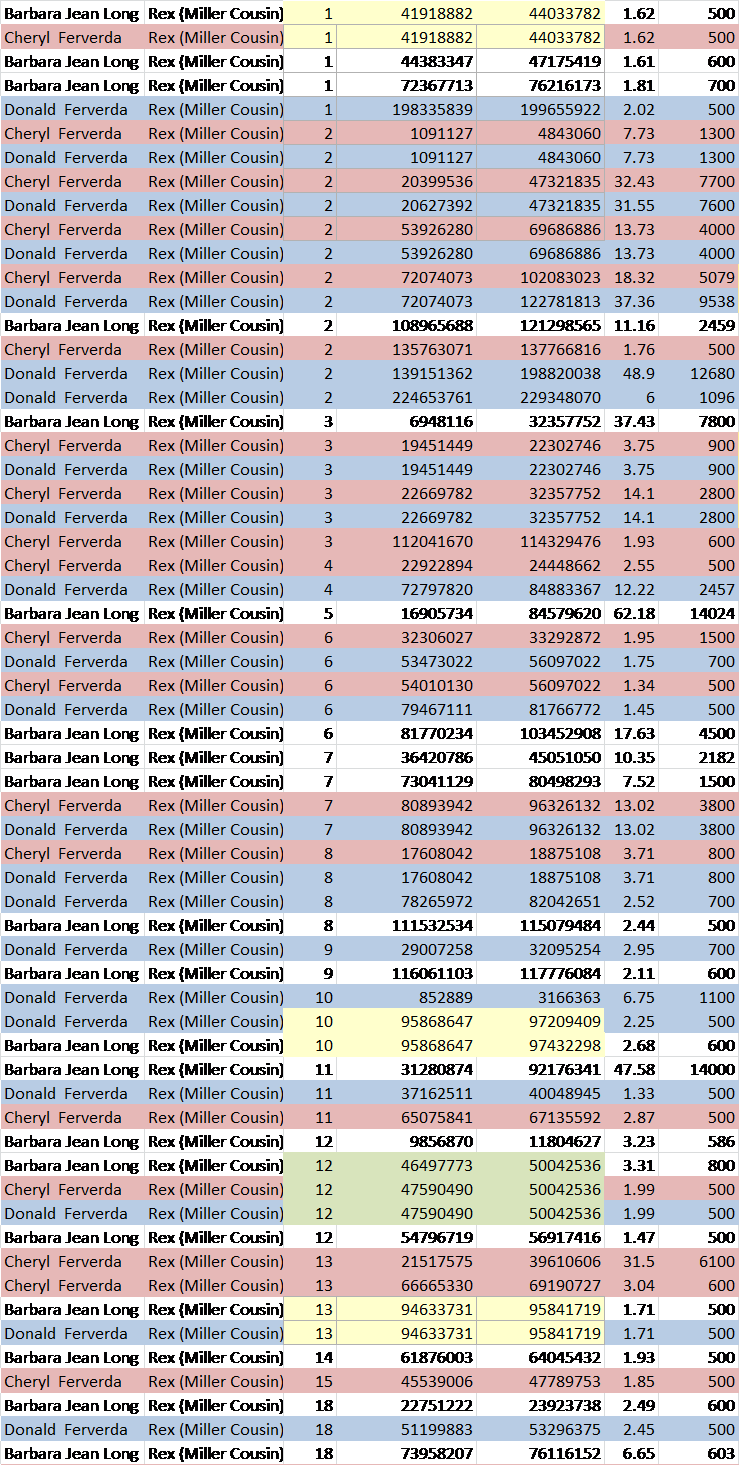
All of our participants except one extended to 111 markers and that individual tested at 67. Of the 111 markers, 97 marker locations have identical marker values in all participants, so have no mutations in any line since our common ancestor lived. Of course, this means that our common ancestor carried this same value at this DNA location.
I created a virtual Estes ancestor, in green, below, by utilizing the most common values of the descendants and compared everyone against that ancestor. Of course, this is a bit skewed because we have several descendants of Silvester’s line through Abraham and only one descendant of Robert through Matthew.

The reconstructed or triangulated ancestral value is shown in green, at the top, and the results that don’t match that value are highlighted. I can’t show all 111 markers here, but enough that you get the idea. You can see all of the Estes STR test results on the Estes DNA project page.
Comparing against the recreated ancestor, Matthew’s descendant, kit 166011, only has 7 mutations difference from our recreated Estes Y ancestor. At 111 markers, this averages out to about one STR mutation every 1.5-2 generations.
The chart below shows Matthew’s descendant kit, 166011, compared to all of Abraham’s descendants. Matthew’s descendant, of course, is the kit furthest genealogically from Abraham’s descendants.
The number in the intersecting cells shows the number of mutations at both 67 and 111 markers compared to kit 166011.
| Kit Numbers | 9993 | 13805 | 244708 | 366707 | 199378 |
| 166011 at 67 | 6 | 6 | 6 | 6 | 5 |
| 166011 at 111 | 10 | 10 | 11 | 11 | No test |
When compared to each other, and not the ancestral values, kits 244708 and 366707 are not shown as matches to kit 166011 at 111 markers at Family Tree DNA, but are at 67 markers. When possible, I match participants to a recreated ancestor (on my spreadsheet) as opposed to matching to each other within a surname project, because it gives us a common starting point, providing a more realistic picture of how the DNA mutated to be what it is today in each line.
The Kent Estes Y DNA falls within haplogroup R-L21. From Eupedia, here’s a map of where haplogroup R-L21 is found.

L21 is known for being Celtic, not Germanic, meaning not the same as Franks and Suebi. Scholars are not unified in their interpretation of the maximum influence of the Celts. Some show no influence at all in Italy, some show a slight eastern coastal influence and this genetic maps shows a Sicilian influence.
However, because nothing in genealogy can every be straightforward, and people are always migrating from place to place, there is one known exception.
According to Barry Cunliffe’s book, “The Celts, a Very Short Introduction”, in 391 BC Celts “who had their homes beyond the Alps streamed through the passes in great strength and seized the territory that lay between the Appennine mountains and the Alps” according to Diodorus Siculus. The Po Valley and the rest of northern Italy (known to the Romans as Cisalpine Gaul) was inhabited by Celtic-speakers. While Este is somewhat north of this region, Este history indicates that there were fights with the Celts and then assimilation to some extent, so all is not entirely black and white.
The descendants of these invading Celts, having inhabited Italy for approximately 2500 years would be expected, today, to have some defining mutations that would differentiate them from their more northern European kinsmen and they would form a cluster or subgroup, perhaps a sub-haplogroup.
However, if the d’Este family was from the Mainz region of Germany, then Celtic influence in the Po Valley is irrelevant to their Y DNA. Unfortunately, because this history is cast in warm jello, at best, we need to consider all possibilities.
The various haplogroup project administrators are working very hard to analyze all of the Big Y results within their haplogroup projects and to make sense of them. By making sense of them, I mean in regards to the haplogroup and haplotree as a whole, not as individuals. The point of individual testing is to provide information that citizen scientists can utilize to flesh out the haplotree, which in turn fleshes out the history of our ancestors. So it’s a symbiotic relationship.
The Y DNA haplotree has gone from about 800 branches to 12,000 branches with the announcement of the Genographic 2.0 test in July of 2012 to over 35,000 SNPs that the Big Y is compared against. And that doesn’t count the thousands of new SNPs discovered and yet unnamed and unplaced on the tree.
This scientific onslaught has been termed the “SNP tsumani” and it truly is. It’s one of those wonderful, terrible, events – simply because there is so much good information it overwhelms us. Fortunately, the force of the tsunami is somewhat mitigated by the fact that the haplotree is broken into haplogroups and subgroups and many volunteer administrators are working feverishly to assemble the results in a reasonable manner, determining what is a leaf, a twig and a branch of the tree.
Mike Walsh is one of the administrators who maintains the L21 project and tree and has been extremely helpful in this process, providing both guidance and analysis. The project administrators have access to the results of all of the project participants, something individuals don’t have, so the project administrator’s assistance and perspective is invaluable. We’d be lost without them
Mike has created an extended tree of the R-L21 haplogroup

The Estes men are here, in the DF49 group indicated by the red arrow.
The Estes men have tested positive for SNPs which include:
- L21
- DF13
- DF49
Downstream, meaning closer in time to us, the haplogroup DF49 project administrator, Peter M. Op den Velde Boots, has created a tree rooted from the DF49 mutation.
I’m pleased to say that we are on that tree as well, towards the right hand side. The ZP SNPs on this tree are placeholder names created by the administrator so he could create a tree until an official name is issued for Z SNP locations.

The interesting thing is that Mike Walsh had predicted that both the Estes and a few other surnames would fall into a common subgroup based on our unusual values at three different STR markers:
- 460<=10
- 413=23,24
- 534>=17
Surnames that fell into Mike’s cluster based on Y STR marker values include:
- Gallagher (Ireland)
- Churchville (Ireland)
- Killeen/Killian (Ireland)
- Hall (England)
- Mahon (Ireland)
- Estes (England)
We’re seeing a lot of Irish names, and Ireland was settled by Celtic people.
Initially, the Estes men matched each other fairly closely, but had many differences from any other individuals who had tested. I have bolded the Matthew descendant kit that is the furthest from the other men who descend from Abraham.
SNP Differences With Other Estes Men
| John 244708 | Edward 13805 | Garmon 9993 | Emory III366707 | Howard 166011 | Dennis 199378 | |
| John 244708 | x | 1 (Z2001) | 0 | 2 (Z2001, F1314) | 1 (Z2001) | 2 (Z2001, PF682) |
| Edward 13805 | 1 (Z2001) | x | 0 | 1 (F1314) | 0 | 0 |
| Garmon 9993 | 0 | 0 | x | 1 (F1314) | 0 | 0 |
| Emory III 366707 | 2 (Z2001, F1314) | 1 (F1314) | 1 (F1314) | x | 1 (F1314) | 1 (F1314) |
| Howard 166011 | 1 (Z2001) | 0 | 0 | 1 (F1314) | x | 0 |
| Dennis 199378 | 2 (Z2001, PF682) | 0 | 0 | 1 (F1314) | 0 | x |
SNPs are haplogroup subgroup defining mutations. SNPs with a number assigned, as shown above, prefixed by a capital letter, means that the SNP has been registered and the originating letter indicates the lab in which it was found. SNPs discovered in Big Y testing are prefixed by BY for example.
Not all SNPs with numbers assigned have been placed on the haplogroup tree, nor will they all be placed on the tree. Some may be determined to be private or personal SNPs or not widespread enough to be of general interest. One certainly doesn’t want the tree to become so subdivided that family members with the same surname and known ancestor wind up in different haplogroups, appearing to not be related. Or maybe we have to redefine how we think of a haplogroup.
Case in point, these men with known, proven common Estes ancestors have differences on three SNPs, shown in the columns, below.
Estes Men Unique SNP Mutations
| Z2001 | F1314 | PF682 | |
| John 244708 | Yes | No | Yes |
| Garmon 9993 | ? | No | ? |
| Edward 13805 | No | No | ? |
| Emory III 366707 | No | Yes | ? |
| Dennis 199378 | No | No | No |
| Howard 166011 | No | No | ? |
What does this mean?
This means that John has developed two SNP mutations that none of the other Estes men have, unless some of the men with no-callls at that location, indicated by a ?, have that mutation. The common ancestor of all of the Estes participants except Howard is Abraham Estes, so SNP Z2001 and PF682 have occurred in John’s line someplace since Abraham.
PF682 is quite interesting in that two Estes men, both descendants of Abraham did have results for this location, one with an ancestral value (Dennis) and one with a derived, or mutated, value (John.) What is so interesting is that the four other men had ambiguous or unclear results at this location. In this case, I would simply disregard this SNP entirely since the results of reading this location seem to be unreliable.
Emory III, also a descendant of Abraham has developed a mutation at location F1314.
In these cases, these SNPs would fall into the category of line marker mutations that are found in that family’s line, but not in the other Estes lines. These are similar to STR line marker mutations as well.
The next type of SNP mutation reported in the Big Y results are called Novel Variants. Novel Variants are SNPs that haven’t yet been named, because they have just recently been discovered in the past few months in the testing process. The Big Y test compares everyone against a data base of 36,288 known SNPs. The balance of mutations found, called novel variants, are discoveries in the testing process.
Shared Novel Variants Between Estes Men
| John 244708 | Edward 13805 | Garmon 9993 | Emory III 366707 | Howard 166011 | Dennis 199378 | |
| John 244708 | x | 88 | 84 | 89 | 89 | 84 |
| Edward 13805 | 88 | x | 84 | 88 | 89 | 85 |
| Garmon 9993 | 84 | 84 | x | 83 | 84 | 81 |
| Emory III 366707 | 89 | 88 | 83 | x | 89 | 87 |
| Howard 166011 | 89 | 89 | 84 | 89 | x | 86 |
| Dennis 199378 | 84 | 85 | 81 | 87 | 86 | x |
In essence, the Estes family has 30 differences from the DF49 base. Translated, that means that in essence, our Estes family line broke away from the DF49 parent haplogroup about twice as long ago as the infamous M222 subclade named after Niall of the Nine Hostages. So, our ancestor was the ancestor of Niall of the Nine Hostages too, some 4000 years or so ago.
Finally, a Gallagher male tested, and the Gallagher and Estes families share a block of DNA that no one else shares that is comprised of 18 different individual mutations. As these things go, this is a huge number.
The numbers below are “addresses” on the Y chromosome because SNP names have not yet been assigned. The first letter listed is the ancestral value and the second is the mutated value found in the Estes/Gallagher combined group.
- 07457863-C-T
- 07618400-G-A
- 07738519-G-A
- 07956143-A-G
- 08432298-A-G
- 14005952-AATAAATAA-A
- 14029772-C-T
- 15436998-C-T
- 15549360-A-C
- 16286264-C-T
- 17833232-TT-T
- 18417378-G-A
- 18638729-A-G
- 19402586-G-A
- 22115259-T-C
- 22445270-G-A
- 22445271-A-G
- 23560522-G-A
This DNA will very likely define a new subclade of haplogroup R and has been submitted to obtain SNP names for these mutation locations for the Estes/Gallagher subclade. Unfortunately, they will not call it the Estes/Gallagher subclade, but we can for now:)
The Estes line still shares another dozen SNPs between themselves that are not yet shared by any other surname. At this point, those are considered family SNPs, but if others test and those SNPs are found outside the Estes family, they too will receive SNP names and become a new subclade.
So how long ago did all of this happen? When did we split, genetically, from the people who would become the Gallaghers?
The estimates for the number of average years per SNP creation vary, but range from 110 to 170. Utilizing this range, when comparing how long ago the Gallagher and the Estes family shared a common ancestor, we find that our common ancestor lived between 1320 and 2040 years ago. What we don’t know is whether that ancestor lived on continental Europe or in the British Isles. Certainly, this was before the adoption of surnames.
Another interesting aspect of this testing is that the Estes and Gallagher families don’t match above 12 markers, but they do match at 12 markers with one mutation difference. If the Estes and Gallagher participants weren’t in the same haplogroup project, they wouldn’t even see this match since they do have 1 difference at 12 markers and only exact 12 marker matches are shown outside of projects. This shows that sometimes very basic STR testing can reach far back in time if (multiple) mutations haven’t occurred in those first 12 markers.
I was interested to check the TIP calculator to see how closely in terms of generations the calculator expected the common ancestor to be at the 50th percentile, meaning the point at which the common ancestors is equally as likely to be earlier as later. The calculator indicated that 17 generations was at the 50th percentile, so about 425 to 510 years ago, allowing 25-30 years per generation. At 24 generations, or 600-720 years, which is as far as the calculator reaches, the likelihood of a common ancestor was still only at 68% and the TIP calculator would reach the 100th percentile at about the 34th generation, or 850-1020 years – if it reached that far.
It’s interesting to compare the results of the two tools. Both agree that the common ancestor is far back in time, and extrapolating now, very likely before the advent or surnames. The SNP estimate of 1320-2040 does not overlap with the STR estimate of 850-1020 – although in all fairness, a 12 marker TIP estimate is expecting a lot in terms of this kind of extrapolation.
After the Gallagher and Estes lines split, probably between 1300 and 2000 years ago, or between 700AD and the time of Christ, did the Estes men then find their way to Italy by the year 900 when the d’Este family is unquestionably found in Italy, and back again to Europe before we find Nicholas in Kent in 1495AD? It’s possible, but quite unlikely. We also have found absolutely no DNA, either utilizing STR markers or SNPs that suggest any connection with any line in or near Italy.
The Estes line is and was unquestionably L21, a haplogroup closely allied with the Celts for the past 4,000 to 5,000 years, with no indication of an Italian branch. Unless very unexpected new data arises, I think the Estes family can put the d’Este family story away, at least as far as cold storage – unless new data arises in the form of a proven male Y-line d’Este descendant testing or matching Italian L21 DNA participants.
As it turns out, the DNA was simply the final blow to the d’Este story. As I worked with English and European historical records, and in particular records of wealthy nobles and lesser nobles, I came to realize that children were an asset of the families to be married off for political and social favor. This sounds terrible by today’s cultural standards, but by the standards of the times in which our ancestors were living, politically advantageously arranged marriages were the best way to provide for your children’s well-being as well as your own. What this means to us is that no royal d’Este family member would ever have fallen into the working, peasant class. Even if they weren’t loved or even liked, they were still valuable and would simply have been married off far away. Our Estes family was a group of hard-working mariners in Deal, certainly not nobility. And now we know, they were Celts in Europe before they were Deal mariners.
Our more realistic claim to royalty, albeit very distant, lies in the fact that our ancestors were also the ancestors of the Irish King, Niall of the Nine Hostages, King of Tara who died about the year 405 and was the progenitor of the Ui Neill family that dominated Ireland from the 6th to the 10th centuries. Niall of the Nine Hostages and his descendants were very prolific, with about 3 million people being descendants. This means that the Estes family is distant cousins to just about everyone. It indeed, is a very small world, made smaller by the connections we can now make via DNA.

______________________________________________________________
Disclosure
I receive a small contribution when you click on some of the links to vendors in my articles. This does NOT increase the price you pay but helps me to keep the lights on and this informational blog free for everyone. Please click on the links in the articles or to the vendors below if you are purchasing products or DNA testing.
Thank you so much.
DNA Purchases and Free Transfers
- Family Tree DNA
- MyHeritage DNA only
- MyHeritage DNA plus Health
- MyHeritage FREE DNA file upload
- AncestryDNA
- 23andMe Ancestry
- 23andMe Ancestry Plus Health
- LivingDNA
Genealogy Services
Genealogy Research
- Legacy Tree Genealogists for genealogy research